Problem
While installing SQL Server or creating databases and tables, we often run with the defaults. In most cases, that’s not a bad thing. However, when it comes to setting the COLLATION, we again often run with the default settings. For a lot of DBA’s, we don’t change those options because we simply don’t understand what the different parts are and how they impact SQL Server.
Solution
We are going to break down the different parts of the COLLATE clause and give meaning to each part so you can better understand, and optionally tweak the clause to better suit your needs.
Breaking Down and Understanding the SQL Server Collation Setting
A quick look at a typical COLLATE clause that would be installed with English as the default language on a computer which is SQL_Latin1_General_CP1_CI_AS, so what does this mean?
Breaking it down into parts starting with the SQL_Latin1_General section we first need to understand that this is going to reference a “code page” or more appropriately a “Unicode table”. Microsoft has created a small collection of these code pages, each setting the character set and sort order based on different languages.
There is a different code page for each language. For example, code page 1252 is for English, 1255 is for Hebrew and so on. The first 128 lines of code are the same for all the pages; the remaining lines of code differentiate the special character needs based on that particular language. You can use the following SQL query to return a complete list of collation page references.
SELECT name, COLLATIONPROPERTY(name, 'CodePage') AS Code_Page, description
FROM sys.fn_helpcollations()
ORDER BY name;
Generally, you will not need to know the contents of these files and you certainly don’t want to attempt changing them. But, for curiosity sake, if you want to review them, they can be found at the following link.
Moving on to the next section of the collate clause, we have some arguments separated by an underscore. The table below lists the possible arguments in the left column with a general description in the right column.
| CS | Case sensitive or CI for case insensitive |
| AS | Accent sensitive or AI for accent insensitive |
| KS | Kana type-sensitive or if this set is missing then Kana type-insensitive |
| WS | Width sensitive or if this set is missing then width insensitive |
| VSS | Variation selector sensitive (not available in all versions) if missing, then VSS insensitive |
| _SC | Supplementary Character Support. (This one is optional). |
SQL Server Collation Settings Abbreviations and Definitions
Defining the above table in more detail:
“CS” / “CI” – Obviously, this one is just case sensitivity between upper and lower case. The default during SQL Server install as well as a database creation is “case insensitive”. With case-insensitive, your queries will execute equally whether you use upper or lower case or a combination of both. However, if you set this to case-sensitive, you will need to get the upper and lower case correct or the query will not return the expected results. Thus, in a “CS” case-sensitive collation, HumanResources.Department is different from humanresources.department and SQL treats them as two different objects.
“AS” / “AI” – This is referring to accent sensitivity. An example would be that 'a' is the same as 'á' if accent-insensitive is set (using “AI” instead of “AS”), but 'a' is not the same as 'á' if accent-sensitive is called.
“KS” – Most people will never see or use this one. KS or Kanatype distinguishes between the two types of “Kana” characters for Japan. Those are Hiragana and Katakana. If “KS” is present, SQL Server treats them as equal for sorting purposes.
“WS” – Width sensitive distinguishes between a single-byte character and a double-byte character. If “WS” is not set/selected, SQL Server treats the single-byte and double-byte characters as the same for sorting purposes.
“VSS” – Somewhat relating back to the “KS” or Kanatype, this too is referencing Japanese characters so you most likely will not see nor use this in your day to day activities.
“_SC” – This will always be at the end of the arguments. It only affects how built-in functions work with surrogate pairs. Without “_SC” at the end, SQL Server doesn’t see single supplementary characters; instead it sees two code points that make up a surrogate pair.
While this is not an exhaustive list of all the arguments for the COLLATE clause, it does provide a basic foundation for better understanding the fundamental parts.
COLLATE Sort Order Explained
Although you may have originally created your SQL Server installation in the US and just used the default setting of “Latin” for your collation on the server level, you can set a different collation for your tables and views that you know will be accessed by co-workers in different countries.
Here’s a simple example:
First, let’s create a test database that we can drop when we finish testing.
USE master;
GO
CREATE DATABASE testAndDump;
GO
Now, let’s switch to that database and create a table called “Locations”.
USE testAndDump;
GO
CREATE TABLE Locations(
colID INT IDENTITY
, city VARCHAR(40)
, country VARCHAR(40)
);
GO
Normally we would just add some basic data to the table such as cities within the United States (if that’s the country you live in). However, remember that we are a small business that expanded into Mexico and Chile.
With that said, let’s insert some data into our “Locations” table that includes cities from all three countries.
INSERT INTO Locations(city, country)
VALUES('Chiapas', 'Mexico')
, ('Colima', 'Mexico')
, ('Cinco Rios', 'Chile')
, ('Camden', 'USA');
GO
Here’s where the problem arises. A Spanish collation will sort the data in a different order than that of a Latin collation. Run these two SELECT statements to see the results. Look closely at the results from each one. Notice that they are returned in two different sort orders.
SELECT
city
, country
FROM Locations
ORDER BY city
COLLATE Latin1_General_CS_AS_KS_WS ASC;
GO
SELECT
city
, country
FROM Locations
ORDER BY city
COLLATE Traditional_Spanish_CI_AI ASC;
GO
Here are the results.
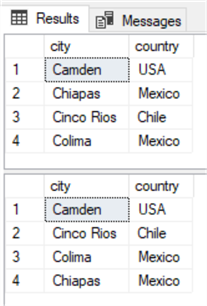
The big difference here is that “Chiapas” comes before “Cinco Rios” in the Latin collation, but it comes at the end on the “Spanish” collation.
Notice that we specified the collation on the table level by adding it after the “ORDER BY” clause. You could also apply the collation to individual columns instead of the whole table or you can apply the collation to the entire database.
And of course, you can create views based on these SELECT statements for your foreign co-workers to access so they will see the sort order that they are accustomed to.
More Tips on Collate
In the previous section we saw how to set the collation on the entire SELECT statement, so, here’s an example of setting the collation on a specific column(s) in a SELECT statement.
Setting Collate for a specific column in a SQL Server query
SELECT
city COLLATE Traditional_Spanish_CI_AI
, country
FROM Locations2
ORDER BY city;
GO
Setting Collate for a specific column when creating a table in SQL Server
And you can do this to set the collation at the table level when creating a table.
CREATE TABLE Locations( colID INT IDENTITY
, city VARCHAR(40)
, country VARCHAR(40)
COLLATE Traditional_Spanish_CI_AS
);
GGGO
Setting Collate when creating a SQL Server database
And finally, setting the collation at the database level.
CREATE DATABASE testAndDumpOLLCOLLATE Traditional_Spanish_CI_AI;
GO
Next Steps
Check out these related articles.
- Case Sensitive Search on a Case Insensitive SQL Server
- Understanding the COLLATE Database Default
- How column COLLATION can affect query performance
- COLLATION and Code Pages

Aubrey Love is a self-taught DBA with more than six years of experience designing, creating, and monitoring SQL Server databases as a DBA/Business Intelligence Specialist. Certificates include MCSA, A+, Linux+, and Google Map Tools with 40+ years in the computer industry. Aubrey first started working on PC’s when they were introduced to the public in the late 70’s.
- MSSQLTips Awards: Author of the Year – 2022 | Trendsetter (25+ tips) – 2023