By: Aaron Bertrand | Comments | Related: 1 | 2 | 3 | 4 | > Compression
Problem
Databases are getting bigger. You might argue that hard disks are getting bigger also; however (and putting Solid State Drives out of the equation for the moment) they are not getting faster. In fact most systems today, even those on big expensive SANs and other highly scalable disk subsystems, are I/O-bound rather than CPU- or memory-bound. To compound the problem, we have to support Internationalization -- meaning we need to use NVARCHAR columns to support Unicode data, even if most of our column values only contain ASCII characters -- leading to much wasted space and, more importantly, I/O that is much heavier than necessary.
Solution
Using data compression in SQL Server 2008 R2, not only can we benefit from row (storing fixed-length data as variable-length) and page (adding prefix and dictionary) compression, but we can also observe that ASCII characters will only occupy a single byte even in NCHAR and NVARCHAR columns - only those characters that require two bytes will actually use them. On systems where Unicode data is the exception rather than the rule, this can represent a significant and dramatic difference in both storage and performance.
Using a very simple example for illustration, let's say we have the following table:
CREATE TABLE dbo.Uncompressed ( data NVARCHAR(255) );
In order to test data compression, I'll need to populate that table with realistic data. Typically I'll use catalog views such as sys.tables or sys.columns to populate dummy data; in this case, I happened to have a nice round number of rows in sys.objects (60), so in order to create a sample case where 25% of the data contained Unicode characters, I created 20 additional tables with names like:
CREATE TABLE dbo.[åöéäåååbar](a INT); CREATE TABLE dbo.[xxöööéäå](a INT); CREATE TABLE dbo.[xxöåéäå](a INT); ...
Then to ensure that the data would be inserted into both my compressed and uncompressed tables in the same order (so that both tables would be storing the exact same data), I populated the following #temp table with 512,000 rows (using MAXDOP 1 to prevent parallelism from changing the sorting and identity assignment):
CREATE TABLE #tempdata ( i INT IDENTITY(1,1), data NVARCHAR(255) ); INSERT #tempdata(data) SELECT s1.name FROM sys.objects AS s1 CROSS JOIN sys.objects AS s2 CROSS JOIN sys.objects AS s3 ORDER BY NEWID() OPTION (MAXDOP 1); GO
Now I could populate my uncompressed table, and run a preliminary test against it:
INSERT dbo.Uncompressed(data) SELECT data FROM #tempdata ORDER BY i OPTION (MAXDOP 1);
My only real tests would be: how long does this take, and what kind of compression does the engine predict I will be able to achieve on this table? The INSERT took an elapsed time of 2.899 seconds (1.594 seconds of that was CPU time). You can estimate the compression ratio by using the system stored procedure sys.sp_estimate_data_compression_savings:
EXEC sys.sp_estimate_data_compression_savings @schema_name = 'dbo', @object_name = 'Uncompressed', @index_id = 0, @partition_number = 1, @data_compression = 'PAGE';
The results indicated that I should get a compression ratio of about 64%:
The question is, since the stored procedure bases its estimates on a small sample, would I get that same ratio when I actually applied compression? Well there is an easy way to test; I could create a second table, and then insert the same data:
CREATE TABLE dbo.Compressed ( data NVARCHAR(255) ) WITH (DATA_COMPRESSION = PAGE); GO INSERT dbo.Compressed(data) SELECT data FROM #tempdata ORDER BY i OPTION (MAXDOP 1);
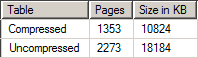
As you might expect, this operation took longer; total elapsed time was 5.291 seconds (2.062 seconds of CPU time). We also find that the space we saved was not quite as pronounced as the system procedure estimated; the actual space savings in this case came out to about 40%. I checked this by running the following query:
SELECT [Table] = OBJECT_NAME([object_id]),
[Pages] = reserved_page_count,
[Size in KB] = reserved_page_count*8
FROM sys.dm_db_partition_stats
WHERE OBJECT_NAME([object_id]) IN ('Compressed', 'Uncompressed')
AND index_id = 0;With the following results:
So far we see that we can save a dramatic amount of space, but write times are adversely affected. What about read times? For brevity, let's just test a full scan of the table, and see how much longer it takes to decompress and read the compressed data, vs. reading the uncompressed data directly:
SET STATISTICS TIME ON; SELECT [data] FROM dbo.Compressed; SELECT [data] FROM dbo.Uncompressed; SET STATISTICS TIME OFF;
The results:
SQL Server Execution Times: CPU time = 484 ms, elapsed time = 4015 ms. SQL Server Execution Times: CPU time = 312 ms, elapsed time = 3943 ms.
So, there is significant CPU cost to reading and decompressing the compressed data, but and due to lower I/O (~1,300 logical reads vs. ~2,200), it does not impact overall duration as much as you might expect. Keep in mind that this was an isolated and virtualized system with a suboptimal I/O subsystem; in better-tuned environments, the duration may very well swing the other way.
All of which just reminds us that nothing is free, and compression / decompression will certainly take a CPU toll on certain operations. But on systems where you're already I/O-bound, you may be better off paying a CPU performance hit in order to reduce I/O. In addition, since data is kept compressed in the buffer pool (and only decompressed when it is read), you will find that your memory requirements will decrease as well, meaning you will be able to get more data into memory without actually adding RAM. When asking yourself if data compression is right for you, just keep in mind this important point: As with all architectural changes, "it depends" - you will need to gauge the feasibility of this feature, given your hardware, data, workload and usage patterns.
Note that there are two important limitations of Unicode compression that I feel cannot be ignored. One is that it does not support the NVARCHAR(MAX) data type; only NCHAR and NVARCHAR <= 4000. Another is that you cannot enable page or row compression without also enabling Unicode compression (it does not have its own setting).
Next Steps
- Identify tables where you are using Unicode data only sparingly.
- Test the impact of data compression on those tables, starting with the sys.sp_estimate_data_compression_savings stored procedure.
- Implement data compression in a test system where you can perform regression and load testing.
- Implement data compression if your regression tests prove that it is beneficial.
- Review the following tips and Books Online topics:
- Implementing Data Compression in SQL Server 2008
- Data Compression Using the SQL Server Vardecimal Storage Format
- Creating Compressed Tables and Indexes
- Unicode Compression Implementation
- sp_estimate_data_compression_savings (Transact-SQL)
- Data Compression: Strategy, Capacity Planning and Best Practices






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
