By: Matteo Lorini | Comments (3) | Related: > Performance Tuning
Problem
When running queries SQL Server may not always use the correct statistics to determine the best optimization for a query plan. This could be a performance hit for complex queries and have correct statistics is key to the optimizer. In this tip we look at how filtered statistics can improve query optimization.
Solution
One of the new features that was introduced with SQL 2008 is called Filtered Statistics. This is the definition from BOL "Filtered statistics can improve query performance for queries that select from well-defined subsets of data. Filtered statistics use a filter predicate in the WHERE clause to select the subset of data that is included in the statistics."
Let us show how we can use filtered statistics with an example. The below code creates a table and inserts some data into the table. The code for this tip was adopted with permission from an article by Jack Li.
CREATE TABLE MyRegionTable(id INT, Location NVARCHAR(100), USState CHAR(2))
GO
CREATE TABLE MySalesTable(id INT, detail INT, quantity INT)
GO
CREATE CLUSTERED INDEX IDX_d1 ON MyRegionTable(id)
GO
CREATE INDEX IDX_MyRegionTable_name ON MyRegionTable(Location)
GO
CREATE STATISTICS IDX_MyRegionTable_id_name ON MyRegionTable(id, Location)
GO
CREATE CLUSTERED INDEX IDX_MySalesTable_id_detail ON MySalesTable(id, detail)
GO
INSERT MyRegionTable VALUES(0, 'Atlanta', 'GA')
INSERT MyRegionTable VALUES(1, 'San Francisco', 'CA')
GO
SET NOCOUNT ON
-- MySalesTable will contain 1 row for Atlanta and 1000 rows for San Francisco
INSERT MySalesTable VALUES(0, 0, 50)
DECLARE @i INT
SET @i = 1
WHILE @i <= 1000 BEGIN
INSERT MySalesTable VALUES (1, @i, @i*3)
SET @i = @i + 1
END
GO
UPDATE STATISTICS MyRegionTable WITH fullscan
UPDATE STATISTICS MySalesTable WITH fullscan
GO
Before we run the following queries turn on "Include Actual Execution Plan" and run the following query for Atlanta.
-- this query will over estimate
-- its estimate will be 500.5 rows, but should be 1 row
SELECT detail FROM MyRegionTable JOIN MySalesTable ON MyRegionTable.id = MySalesTable.id
WHERE Location='Atlanta' OPTION (recompile) Even if we have only 1 row containing the Atlanta location, the optimizer over estimates and uses a value of 500.5 as shown below.
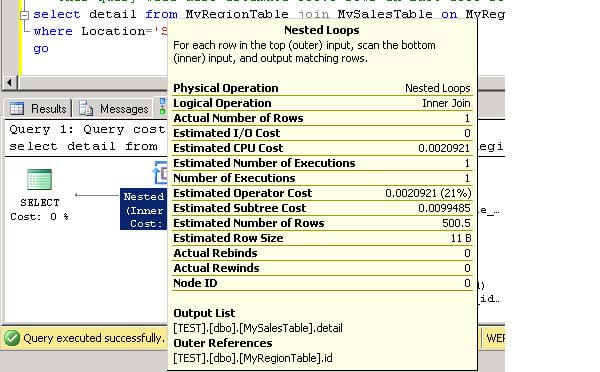
Now, let's run the following query for San Francisco.
-- this query will under estimate
-- its estimate is also 500.5 rows, but should be 1000 rows
SELECT detail FROM MyRegionTable JOIN MySalesTable ON MyRegionTable.id = MySalesTable.id
WHERE Location='San Francisco' OPTION (recompile)
In this case, the optimizer, under estimates the number of rows. It is interesting to note that we only have two values for the locations and 1001 rows in total and in both queries the optimizer estimate is 500.5 rows.
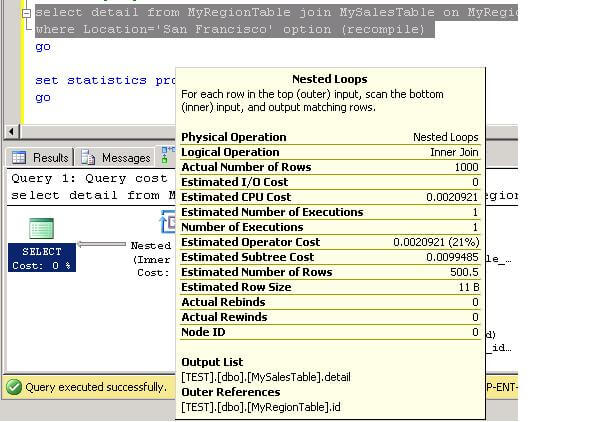
Let's create our filtered statistics using the below code.
CREATE STATISTICS MyRegionTable_stats_id ON MyRegionTable (id)
WHERE Location = 'Atlanta'
GO
CREATE STATISTICS MyRegionTable_stats_id2 ON MyRegionTable (id)
WHERE Location = 'San Francisco'
GO
The image below shows that the filtered statistics have been created.
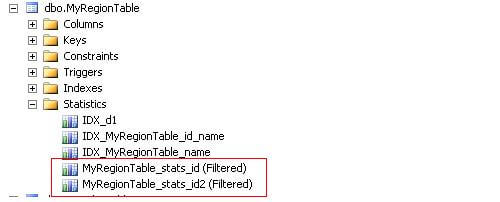
Let's run the same queries one more time.
SELECT detail FROM MyRegionTable JOIN MySalesTable ON MyRegionTable.id = MySalesTable.id
WHERE Location='Atlanta' OPTION (recompile) We can now see that the estimated number of rows returned is now correct.
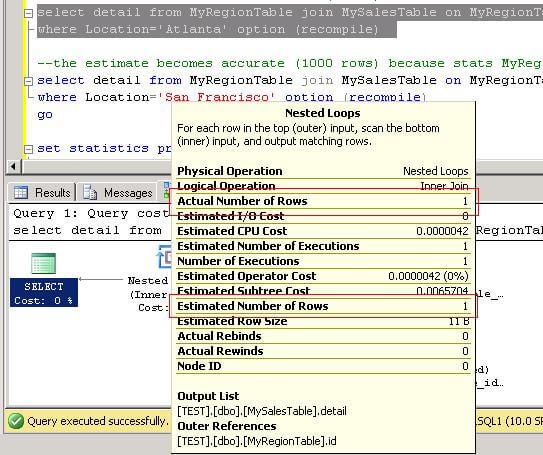
Let's run the same query again for San Franciso.
SELECT detail FROM MyRegionTable JOIN MySalesTable ON MyRegionTable.id = MySalesTable.id
WHERE Location='San Francisco' OPTION (recompile)And it is also correct for this query as well.
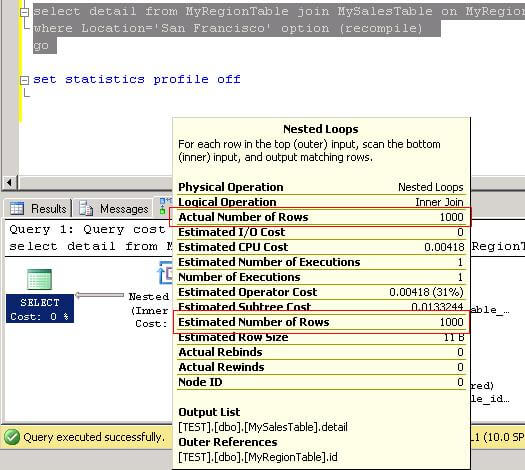
This example shows how filtered statistics can help when the query plan is generated. By having the correct values SQL Server can make better optimization choices and therefore improve query performance.
Next Steps
- Read these related tips:






About the author
 Matteo Lorini is a DBA and has been working in IT since 1993. He specializes in SQL Server and also has knowledge of MySQL.
Matteo Lorini is a DBA and has been working in IT since 1993. He specializes in SQL Server and also has knowledge of MySQL.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
