Problem
At one point you may have been advised to use the REMOTE join hint when using queries across SQL Server linked servers. You may have even observed substantial performance gains by specifying this join hint; if the local table had a small number of rows, and the remote table is significantly larger, you would expect the result of the hint (which tells SQL Server to process the join remotely) to lead to a better overall query. But unless those systems are still running the same version of SQL Server, what worked well once may not be working so well today. Check out this tip to learn more.
Solution
Over the past week I have played with various local table sizes and very large remote data sources (both permanent tables and derived tables). I would expect these to be areas for the REMOTE hint to shine, since they are right in that hint’s wheelhouse: small, local tables that make more sense to push to the remote server instead of trying to join over the wire. The result was actually the opposite in all cases: the REMOTE hint caused a substantial performance hit. I built these simple tables locally, on a SQL Server 2012 instance:
CREATE TABLE dbo.blab_key(id INT PRIMARY KEY); GO CREATE TABLE dbo.blab_heap(id INT); GO — four rows that are valid object_ids in remote system INSERT dbo.blab_key VALUES(-649911850),(-480106018),(-303587480),(-448); INSERT dbo.blab_heap VALUES(-649911850),(-480106018),(-303587480),(-448);
Then I wrote queries like these, joining the IDs to both fabricated and permanent tables on remote 2005 and 2012 instances:
— standard inner joins: SELECT * FROM splunge.dbo.blab_key AS k INNER JOIN [remote_server].tempdb.sys.all_objects AS o ON k.id = o.[object_id] INNER JOIN [remote_server].tempdb.sys.all_columns AS c ON o.[object_id] = c.[object_id]; SELECT * FROM splunge.dbo.blab_heap AS k INNER JOIN [remote_server].tempdb.sys.all_objects AS o ON k.id = o.[object_id] INNER JOIN [remote_server].tempdb.sys.all_columns AS c ON o.[object_id] = c.[object_id]; — REMOTE hint on initial join: SELECT * FROM splunge.dbo.blab_key AS k INNER REMOTE JOIN [remote_server].tempdb.sys.all_objects AS o ON k.id = o.[object_id] INNER JOIN [remote_server].tempdb.sys.all_columns AS c ON o.[object_id] = c.[object_id]; SELECT * FROM splunge.dbo.blab_heap AS k INNER REMOTE JOIN [remote_server].tempdb.sys.all_objects AS o ON k.id = o.[object_id] INNER JOIN [remote_server].tempdb.sys.all_columns AS c ON o.[object_id] = c.[object_id]; — REMOTE hint on both joins: SELECT * FROM splunge.dbo.blab_key AS k INNER REMOTE JOIN [remote_server].tempdb.sys.all_objects AS o ON k.id = o.[object_id] INNER REMOTE JOIN [remote_server].tempdb.sys.all_columns AS c ON o.[object_id] = c.[object_id]; SELECT * FROM splunge.dbo.blab_heap AS k INNER REMOTE JOIN [remote_server].tempdb.sys.all_objects AS o ON k.id = o.[object_id] INNER REMOTE JOIN [remote_server].tempdb.sys.all_columns AS c ON o.[object_id] = c.[object_id];
Results as shown by SQL Sentry Plan Explorer:
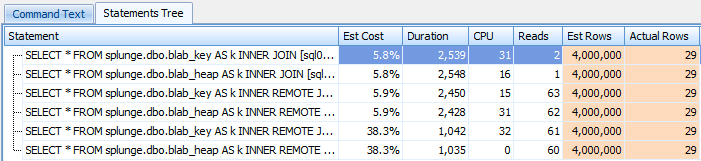
The results largely speak for themselves – the version with one REMOTE join performed marginally better in terms of duration (~3%), but had higher reads. The query with two REMOTE joins was atrocious.
And then this slight variation, where I try to force a REMOTE join against the product of sys.all_objects and sys.all_columns:
SELECT * FROM splunge.dbo.blab_key AS k INNER JOIN ( SELECT o.[object_id] FROM [remote_server].tempdb.sys.all_objects AS o CROSS JOIN [remote_server].tempdb.sys.all_columns AS c ) AS o ON k.id = o.[object_id]; SELECT * FROM splunge.dbo.blab_heap AS k INNER JOIN ( SELECT o.[object_id] FROM [remote_server].tempdb.sys.all_objects AS o CROSS JOIN [remote_server].tempdb.sys.all_columns AS c ) AS o ON k.id = o.[object_id]; SELECT * FROM splunge.dbo.blab_key AS k INNER REMOTE JOIN ( SELECT o.[object_id] FROM [remote_server].tempdb.sys.all_objects AS o CROSS JOIN [remote_server].tempdb.sys.all_columns AS c ) AS o ON k.id = o.[object_id]; SELECT * FROM splunge.dbo.blab_heap AS k INNER REMOTE JOIN ( SELECT o.[object_id] FROM [remote_server].tempdb.sys.all_objects AS o CROSS JOIN [remote_server].tempdb.sys.all_columns AS c ) AS o ON k.id = o.[object_id];

And here we see similar results – the REMOTE join performs poorly compared to a join without the hint, and look at the reads incurred for the REMOTE join with the heap, even with a slightly lower duration that has to be a concern, especially if you have an inferior or overloaded I/O subsystem.
You’re probably thinking, well, those aren’t really tables, and yes, you’re mostly right. I listed what I used here to make it much easier to test, but I confirmed very similar behavior against very large tables that I constructed myself. I also tried variations where, instead of SELECT *, I used individual columns from both sides. Results were consistent across all of these tests: INNER JOIN performed better than INNER REMOTE JOIN in almost all tests, and was only beaten marginally in one single test as shown above.
Conclusion
As you can see, the REMOTE join hint does not seem to perform as well as the documentation would lead you to believe – at best it performs the same as leaving the hint out, depending on how you measure. You may have old code that has been upgraded to modern versions that isn’t performing as well as it could be, and you may have been lulled – over the years – into believing that this join hint will always help these scenarios. I think join hints in general are very useful, but they can also be very dangerous if they’re used out of habit instead of for very narrow scenarios. So I strongly recommend you revisit any code that is currently using this hint, and test thoroughly before implementing it in any new development.
That said, I would, of course, be very interested to hear about any scenarios on modern versions of SQL Server (2008+) where an explicit REMOTE join yields better performance than an equivalent query without the hint (and by “better” I mean less reads *and* a duration different by more than a few percent).
Next Steps
- Identify code that uses the REMOTE join hint (this tip will help for stored procedures, but you’re on your own for ad hoc queries in your applications).
- Test the queries you find with and without the REMOTE keyword, and decide if you want to keep them that way.
- Review the following tips and other resources:

Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He also blogs at sqlblog.org.
- MSSQLTips Awards: Author of the Year – 2016, 2023 | Leadership (200+ tips) – 2022