Problem
You, as a SQL Server data professional, are looking for ways to improve your queries. You’ve done the usual – avoided cursors and loops, used locks effectively, examined execution plans – what else can you tweak? Check out this tip to learn more.
Solution
This tip is going to deal with JOIN hints. Most SQL Server data professionals are familiar with hints in one form or another, for example WITH (NOLOCK) or WITH (READPAST) when specifying dirty reads on a database object. However there are other hints we can use and here I’m going to explore the four hints that apply to JOINs – HASH, LOOP, MERGE and REMOTE – and how we can use them to optimize the JOINs in our queries and beat the optimizer.
Basic SQL Server JOIN Syntax and Operation
Firstly, a quick overview of JOINs for those readers who aren’t familiar with their use. There are five main types of JOINs – INNER, LEFT OUTER, RIGHT OUTER, FULL and CROSS. Note that LEFT and RIGHT OUTER are normally truncated to LEFT or RIGHT. An OUTER JOIN defaults to LEFT. The purpose of a JOIN is to gather information from one or more tables and return it from a single query. Imagine two fictional tables, dbo.CustomerRecords with column ‘Gender’ and dbo.SalesRecords with column ‘TotalSalePrice’. We may wish to return the average amount spent, grouped by gender, which would require information from both these tables. Here is one way to do it:
SELECT CASE cr.Gender
WHEN 0 THEN ‘Male’
WHEN 1 THEN ‘Female’
ELSE ‘Not known’
END [Gender],
ROUND(AVG(sr.TotalSalePrice),2) [Average_Sale_Price]
FROM dbo.Customer Records cry
INNER JOIN dbo.SalesRecords sr ON cr.CustomerID = sr.CustomerID
GROUP BY cr.Gender
ORDER BY cr.Gender
Results:
Gender Average_Sale_Price
——— ———————
Not known 724.03
Male 645.79
Female 615.87
This query returns the average amount spent by a customer grouped by gender. The INNER JOIN was used in this case to fetch the TotalSalePrice from SalesRecords and compare against the Gender from CustomerRecords. There are a couple of important points here – the INNER JOIN (indeed, all joins) uses the ON syntax to indicate the right-side table, and an equi-join operator (=) to specify on which columns the JOIN should occur.
A LEFT join returns all data on the left side of a join and all matching values on the right side (substituting NULL on the right for values not matched). A RIGHT join returns all data on the right side of a join (substituting NULL on the left for values not matched). A FULL join returns all data on both sides of the join substituting NULL on either side for unmatched values. A CROSS join (also referred to as a Cartesian join) returns all combinations of values on the left and right side of the joins and the total number of rows expected is the Cartesian product (*) of the numbers of rows on the left and right side of the join.
Because the focus of this article is using JOIN hints rather than explaining the types of JOIN (which is amply covered in other tips), I’ll move swiftly on to the type of JOIN hints we will encounter and I’ll use INNER joins for the examples. First, however, a word about the SQL Server query optimizer.
SQL Server Query Optimizer
The query optimizer is the internal set of components and services that, after parsing, analyze a query, checking the procedure cache to see if it’s already stored; formulate the most efficient method of executing a query; and both determine and build the most efficient execution plan. For the context of this tip, the query optimizer (when a join is specified) chooses the most efficient method of building the join, and this is what we will cover. Most of the time the optimizer will make the right decision – on occasion it can be improved.
As already stated, there are four types of join hints. The first is a HASH JOIN.
SQL Server Hash Joins
Hash joins are built using hash tables, which are assembled in-memory by SQL Server. The principle of a hash table is easy to understand; first, the smaller of the two tables is read and the keys of the tables together with the predicate on which the JOIN is based (the equi-join predicate, e.g. … ON a.id = b.id ) are hashed using a proprietary hash function, then put into a hash table. This is called the build phase. In the second phase, called the probe phase, each hash is read and compared against the computed hashes of the rows in the second table, with the output results segregated until the second table has been read in full. Finally, the output results are retrieved and presented as the query results.
Hash joins are efficient when comparing data that isn’t indexed or comparing a small data set against a larger one, simply because the algorithms used during the second phase will disregard an index if it exists, preferring instead to calculate the hash values and return the results. While the algorithms to do this are efficient, it’s worth noting that hash joins require an initial memory allocation and require that the build phase is completed before the probe phase begins and results can begin to be returned. Consequently, for very large tables and for tables with large row sizes, the hash tables may have to be flushed to disk and this can incur penalties for I/O, particularly when using non-SSD disk drives. This constraint also naturally limits the number of hash joins that can be stored in memory and executed at any one time – consequently, forcing a hash join in a frequently-used stored procedure in a typical OLTP can hinder rather than help query optimization.
SQL Server Remote Joins
The second type of join is a REMOTE join, and it’s simply a variation on the hash join. However, it’s designed for queries retrieving results from Linked Servers and other remote sources. Consider an example where you are hash JOINing on a 100,000-row table that’s resident in a database 1000 miles from your data center. If you are hash JOINing against a local 1,000,000-row table, the query optimizer has to build the hash table locally, then for each hash computation on the right-side table compare the hashed values and if a match is found, transfer the values across the network. This can quickly stack up, and cause both unnecessary network traffic and slower query execution times as the network bandwidth and quality constrains the query optimization. However by specifying REMOTE, the JOIN operation is conducted on the remote server, with the results being transmitted back to the calling instance. This means lower traffic and a faster return. Note that this join should only be used when the left table is smaller than the right table, where the right table is remote, where a hash join is an appropriate join, and for INNER joins only.
SQL Server Loop Joins
The third type of JOIN is a LOOP JOIN. This join operates differently from a hash join, in that it is best suited to a join on a small table to a larger one. The join is constructed in a nested fashion, i.e. the smaller table is ‘placed inside’ the larger one and each row from the outer table is compared against each row in the smaller table until all matches have been found:

Consequently these types of JOIN are very efficient when using a small table very frequently to sort data, however they can suffer in proportion to the size of the smaller table. Inner loop joins also come in a variety of types – a naive inner loop join, which is a comparison of every row in A to B; a temporary index inner loop join, where an index is created (b-tree) during joining which is discarded after use; and an index inner loop join, where a permanent index is used to optimize the loop join. Consequently good indexes on the tables can influence the decision of the query optimizer to select the loop join if it will complete more efficiently than a hash join.
SQL Server Merge Joins
The final join hint is the MERGE join, which is ideally suited to pre-sorted tables of similar size. The query optimizer will use a merging algorithm to compare the rows (similar to the ‘merge sort’ computer science principle). For each sorted row in A, it is compared to the equivalent sorted row in B. If duplicate rows exist on the left or right, the set (Cartesian product) of rows are compared before moving on, however in most cases the merge operation is a straightforward comparison rather than a many-to-many operation. This is an efficient way of joining with large data sets, especially those that are already pre-sorted (such as clustered indexes) using the join predicate.
Proof of Concept
Below, I’m going to demonstrate various examples of using these types of JOINs, with extracts from the query execution plans in an attempt to justify the points made above. I will skip the REMOTE join which is essentially a reformulation of the hash join. The inner join using a hash method is shown below. You will see the build code commented out if you would like to follow along.
–CREATE TABLE dbo.TableA (
— uqid INT UNIQUE,
— someVal FLOAT )
–CREATE TABLE dbo.TableB (
— uqid INT UNIQUE,
— someVal FLOAT )
–DECLARE @cnt INT
–SET @cnt = 1
–DECLARE @rnd FLOAT
–WHILE @cnt <= 100000
–BEGIN
— SET @rnd = ROUND((RAND() * 100),3)
— INSERT INTO dbo.TableA (uqid, someVal) VALUES (@cnt, @rnd)
— SET @rnd = ROUND((RAND() * 100),3)
— INSERT INTO dbo.TableB (uqid, someVal) VALUES (@cnt, @rnd)
— SET @cnt = @cnt + 1
–END
SELECT a.uqid [a_key], b.uqid [b_key], a.someVal [matching_val]
FROM dbo.TableA a INNER JOIN dbo.TableB b ON a.someVal = b.someVal

Here we can see that the query optimizer has chosen a hash join, as we have given two similar (in this case, identically) sized tables without pre-sorting or indexes, which precludes using an inner loop or merge join. This query completed in 5 seconds – let’s note the difference when we force the use of an INNER LOOP JOIN by specifying it explicitly:
–DBCC FREEPROCCACHE
SELECT a.uqid [a_key], b.uqid [b_key], a.someVal [matching_val]
FROM dbo.TableA a INNER LOOP JOIN dbo.TableB b ON a.someVal = b.someVal
For this query, the same results were returned but this time the execution time was so long I gave up running it at 14 minutes 43 seconds – based on the max results returned, I estimate it would have completed in about 45 minutes, meaning the hash join in this situation is 540 times more efficient than the loop join! The cost for the join (in terms of the overall query cost) rose so that this is the worst possible way of executing it:

Let’s modify our tables so that an INNER LOOP JOIN makes sense. Below I’m recreating TableA to have just 10 rows. The query optimizer should choose an INNER LOOP join as the most efficient option – without indexes, this is a naive inner loop join:
–TRUNCATE TABLE dbo.TableA
–DECLARE @cnt INT
–SET @cnt = 1
–DECLARE @rnd FLOAT
–WHILE @cnt <= 10
–BEGIN
— SET @rnd = ROUND((RAND() * 100),3)
— INSERT INTO dbo.TableA (uqid, someVal) VALUES (@cnt, @rnd)
— SET @cnt = @cnt + 1
–END
–DBCC FREEPROCCACHE
SELECT a.uqid [a_key], b.uqid [b_key], a.someVal [matching_val]
FROM dbo.TableA a INNER LOOP JOIN dbo.TableB b ON a.someVal = b.someVal
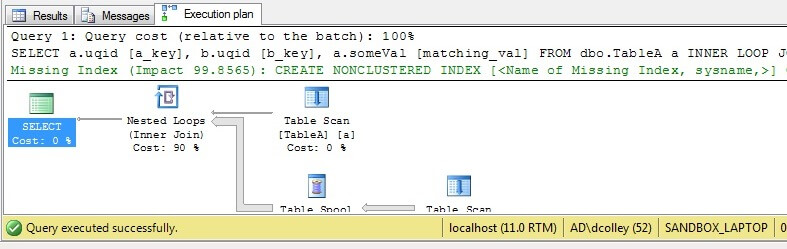
This time the INNER LOOP JOIN made perfect sense and the query executed in less than a second. We could further optimize this by adding an index. Let’s first see if the optimizer, without the explicit LOOP hint, picks the nested loop join as the most efficient method:

It does not – but the difference in performance is close, with this query also completing in less than a second. Let’s add an index (clustered) to each table on the someVal column to organize the data in the tables into a b-tree structure then rerun the query to see what happens:
CREATE CLUSTERED INDEX ix_TableA ON dbo.TableA(someVal)
CREATE CLUSTERED INDEX ix_TableB ON dbo.TableB(someVal)
EXEC sp_updatestats
DBCC FREEPROCCACHE
SELECT a.uqid [a_key], b.uqid [b_key], a.someVal [matching_val]
FROM dbo.TableA a INNER JOIN dbo.TableB b ON a.someVal = b.someVal

Here we can see that thanks to the presence of clustered indexes both sides of the join and the disparity in table sizes, the optimizer has picked the inner loop join method rather than use a hash join.
Let’s see if we can demonstrate a merge join instead. Remember that merge joins are suited to pre-sorted data – if an index doesn’t exist, the data is sorted in-memory and this shows in the execution plan too. Merge joins are good for similarly-sized tables. We will again redefine TableA with 100,000 rows, with the same clustered index and sp_updatestats executed (not shown). The Merge Join method should be picked since TableA and TableB are already sorted and the tables are of similar size.
–TRUNCATE TABLE dbo.TableA
–DECLARE @cnt INT
–SET @cnt = 1
–DECLARE @rnd FLOAT
–WHILE @cnt <= 100000
–BEGIN
— SET @rnd = ROUND((RAND() * 100),3)
— INSERT INTO dbo.TableA (uqid, someVal) VALUES (@cnt, @rnd)
— SET @cnt = @cnt + 1
–END
SELECT a.uqid [a_key], b.uqid [b_key], a.someVal [matching_val]
FROM dbo.TableA a INNER JOIN dbo.TableB b ON a.someVal = b.someVal
We can see below that the merge join was picked, as the query optimizer correctly identified it as the most efficient way of running the query. Note that the hash join is equally good in this circumstance although the indexes will not be of much use. In the execution plan below the clustered indexes are used, but if this is run again with the hash join forced, the non-clustered indexes on the UNIQUE constraints are the inputs to the sort instead (not shown):

Summary
In summary, here’s when to use the various types of join:
LOOP JOIN
Query has a small table on the left side of the join
One or both tables are indexed on the JOIN predicate
HASH JOIN
Tables are fairly evenly-sized or are large
Indexes practically irrelevant unless filtering on additional WHERE clauses, good for heaps
Arguably most versatile form of join
REMOTE JOIN
Same as hash join, but good where right side is geographically distant
Only suitable for INNER JOINs
Not suitable for local tables, will be ignored.
MERGE JOIN
Tables are fairly even in size
Works best when tables are well-indexed or pre-sorted
Uses very efficient sort algorithm for fast results
Unlike hash join, no memory reallocation, good for parallel execution
And if in doubt – let the optimizer decide!
I hope this tip was useful for you and I welcome any comments you have. I’ll do my best to respond ASAP. Please point out any factual inaccuracies, I’ll be happy to correct them, time permitting. Thanks for reading!
Next Steps
- Check out these resources for further reading:
- Craig Freedman – Hash Joins – http://blogs.msdn.com/b/craigfr/archive/2006/08/10/687630.aspx
- MSDN – Understanding Merge Joins – http://msdn.microsoft.com/en-us/library/ms190967(v=sql.100).aspx
- MSDN – Advanced Query Tuning Concepts – http://msdn.microsoft.com/en-us/library/ms191426%28v=SQL.100%29.aspx

Dr. Derek Colley is the lead technical consultant for Optimal Computing, a boutique data consultancy based in the UK NW helping clients troubleshoot, configure, plan and deploy their data platforms. He specializes in data integration and database performance optimization, and is a PhD candidate with Staffordshire University, looking into methods of integrating AL query selection algorithms with the cost-based query optimizer. In his spare time, he enjoys building robots, going outdoors, and spending time with his four children.
- MSSQLTips Awards: Trendsetter (25+ tips)