Problem
As you work with large scale SQL Server Integration Services ETL processes and sequences, you are bound to have to work with UTF-8 encoded text files. Without proper handling, UTF-8 / Unicode characters can cause havoc with your SSIS load tasks. What are some ideas for handling the UTF-8 file formats with SSIS? Check out this tip to learn more.
Solution
First, providing some background about UTF-8 and Unicode would likely go a long way into explaining how to handle these different code page types. Unicode is an encoding standard maintained by the Unicode Consortium; most of the biggest players in the technology field (Google, SAP, Microsoft, Oracle) along with many others belong to the consortium. The consortium was setup to standardize the numbering scheme assigned to represent a letter or character across all languages, countries, software products, and hardware platforms. Drilling down further, UTF-8 is actually an encoding method for handling all the characters in the Unicode set of characters and stands for Unicode Transformation Format. I know I am going to do a disservice to the encoding process by explaining the transformation in these terms, however, UTF is sort of like the decryption key (or secret decoder ring!) used to map your backend bytes to the actual characters displayed on the screen. Of course, there is much more to it, so feel free to take a look at the link in the next steps section of this tip. To ease the conversion from prior encoding standards, keep in mind the first 128 UTF-8 characters match the ANSI character encoding standards.
Working with SSIS and UTF-8 Unicode Data
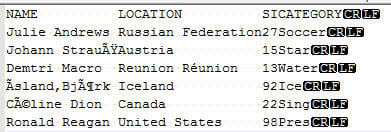
Enough of the theory and background; let us put this knowledge into practice. First, we need to create a UTF-8 encoded text file with some special characters. As you can see from the screen prints below, most of the rows contain one or several special characters. I actually created two different text files; the first text file is a bar delimited, 4 column file as shown in the upper screen print below. The second file is a ragged right, fixed width 4 column file.

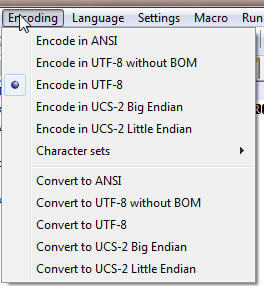
To create the files in the correct encoding format, I used a free tool called NotePad++. As you can see in the below screen print, the encoding for our sample files is set to UTF-8.
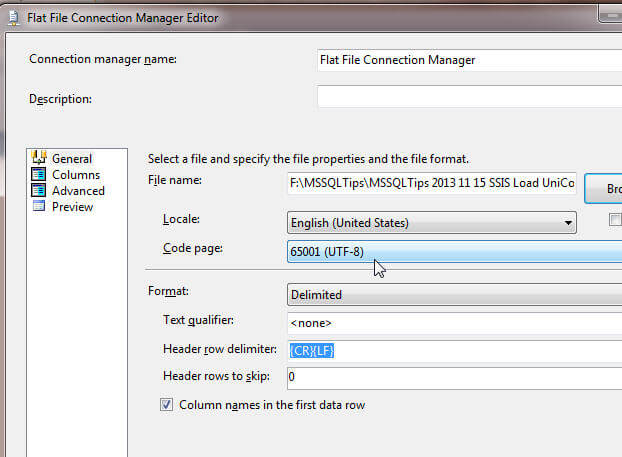
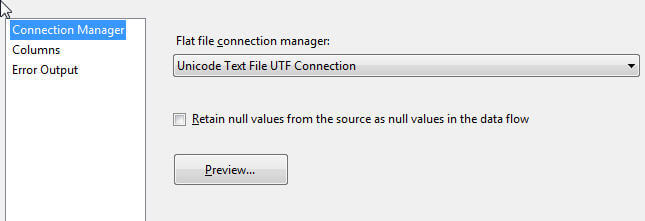
Fortunately, SSIS is smart enough to handle many different encoding code pages. Furthermore, UTF-8 Unicode encoding format is one of the most popular encoding pages as it is used by a wide variety of web pages. Using the bar delimited file, noted in the initial screen prints above, we can quickly load the data with minimal adjustment to the flat file connection. First, you will need to open up SQL Server Data Tools or SSDT (formerly known as BIDS), and then create a new SSIS Package with a proper and descriptive name. Next as shown below, is to create a connection to the bar delimited flat file. After browsing to the flat file, you will notice that on the General Options page that the Code page defaults to the 65001 (UTF-8) code page which is the proper UTF-8 code page. On this same window, adjust the Connection manager name to an appropriate name, change the format to delimited, and then select the “Column names are in the first data row” check box.
Next, on the columns screen, verify that the column delimiter is set to vertical bar.

Then on the Advanced screen, the data type for each string field must be changed from string [DT_STR] to Unicode string [DT_WSTR].

Finally, we can preview the flat file connection setup, as revealed below.
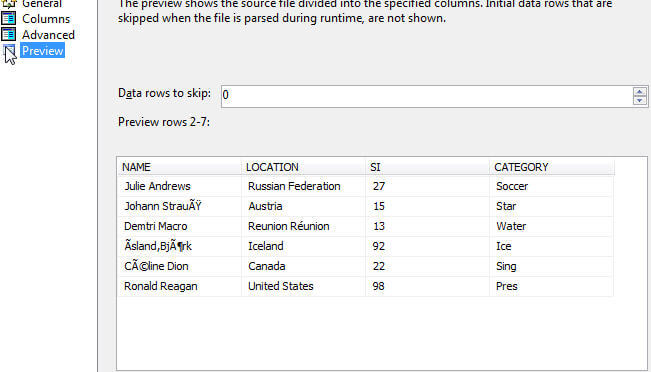
Based on the above preview, the character sets looks like they are displaying the appropriate characters especially from the UTF-8 encoding standpoint. Next, we can setup up our data flow with a flat file source and a SQL Server destination and finally mapping the source and destination columns

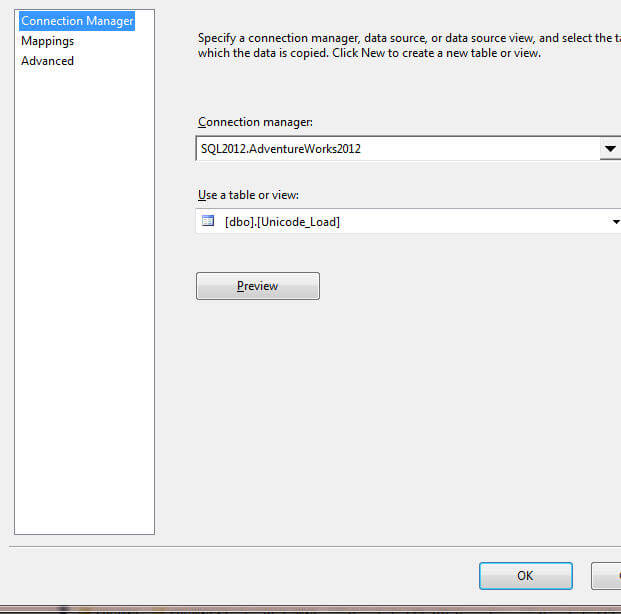
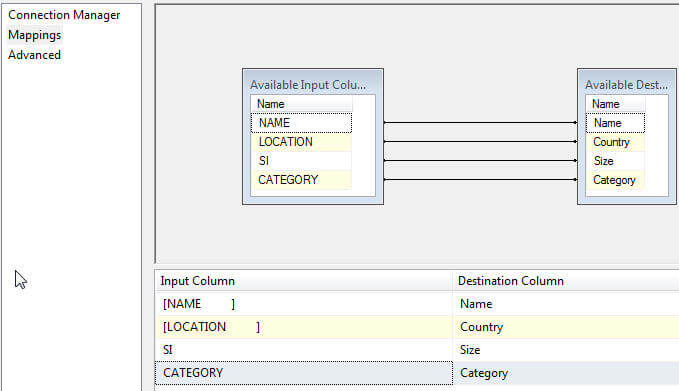
Next the SQL Server destination is created and finally the source and destination columns are mapped as previewed in the next two screen shots.
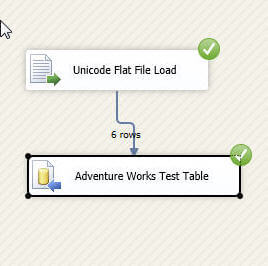
At last, we are ready to test run our data flow package which reports success, as shown below, with two green check marks!
Running a query against the table displays success also; please note all the fields are NVARCHAR data types.

Of course, you are probably saying, “so what is the problem”? With delimited flat file sets, nothing. However, let us move on to a fixed length file. Running through the same connection file process, we start with browsing and selecting our fixed format flat file. Be sure that the Code page is 65001 (UTF-8), the format is set to Ragged right, and that the “Column names in the first data row” check box is selected. So far, so good.
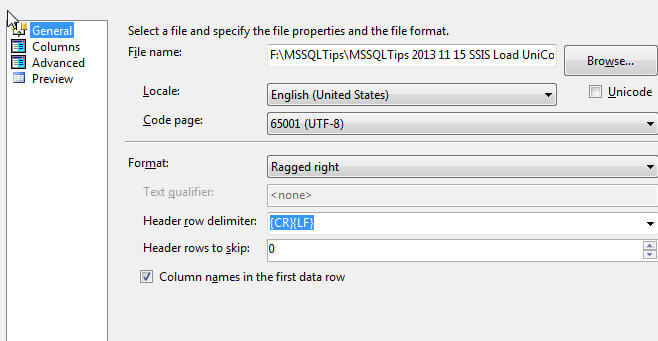
However, as displayed on the below screen print, we immediately begin to see some problems as we attempt to set the fixed column widths. On this screen you set the column widths for each field by click on the ruler area. Taking a look at the first column, the name field, we see that even though the column is supposed to be just 14 characters wide, some of the names with special characters push beyond 14 characters wide. We could adjust the column size by one or more units, but then some of the columns would actually contain characters belonging to another field. Also notice, that each subsequent column is pushed right based on the number of special characters on that row.
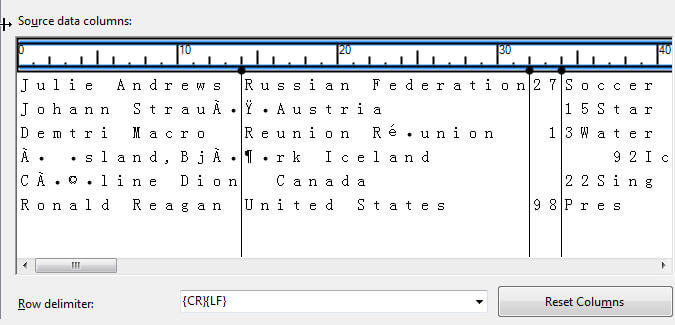
I decided that maybe the problem is just a preview issue and trudge forward onto the advanced screen. Just as with the delimited file, we need to adjust all the character columns to use a Unicode string [DT_WSTR] data type.
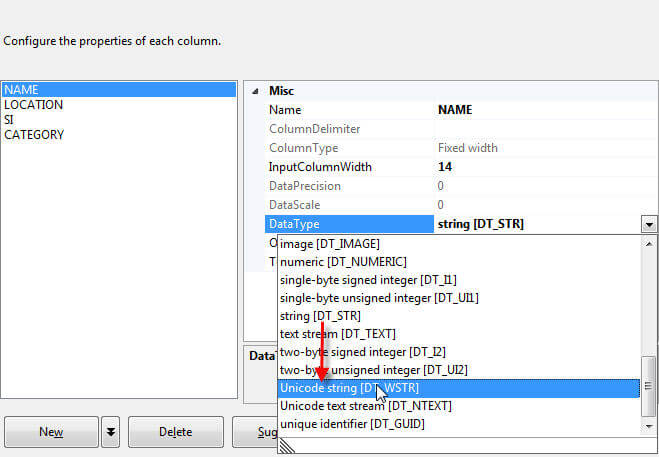
Finally, reviewing the preview window, as illustrated below, the same problem which appeared on column screen surfaces on the preview screen. Again, I contemplated that maybe the issue was just a “preview” issue and moved forward with creating the data flow.

Following the same process noted above for the delimited file, we create a data flow with a flat file source and SQL Server destination are created. Finally we run the fixed file package.
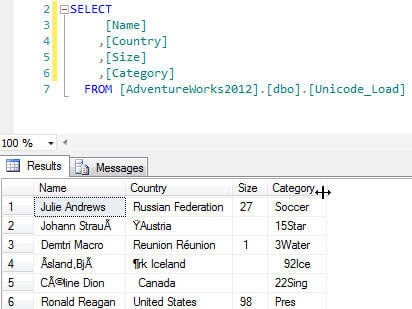
Wow, the data loaded successfully. However reviewing the below query results shows that the preview problem raised earlier permeated to load. The good thing is that characters were loaded correctly, but just into the wrong column.
After completing some various web search results, I come to the conclusion that the problem is a known issue with a related Microsoft Connect entry: http://connect.microsoft.com/SQLServer/feedback/details/742632/european-character-causes-error-when-importing-flat-file-utf-8-code-page-with-ragged-right-format. So what is our work around? Since the characters are being loaded correctly, we actually have a few options. First, and my preferred option is to load the entire row of data into a single column and then use SQL to complete the parsing process. Another option could be to write a VB or C script component to parse out the characters. For the rest of this example, we will focus on the SQL solution. First we need to create a staging table with a single column large enough to load the entire row; the data type for the column needs to be NVARCHAR. I have heard that some folks mention that they cannot fit the entire row into one column, so you can potentially load the data into two or more rows.
Now we can test run the package to load the entire row into the staging table whose result is displayed below.
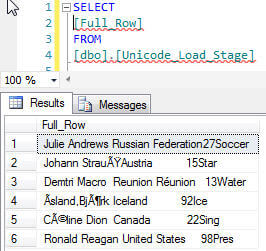
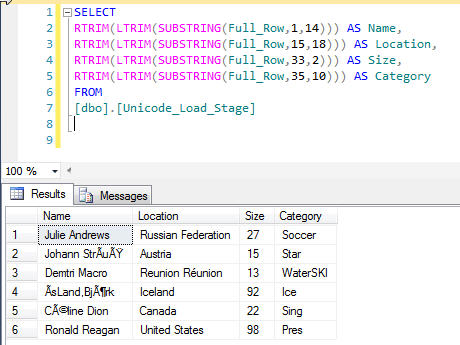
Next we create a query to parse the long string into the appropriate column parts using the SUBSTRING function. Using the original file layout of column widths and start positions can be of great help when creating the Substring query.
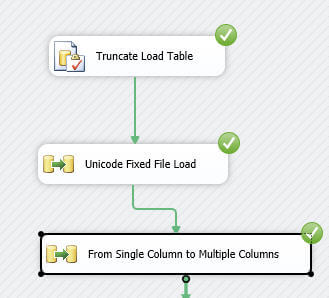
Finally, we can add this query as a source for a second data flow to move the data from the single column staging table to the final table, as illustrated in the next two screen prints.

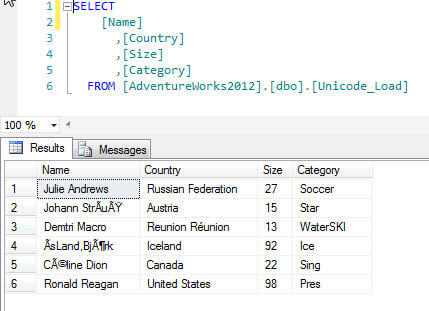
Using this alternate method, we now have the fixed ragged right file loaded into the table as noted below.
Conclusion
Even though SSIS supports a large variety of various code page encoding formats, loading data from a UTF-8 encoded flat files that contain special characters (and other encoding formats) may not load as expected. A delimited file with special characters loads fairly easily and without many issues outside of setting the data types correctly. However if you have a ragged right fixed format flat file, the load will generally occur without error, but as seen in the preview mode of the flat file connection manager, the fields and rows of data that contain special characters will often push other characters to the right and thus load incorrectly parsed data into the wrong fields. This situation can be worked around by loading the entire row as a Unicode string into a column wide enough to accept all the row data. Once loaded into the single column, the data can then be parsed using the SQL Server Substring function. As an alternative, you could also parse the row using a script component in SSIS. Although the issue has been acknowledged on Microsoft Connect, it has been around since SQL Server 2005 and was not addressed in SQL Server 2012. Thus, we will likely need to deal with the workaround for the near future.
Next Steps
- Check out the following resources:
- Unicode Consortium: http://www.unicode.org/
- UTF-8 Specifications: http://www.ietf.org/rfc/rfc3629.txt
- Markus Kuhn’s FAQ on Unicode and UTF-8: http://www.cl.cam.ac.uk/~mgk25/unicode.html#utf-8
- Get started with SQL Server Integration Services:

I have a passion for crafting Business Intelligence Solutions for my user groups. My experience includes almost 15 years of SQL Server involvement with the last 12 years focused specifically on Business Intelligence, SharePoint, OLAP, SSRS, and Decision Support solutions. Currently, I am a Business Intelligence Architect in the healthcare industry, and I also teach database and analytics classes for Kennesaw State University, Southern New Hampshire University, and Reinhardt University. My education includes an MBA and an undergraduate in Accounting (yes I am a reformed accountant!), both from Kennesaw State University. I enjoy every day by trying to grow my faith and spend precious time with my family. I have been happily married to my wife of over 20 years, and we have two teenagers one who we home school with the help of a University Model School, Cornerstone Prep in Acworth, GA (cornerstoneprep.org). Our other child is a Construction Management major at KSU’s Southern Poly / Marietta campus. We are a soccer and Cross Country (XC) family who play, coach, and referee soccer or run for fun most every day. For several years, our family has volunteered (and played with the dogs and cats) at Etowah Valley Humane Society in Cartersville, GA.
- MSSQLTips Awards: Champion (100+tips) – 2016 | Author of the Year – 2015 | Author Contender – 2014, 2016-2021

