Problem
When loading data using SQL Server Integration Services (SSIS) to import data from a CSV file, every single one of the columns in the CSV file has double quotes around the data. When using the Data Flow Task to import the data I have double quotes around all of the imported data. How can I import the data and remove the double quotes?
Solution
This is a pretty simple solution, but the fix may not be as apparent as you would think. Let’s take a look at our example.
Here is the sample CSV file as it looks in a text editor. You can see that all of the columns have double quotes around the data even where there is no data. The file is comma delimited, so this should give us enough information to import the data column by column.

To create the package we use a Data Flow Task and then use the Flat File Source as our data flow source.

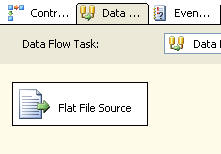
When setting up the Flat File Connection for the data source we enter the information below, basically just selecting our source file.
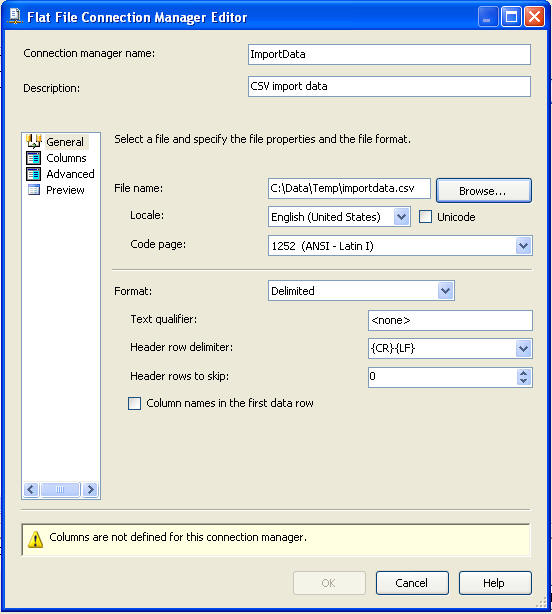
If we do a quick preview on the dataset we can see that every column has the double quotes even the columns where there is no data. If you open the text file in Excel the double quotes are automatically stripped, so what needs to be done in SSIS to accomplish this.
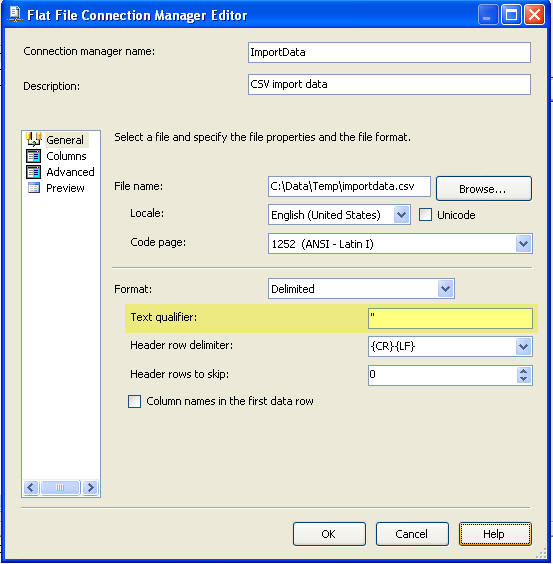
On this screen you can see the highlighted area and the entry that is made for the “Text qualifier”. Here we enter in the double quote mark ” and this will allow SSIS to strip the double quotes from all columns.
If we do another preview we can see that the double quotes are now gone and we can move on to the next part of our SSIS package development.

As mentioned above, this is a simple fix to solve this problem. If you are faced with this issue, hopefully this gives you a quick answer to get your development moving forward. This same technique can be used to strip any other text qualifier data from your files.
Next Steps
- Take a look at these other SSIS tips

Greg Robidoux has been working with databases for 35+ years with extensive hands on SQL Server experience from version 6.5 to 2025. He has authored over 250 technical articles and delivered several presentations online and at various conventions. Greg is also the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server.



Hi Chintan, for your example you might want to just load all columns as strings and then after you get the data loaded you can strip the ” at the beginning and the end and then convert the data into the appropriate data types.
Another thing you could do preprocess the file before using SSIS maybe using PowerShell or some other tool. Replace any occurrence where ” is the first character or the last character in the row and then replace “,” with just ,
This should strip out all of the double quotes.
-Greg
Hello,
This solution was helpful but my csv file have text qualifier as ” and some of the columns have “
Below is the example :
“Worker”,”Y”,”Mr”,”Peter (“Pietro”)”,”Marciano”,”1973-09-19
The column Peter (“Pietro”) have ” in it.
How to load such a data via SSIS ?