By: Koen Verbeeck | Comments (65) | Related: More > Integration Services Development
Problem
Microsoft recently released the OData source adaptor for Integration Services (SSIS). Using this source component, it becomes really straightforward to read data from OData sources, such as SharePoint lists. This tip will walk you through the installation and configuration of this brand new component.
Solution
OData is an open data access protocol to provide access to a data source on a website. It was initially defined by Microsoft. It is used for example in Azure and in SharePoint, but also by other companies like SAP and eBay. This protocol is recommended for the Open Government initiative. For more information, see the related Wikipedia article. One of the most anticipated uses of this source is the ability to read SharePoint lists. Since those lists are accessible through OData, this component now provides a native built-in method to draw data from SharePoint, while previously you had to rely on 3rd party products such as the SharePoint List Source and Destination from Codeplex.
Installation of the OData Source for SQL Server
First of all you need to download the component, which is available for both SQL Server 2012 and 2014. The 2012 version is a separate download, while the 2014 one is located in the SQL Server 2014 Feature Pack. You have the option to download a 32-bit or a 64-bit component. Since SSDTBI (the Visual Studio shell/templates for developing business intelligence projects) is a 32-bit application, we will download this one.

The installation itself is very straightforward. First you have the welcome screen:
In the next screen you have to read and accept to the License Terms.
And that's it. Just click Install.
The installation itself is over very quickly.
And we're done.
If you open up an SSIS project, you can find the new source component in the Common section - not in the Sources where you'd expect it.
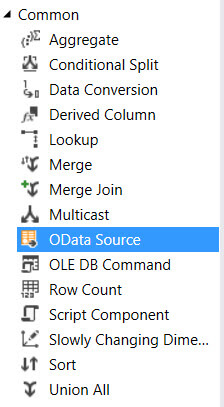
Note: If you have a 64-bit server, you'd want to download the 64-bit version of the component and install it on the machine. Otherwise you are forced to run the package in 32-bit mode.
Reading From an OData Source
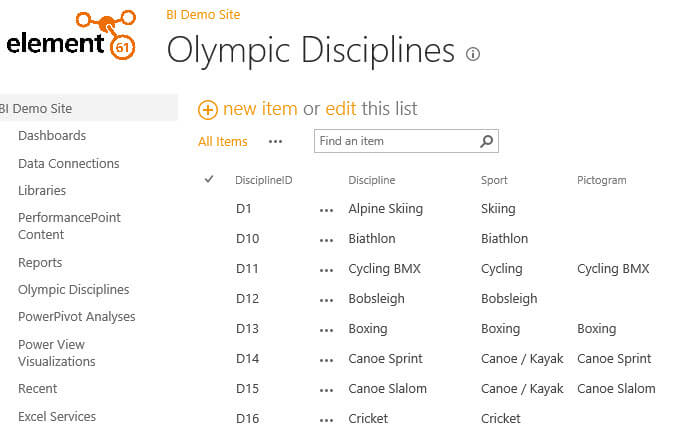
Let's put the new source to work. First of all we are going to read from a SharePoint List. These lists can be exposed as an OData feed, so they are the perfect guinea pigs for our new source. In my SharePoint site, I have a list called Olympic Disciplines, with three columns that interest me: DisciplineID, Discipline and Sport.
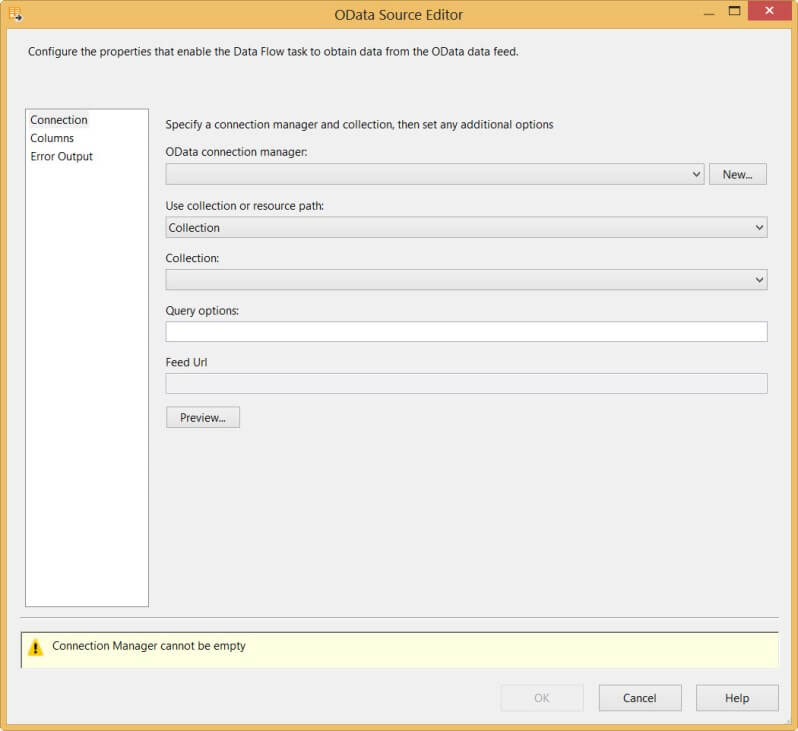
Add a data flow if you haven't already and drag the OData source to the data flow canvas. The first thing to do when opening the editor is creating an OData Connection Manager.
Clicking on New... opens up the OData Connection Manager Editor.
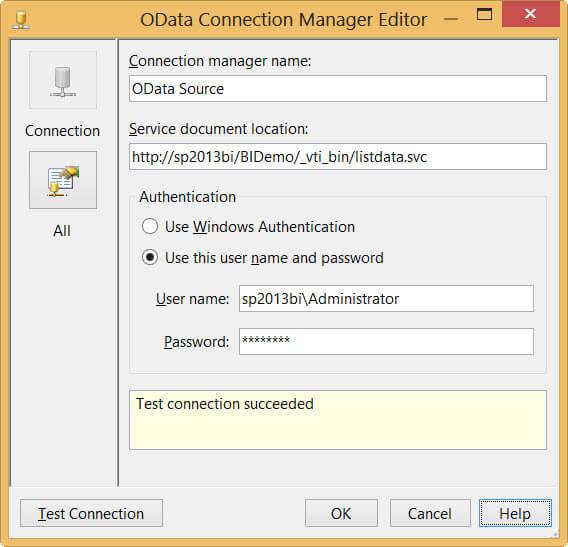
You have to provide a name for the connection manager and the Service Document Location. For reading SharePoint Lists, it takes the following format:
http://mySharePointServer/mySite/_vti_bin/listdata.svc
The last part, _vti_bin/listdata.svc is always fixed; it is the endpoint the source communicates with to retrieve the OData feeds. Listdata is not the name of some SharePoint list. Windows Authentication can be used or you supply a username and password. If the SharePoint site is in another domain, you can pass this as well in the user name field. Click Test Connection to make sure you have supplied the correct parameters. Hit OK to create the connection manager and to go back to the source editor.
In the editor, you have to specify either a collection or a resource path. For now we'll use the collection method, I'll come back to resource paths later in this tip. In the Collection drop-down list, select the SharePoint list you wish to read from. In our case, we need to select OlympicDisciplines.
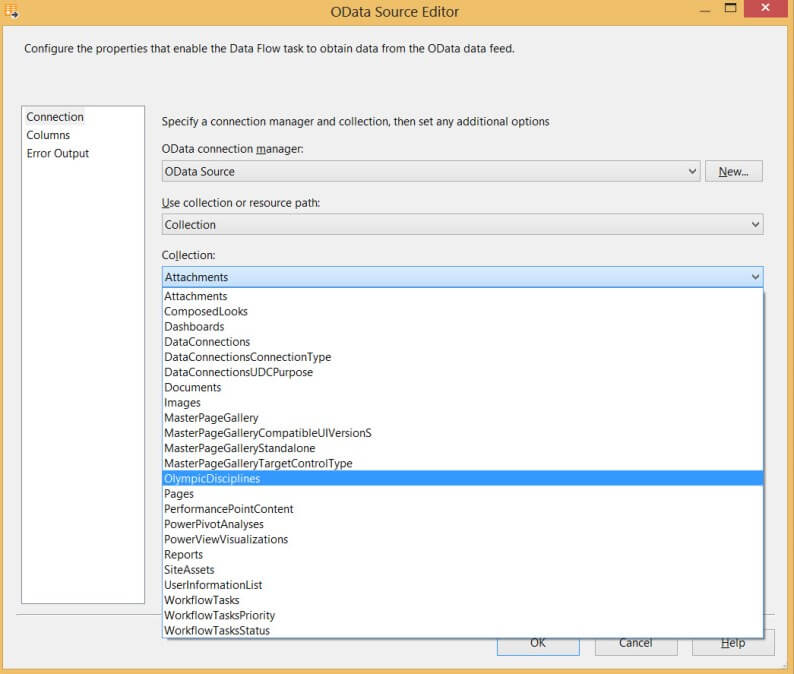
At the bottom of the editor, you get a preview of the full URL of the OData resource you are going to read from.
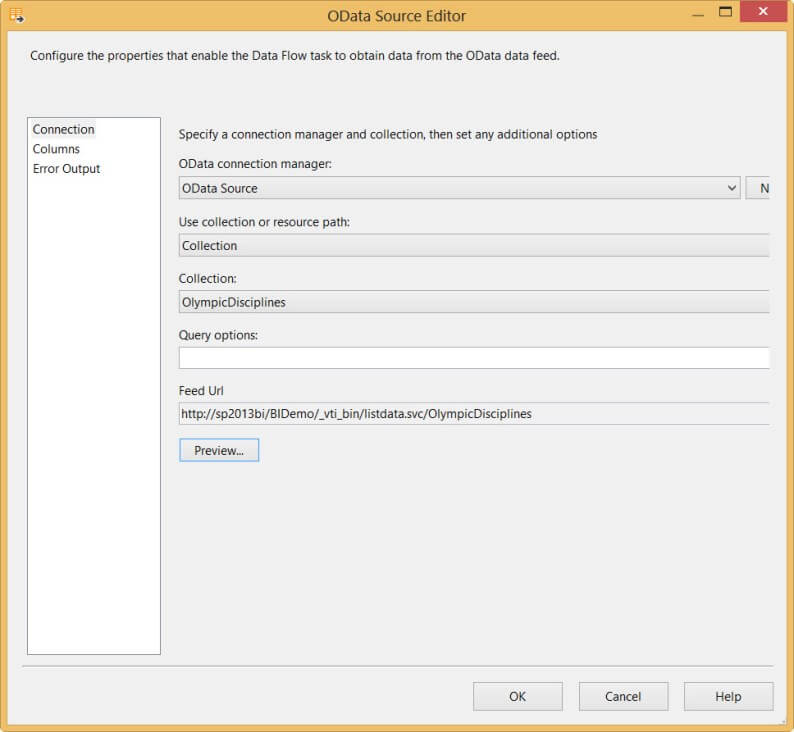
At this point, you can click on Preview... to take a look at the data.
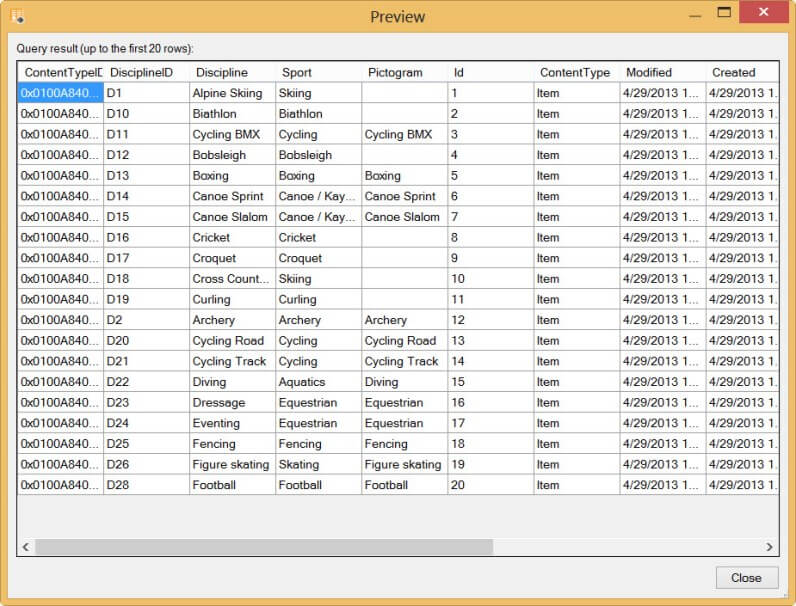
As with all other source components, you can go to the columns pane and either rename columns or remove them from the output. You might notice there are a lot of metadata columns that come along with the SharePoint list. We'll do something about that later on. The Error Output is the same as in any other data flow transformation.
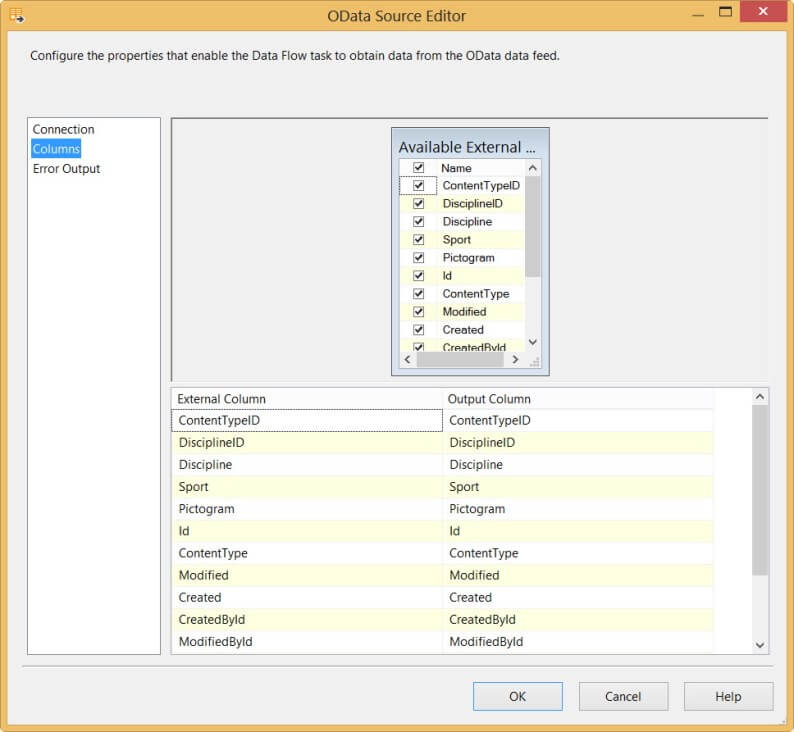
The configuration of the component is done and you can now extract data from the OData feed by running the package!
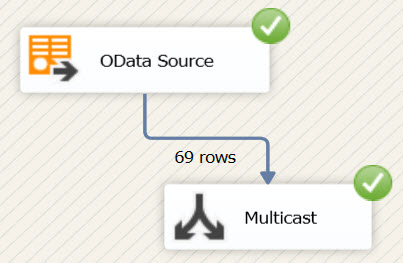
Advanced Configurations for the OData Source Component in SSIS
This is not everything the OData source has up its sleeve. There are some more advanced features we can take advantage off.
Resource Paths
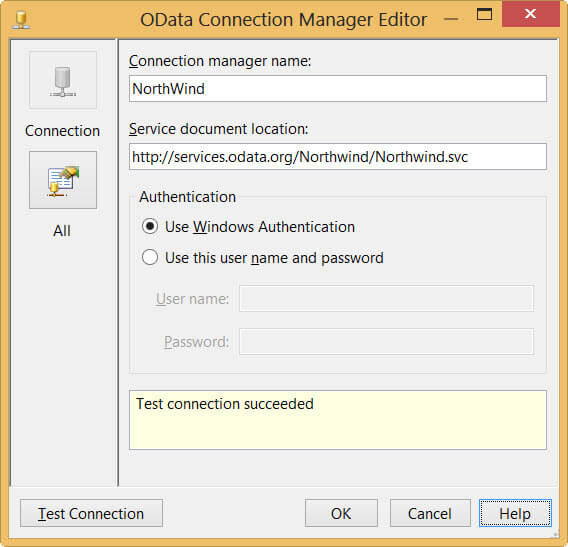
When you select a collection in the editor, you retrieve the columns of the feed and that's it. With resource paths you have more control over the data that is being returned. You can for example select specific IDs or you can link related feeds together. To illustrate this concept, we shall use the publicly available OData feed of the Northwind database. It is located at http://services.odata.org/Northwind/Northwind.svc/. First we need to create a new connection manager. Since it is public, you don't need to specify a user name and password.
We are going to use the following resource path: Customers('ALFKI')/Orders(10643)/Order_Details. This tells the OData protocol to retrieve the order details of order #10643 placed by customer with ID 'ALFKI'.
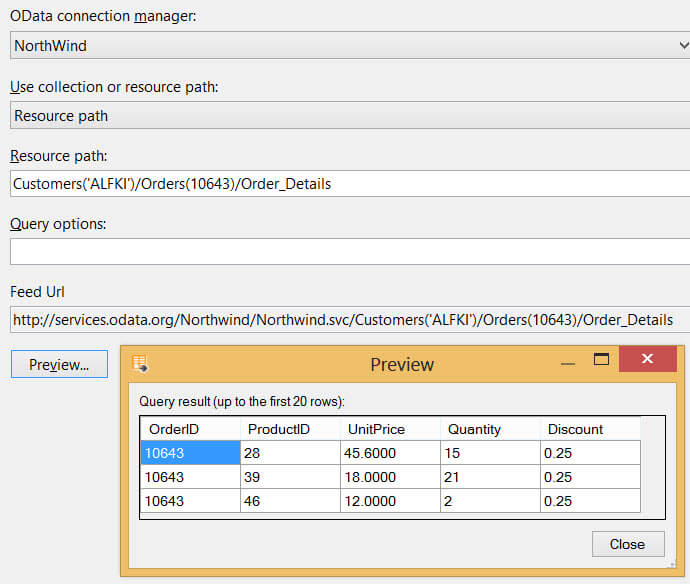
However, at the time of writing the source component is behaving erratically when using resource paths. Some work, as illustrated above, while others don't. For example, the resource path Customers('ALFKI') always returns an error (although it is part of the longer resource path that does work). Referencing a collection directly with a resource path, for example Customers, always returns results.
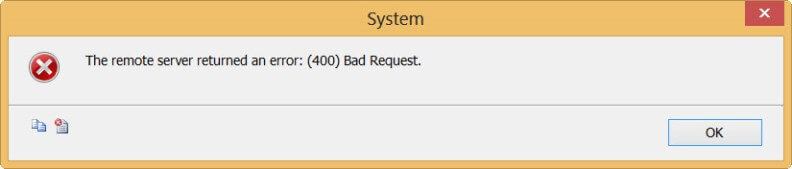
The strange part is that those resource paths do work when used directly in some browsers, such as Chrome, but not in Internet Explorer.
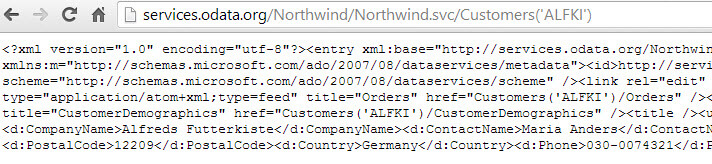
I hope these issues with the resource paths get resolved soon, as resource paths can be really powerful to string multiple OData feeds together. For more information about resource paths, take a look at the OData documentation.
Query Options with OData Data Sources
Another very useful feature are the query options, the last field of the editor. With those query options, you can manipulate and shape the results returned by the OData feed. For example, with $select=DisciplineID,Discipline,Sport you select only those three columns. This is very important, as you want to minimize all the columns returned in order to improve the efficiency of the buffers of the data flow. Too much unnecessary columns means a slower data flow!
There are many other options, such as filtering, skipping rows, sorting, taking the top n rows and so on. Let's expand our query options and also sort descending on the sport column.
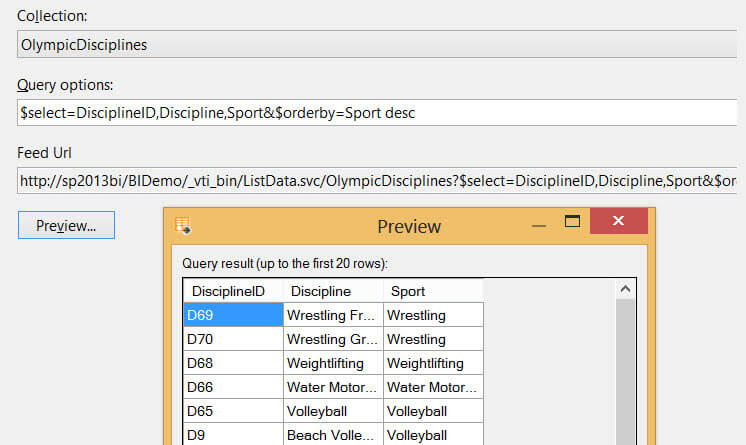
For more information about the various query options, check out the OData documentation.
Source Properties
There are some custom properties of the source component you can configure.
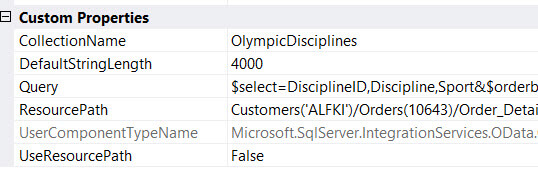
- CollectionName: the name of the collection chosen in the dropdown menu.
- DefaultStringLength: this specifies the length of string columns that have no maximum length. Although sometimes a text stream is used to import string data (see next paragraph). 4000 characters is quite long, so be aware that this can effect the buffer usage of the data flow. This is the only property that is not configurable through the GUI.
- Query: the query options.
- ResourcePath: the resource path used to retrieve the data.
- UseResourcePath: specifies if the property CollectionName or ResourcePath is used.
All properties, except DefaultStringLength, can be set through expressions. For more information about the custom properties, see the following MSDN article: OData Source Properties.
The BLOB Effect
When the metadata of the OData feed is not defined explicitly - in the Olympics Discipline list for example the columns are defined just as string - it is possible SSIS will import the columns with the data type DT_NTEXT, which is a Unicode text stream data type.
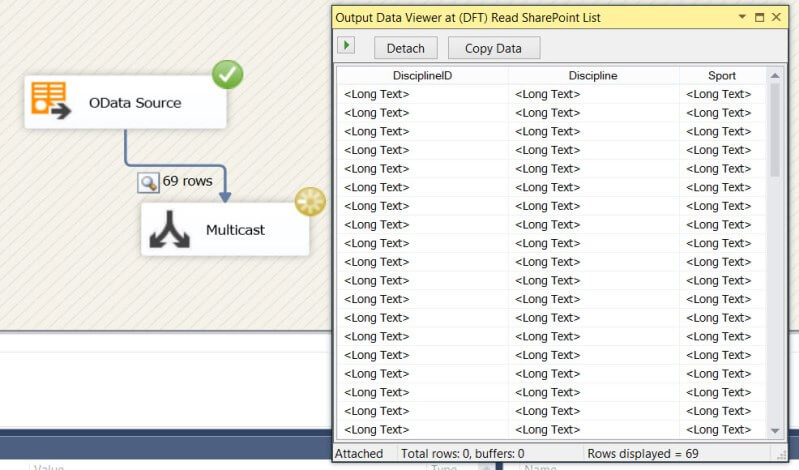
This data type can sometimes be difficult to work with in SSIS, but luckily there is an easy fix: simply go to the advanced editor of the source and set the data type of the columns to a more acceptable data type.
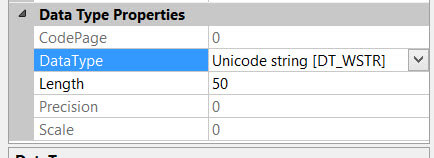
Problem solved!
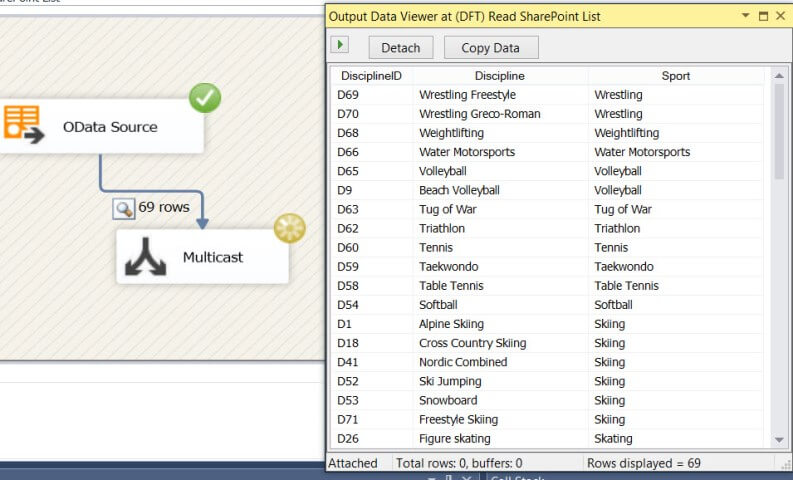
Conclusion
The new SSIS OData source provides an easy way to read OData sources. It can extract data from publicly available OData feeds, but also very easily from SharePoint lists which might be its biggest strength. You can configure query options to manipulate the result set, but using resource paths seems to be a bit tricky.
Next Steps
- Try it out yourself! Download and install the component and try to read some OData data. If you don't have a SharePoint site to test on, you can use a public OData source such as http://services.odata.org/Northwind/Northwind.svc/.
- Some interesting reading material:
- The official OData documentation explains how to use resource paths and the query options and has some nice examples.
- The MSDN pages about the source component: OData Source.
- The following article introduces how SharePoint uses OData and has also examples of resource paths and query options: SharePoint’s REST: an OData Overview.
- This blog post introduces the new SSIS data source as well, but has an interesting caveat when using Office 365 authentication: Using the SSIS OData Source Connector With SharePoint Online Authentication.
- Reading SharePoint Lists with Integration Services 2017.






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
