By: Koen Verbeeck | Comments (6) | Related: > Integration Services Performance
Problem
In a SSIS data flow, there are multiple types of transformations. On one hand you have synchronous and asynchronous transformations, but on the other hand you have non-blocking, semi-blocking and fully-blocking components. In this tip, we'll take a closer look on the performance impact of semi-blocking transformations in SSIS.
Solution
The SSIS data flow is all about buffers - see also Improve SSIS data flow buffer performance - and the classification of transformations is also based on how they handle buffers. Let's take a look at synchronous and asynchronous first:
- Synchronous transformations process rows independent of each other. This means the output occurs at the same time as the input. Rows are grouped into buffers, but in a synchronous implementation this is transparent to the user so it seems like each row is processed separately. The number of records that flow in is exactly the same as the number of records that flow out.
- Asynchronous transformations do no processes rows independently of each other. This results in the output being processed at another time than the input. Input buffers cannot be reused, as the output can have more or less rows than the input. There are different types of behaviors for asynchronous components. Some need to read multiple buffers before they can start processing and adding buffers to the output. An example is the Sort component, which needs to read all of the data before it starts processing output. Other transformations need to read buffers from multiple inputs in order to produce one output. The Union All and Merge are examples of such transformations. And finally some components have no one-to-one correspondence between the output and the input, such as the Aggregate transformation.
The MSDN article Understanding Synchronous and Asynchronous Transformations gives great info about this subject. Because of their nature, synchronous transformations will usually perform better than their asynchronous counterparts. Synchronous transformations are also always non-blocking, since the output is independent of the input. Depending on how an asynchronous transformations behaves, it is either a semi-blocking or a fully-blocking component. The biggest difference between the two is that a semi-blocking transformation doesn't need to read the entire input before it starts producing an output. The blog post SSIS – Non-blocking, Semi-blocking and Fully-blocking components by Jorg Klein gives a good introduction and it has a great overview of the different transformations and their classification.
The Union All is a quite often used transformation to combine different flows into one single flow. It is an asynchronous, semi-blocking transformation and in the following sections we will investigate the impact of this component on the performance of a package.
Preliminary Objects and Testing Scenario
In a lot of scenarios, the performance of the Union All is acceptable, even for a larger amount of rows. There are cases though where the Union All degrades performance, especially when a large number of rows are extracted, but only a limited amount of rows fits in a single buffer. Let's create a big source table to begin with.
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[SalesOrderDetail_Big]') AND type in (N'U')) DROP TABLE [dbo].[SalesOrderDetail_Big]; GO IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[SalesOrderDetail_Big]') AND type in (N'U')) BEGIN CREATE TABLE [dbo].[SalesOrderDetail_Big]( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [bigint] IDENTITY(1,1) NOT NULL, [CarrierTrackingNumber] [nvarchar](25) NULL, [OrderQty] [smallint] NOT NULL, [ProductNumber] [nvarchar](25) NOT NULL, [UnitPrice] [money] NOT NULL, [LineTotal] [numeric](38,6) NOT NULL ); END GO
Using the AdventureWorks2012 sample data, which you can download here, we will take data from the SalesOrderDetail table and insert it multiple times in our source table.
INSERT INTO [dbo].[SalesOrderDetail_Big]
([SalesOrderID]
,[CarrierTrackingNumber]
,[OrderQty]
,[ProductNumber]
,[UnitPrice]
,[LineTotal])
SELECT [SalesOrderID]
,[CarrierTrackingNumber]
,[OrderQty]
,prod.ProductNumber
,[UnitPrice]
,[LineTotal]
FROM [AdventureWorks2012].[Sales].[SalesOrderDetail] sod
JOIN [AdventureWorks2012].[Production].[Product] prod ON sod.ProductID = prod.ProductID;
GO 60The source table now contains 7,157,703 rows and takes about 600 megabytes of storage space. The SSIS package is going to read the data and retrieve the product surrogate key from the DimProduct dimension of the AdventureWorksDW2012 data warehouse using a Lookup. If a surrogate key cannot be retrieved, the ProductNumber is logged into an error table and at the same time it is still stored in the destination table using a dummy surrogate key value of -1.
The destination table has the following schema:
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[Fact_Orders]') AND type in (N'U')) DROP TABLE [dbo].[Fact_Orders]; GO IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[Fact_Orders]') AND type in (N'U')) BEGIN CREATE TABLE [dbo].[Fact_Orders]( [SalesOrderID] [int] NULL, [SK_Product] [int] NULL, [CarrierTrackingNumber] [nvarchar](25) NULL, [OrderQty] [smallint] NULL, [UnitPrice] [money] NULL, [LineTotal] [numeric](38, 6) NULL ); END GO
The error log table looks like this:
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[ErrorLog]') AND type in (N'U')) DROP TABLE [dbo].[ErrorLog]; GO IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[ErrorLog]') AND type in (N'U')) BEGIN CREATE TABLE [dbo].[ErrorLog]( [ID] INT IDENTITY(1,1) NOT NULL, [LookupError] [nvarchar](28) NULL, [LookupKey] [int] NULL, [DateInserted] DATETIME NOT NULL DEFAULT GETDATE() ); END GO
The data is extracted from the source table with the following query:
SELECT [SalesOrderID] ,[CarrierTrackingNumber] ,[OrderQty] -- make every 10th product number invalid in order to fail the lookup ,[ProductNumber] = [ProductNumber] + CASE WHEN [SalesOrderDetailID] % 10 = 0 THEN '_Invalid' ELSE '' END ,[UnitPrice] ,[LineTotal] FROM [dbo].[SalesOrderDetail_Big]; GO
The product number is modified for every 10th row. This will make the lookup fail once in a while, so that the Union All can be tested. On my quite recent laptop, this query returns the 7 million rows in 35 seconds. However, the SSIS package will be slower as we will make the buffers smaller in order to make the Union All performance more visible.
SSIS Package to Test for UNION ALL Performance
The resulting SSIS package is straight forward. The control flow consists of 4 tasks:
- The first task logs the start of the package into a table.
- The second task truncates the destination table. This is mainly done for testing purposes, so that the package can be run multiple times in a row under the same circumstances.
- The third task is the data flow task. We will discuss it next.
- The final task logs the end of the package.
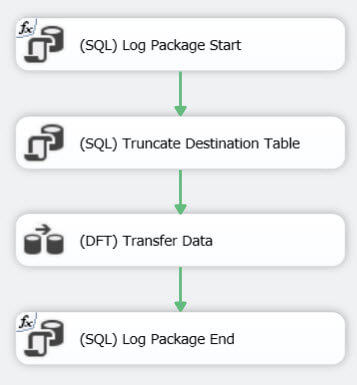
The data flow itself is a bit more complex, but not too dramatic.
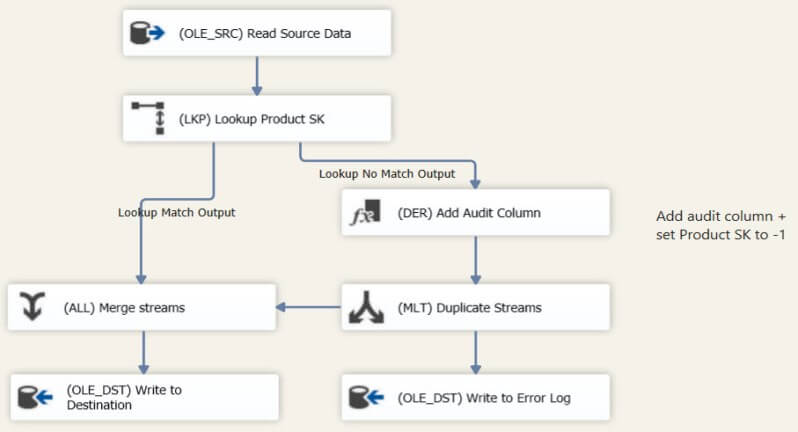
First the data is extracted from the source, after which the product surrogate key is retrieved with the lookup component. Rows that return no match are sent to the "No Match" output. They get an extra audit column with information which indicates that the lookup has failed and the product surrogate key is added with a fixed value of -1.

Next the flow is duplicated through a multicast. One output is sent to the error log, while the other is added to the "Match" output of the Lookup component through a Union All. This Union All component is the subject of this tip. Finally the rows are written to the Fact_Orders destination table.
To simulate a package under performance stress, the DefaultBufferMaxRows property is set to 1000. This results in relatively few rows being added to a buffer when the package is running, which is for example equivalent to having a lot of wide columns in your source table.
Removing the Union All in SSIS
Since the Union All is an asynchronous semi-blocking component, we can expect it will have some impact on performance. In many situations this performance impact is negligible, but as we will demonstrate, a semi-blocking component can slow a package down. The original package - with Union All - takes about 2 minutes and 29 seconds to run. Let's reorganize the layout and find out if we can make the package faster.
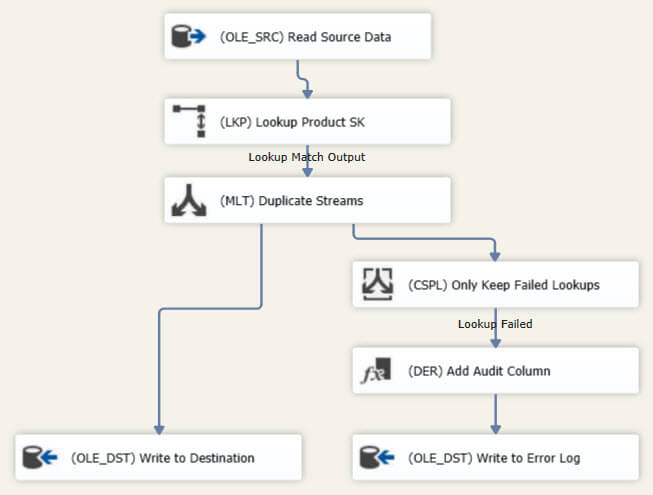
To get rid of the Union All, the Lookup component is configured to ignore failures. This means that if a row doesn't return a match, the retrieved columns are populated with NULL values.

Next, the flow is duplicated through a multicast transformation, which is also a synchronous non-blocking transformation. To find the rows with lookup failures, a conditional split - also synchronous - is used that will test the product surrogate key column for NULL values.

Only those rows are kept and sent to the derived column for the extra audit column, after which they are written to the error log. The other output of the multicast is sent directly to the destination table. The new data flow realizes exactly the same requirements as the original one, but now it doesn't have any asynchronous semi-blocking components. The entire data flow - with the exception of the source which is always asynchronous by the way - consists of synchronous non-blocking transformations. The package now runs in 1 minute and 59 seconds, an improvement of about 20%.
To more objectively test the package performance, both packages are executed 10 times. The blog post SSIS Performance Testing explains the framework used. The following graph depicts the results:
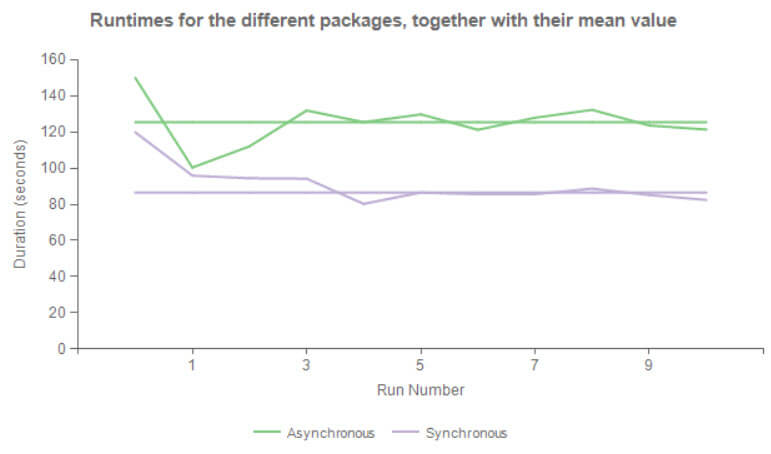
The package with the semi-blocking Union All has a mean runtime of about 125 seconds, while the optimized package has a mean runtime of 86 seconds. This results in about 31% performance improvement. The test package has only one lookup with an associated Union All. Imagine the performance improvement that can be reached if there were multiple lookups in the data flow.
Conclusion
This tip clearly establishes that asynchronous semi-blocking components - the Union All was the subject of the investigation - can have impact on performance. In most cases, performance will be acceptable. However, in packages that are under great stress, you can achieve performance improvements by replacing the semi-blocking components with non-blocking transformations.
Next Steps
- Try it out yourself using the T-SQL code provided in this tip and the packages which you can download here.
- For more tips about SSIS best practices:
- Also read these excellent articles on semi-blocking behavior:






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
