Problem
In the first tip (SQL Server Integration Services (SSIS) – Best Practices – Part 1) of this series I wrote about SSIS design best practices. To continue down that path, this tip is going to cover recommendations related to the SQL Server Destination Adapter, asynchronous transformations, DefaultBufferMaxSize and DefaultBufferMaxRows, BufferTempStoragePath and BLOBTempStoragePath as well as the DelayValidation property.
Solution
In this tip my recommendations are related to different kinds of transformations, impacts for overall SSIS package performance, how memory is managed in SSIS by creating buffers, working with insufficient memory, how SSIS manages spooling when experiencing memory pressure and the significance of the DelayValidation property.
Best Practice #5 – SQL Server Destination Adapter
It is recommended to use the SQL Server Destination adapter, if your target is a local SQL Server database. It provides a similar level of data insertion performance as the Bulk Insert task and provides some additional benefits. With the SQL Server Destination adapter you can transformation the data before uploading it to the destination, which is not possible with Bulk Insert task. Apart from the options which are available with OLEDB destination adapter, you will get some more options with the SQL Server destination adapter as depicted in the images below. For example, you can specify whether the insert triggers on the target table should fire or not. By default this option is set to false which means no triggers on the destination table will fire. Enabling this option may cause an additional performance hit because the triggers need to fire, but the trigger logic may be needed to enforce data or business rules. Additional options include specifying the number of the first/last rows in the input to load, specifying the maximum number of errors which will cause the bulk load operation to be cancelled as well as specifying the insert column sort order which will be used during the upload process.
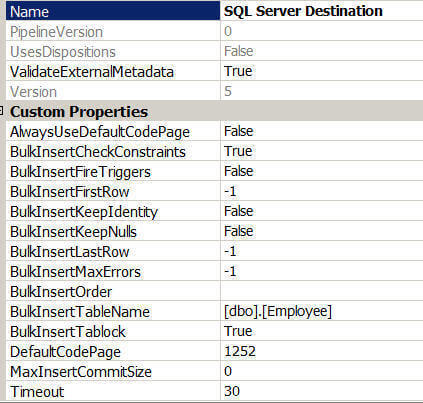
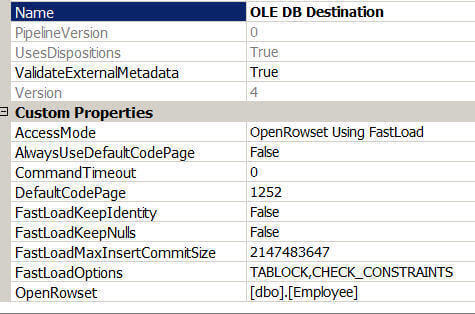
Remember if your SQL Server database is on a remote server, you cannot use SQL Server Destination adapter. Instead use the OLEDB destination adapter. In addition, if it is likely that the destination will change from a local to remote instances or from one SQL Server instance to another, it is better to use the OLEDB destination adapter to minimize future changes.
Best Practice #6 – Avoid asynchronous transformation (such as Sort Transformation) wherever possible
Before I talk about different kinds of transformations and its impact on performance, let me briefly talk about of how SSIS works internally. The SSIS runtime engine executes the package. It executes every task other than data flow task in the defined sequence. Whenever the SSIS runtime engine encounters a data flow task, it hands over the execution of the data flow task to data flow pipeline engine. The data flow pipeline engine breaks the execution of a data flow task into one more execution tree(s) and may execute two or more execution trees in parallel to achieve high performance. Now if you are wondering what an execution tree is, then here is the answer.
An execution tree, as name implies, has a similar structure as a tree. It starts at a source or an asynchronous transformation and ends at destination or first asynchronous transformation in the hierarchy. Each execution tree has a set of allocated buffer and scope of these buffers are associated the execution tree. Also, each execution tree is allocated an OS thread (worker-thread) and unlike buffers this thread may be shared by any other execution tree, in other words an OS thread might execute one or more execution trees. In SSIS 2008, the process of breaking data flow task into an execution tree has been enhanced to create an execution path and sub-path so that your package can take advantage of high-end multi-processor systems.
Synchronous transformations get a record, process it and pass it to the other transformation or destination in the sequence. The processing of a record is not dependent on the other incoming rows. Because synchronous transformations output the same number of records as the input, it does not require new buffers (processing is the done in the same incoming buffers i.e. in the same allocated memory) to be created and because of this it is normally faster. For example, in the Derived column transformation, it adds a new column in each incoming row, but it does not add any additional records to the output.
Unlike synchronous transformations, the asynchronous transformation might output a different number of records than the input requiring new buffers to be created. Because an output is dependent on one or more records it is called a blocking transformation. Depending on the types of blocking it can either be partially blocking or a fully blocking transformation. For example, the Sort Transformation is a fully blocking transformation as it requires all the incoming rows to arrive before processing.
As discussed above, the asynchronous transformation requires addition buffers for its output and does not utilize the incoming input buffers. It also waits for all incoming rows to arrive for processing, that’s the reason the asynchronous transformation performs slower and must be avoided wherever possible. For example, instead of using Sort Transformation you can get sorted results from the source itself by using ORDER BY clause.
Best Practice #7 – DefaultBufferMaxSize and DefaultBufferMaxRows
As I said in the “Best Practices #6”, the execution tree creates buffers for storing incoming rows and performing transformations. So how many buffers does it create? How many rows fit into a single buffer? How does it impact performance?
The number of buffer created is dependent on how many rows fit into a buffer and how many rows fit into a buffer dependent on few other factors. The first consideration is the estimated row size, which is the sum of the maximum sizes of all the columns from the incoming records. The second consideration is the DefaultBufferMaxSize property of the data flow task. This property specifies the default maximum size of a buffer. The default value is 10 MB and its upper and lower boundaries are constrained by two internal properties of SSIS which are MaxBufferSize (100MB) and MinBufferSize (64 KB). It means the size of a buffer can be as small as 64 KB and as large as 100 MB. The third factor is, DefaultBufferMaxRows which is again a property of data flow task which specifies the default number of rows in a buffer. Its default value is 10000.
Although SSIS does a good job in tuning for these properties in order to create a optimum number of buffers, if the size exceeds the DefaultBufferMaxSize then it reduces the rows in the buffer. For better buffer performance you can do two things. First you can remove unwanted columns from the source and set data type in each column appropriately, especially if your source is flat file. This will enable you to accommodate as many rows as possible in the buffer. Second, if your system has sufficient memory available, you can tune these properties to have a small number of large buffers, which could improve performance. Beware if you change the values of these properties to a point where page spooling (see Best Practices #8) begins, it adversely impacts performance. So before you set a value for these properties, first thoroughly testing in your environment and set the values appropriately.
You can enable logging of the BufferSizeTuning event to learn how many rows a buffer contains and you can monitor “Buffers spooled” performance counter to see if the SSIS has began page spooling. I will talk more about event logging and performance counters in my next tips of this series.
Best Practice #8 – BufferTempStoragePath and BLOBTempStoragePath
If there is a lack of memory resource i.e. Windows triggers a low memory notification event, memory overflow or memory pressure, the incoming records, except BLOBs, will be spooled to the file system by SSIS. The file system location is set by the BufferTempStoragePath of the data flow task. By default its value is blank, in that case the location will be based on the of value of the TEMP/TMP system variable.
Likewise SSIS may choose to write the BLOB data to the file system before sending it to the destination because BLOB data is typically large and cannot be stored in the SSIS buffer. Once again the file system location for the spooling BLOB data is set by the BLOBTempStoragePath property of the data flow task. By default its value is blank. In that case the location will be the value of the TEMP/TMP system variable. As I said, if you don’t specify the values for these properties, the values of TEMP and TMP system variables will be considered as locations for spooling. The same information is recorded in the log if you enable logging of the PipelineInitialization event of the data flow task as shown below.
User:PipelineInitialization,ARSHADALI-LAP,FAREAST\arali,Data Flow Task,{C80814F8-51A4-4149-8141-D840C9A81EE7},{D1496B27-9FC7-4760-821E-80285C33E74D},10/11/2009 1:38:10 AM,10/11/2009 1:38:10 AM,0,0x,No temporary BLOB data storage locations were provided. The buffer manager will consider the directories in the TEMP and TMP environment variables.
So far so good. What is important here is to change this default values of the BufferTempStoragePath/BLOBTempStoragePath properties and specify locations where the user executing the package (if the package is being executed by SQL Server Job, then SQL Server Agent service account) has access to these locations. Preferably both locations should refer to separate fast drives (with separate spindles) to maximize I/O throughput and improve performance.
Best Practice #9 – How DelayValidation property can help you
SSIS uses validation to determine if the package could fail at runtime. SSIS uses two types of validation. First is package validation (early validation) which validates the package and all its components before starting the execution of the package. Second SSIS uses component validation (late validation), which validates the components of the package once started.
Let’s consider a scenario where the first component of the package creates an object i.e. a temporary table, which is being referenced by the second component of the package. During package validation, the first component has not yet executed, so no object has been created causing a package validation failure when validating the second component. SSIS will throw a validation exception and will not start the package execution. So how will you get this package running in this common scenario?
To help you in this scenario, every component has a DelayValidation (default=FALSE) property. If you set it to TRUE, early validation will be skipped and the component will be validated only at the component level (late validation) which is during package execution.
Next Steps
- As you develop your SSIS packages keep the best practices from this series in mind, but be sure to test thoroughly in your environment.
- Check out these tips:
- SQL Server Integration Services (SSIS) – Best Practices – Part 1
- Sending email from SQL Server Integration Services (SSIS)
- Sending HTML formatted email in SQL Server using the SSIS Script Task
- Perfmon Counters for the Data Flow Engine in SQL Server Integration Services SSIS
- Category – SQL Server Integration Services
- Category – Performance Tuning
- Tutorial – SQL Server Integration Services

Arshad specializes in Database, Data Warehousing and Business Intelligence application design, development and deployment, at enterprise level, with SQL Server, SSIS, SSRS, SSAS, Service Broker, MDS, DQS, SharePoint and PPS. He is a Microsoft Certified IT Professional in Microsoft SQL Server. He also has experience developing applications in VB/ASP/.NET/ASP.NET/C#, and is a Microsoft Certified Application Developer and Solution Developer for the .NET platform in Web/Windows/Enterprise. Arshad has Master’s degrees in Computer Applications and Business Administration in IT.
Disclaimer: Arshad worked for Microsoft and helped people and businesses make better use of technology to realize their full potential. The opinions mentioned in his tips and articles herein are solely his and do not reflect those of his current or previous employers.
- MSSQLTips Awards: Champion (100+ tips) – 2014