Problem
In this tip we walk through how to setup and view data using SQL Server Analysis Services Linear Regression Data Mining Algorithm.
Solution
In data mining and machine learning circles, the linear regression algorithm is one of the easiest to explain. The linear regression algorithm generates a linear equation that best fits a set of data containing an independent and dependent variable. In this tip, we show how to create a simple data mining model using the Linear Regression algorithm in SQL Server Analysis Services 2014. Before we start, we will execute the following T-SQL code to create our sample dataset with 10,000 rows.
SET NOCOUNT ON GO CREATE TABLE dbo.tblLinearRegression ( pkLinearRegressionExample int identity (1,1) primary key, AttributeX integer NOT NULL, AttributeY decimal(18, 2) NOT NULL ) ON PRIMARY GO declare @i as integer set @i=1 while @i<=2500 begin insert into dbo.tblLinearRegression values (@i, @i * 0.5 + round((300-100)* rand() +100,2)) insert into dbo.tblLinearRegression values (@i, @i * 0.5 + round((300-100)* rand() +100,2)) insert into dbo.tblLinearRegression values (@i, @i * 0.5 + round((300-100)* rand() +100,2)) insert into dbo.tblLinearRegression values (@i, @i * 0.5 + round((300-100)* rand() +100,2)) set @i=@i+1 end GO
The values for the AttributeY column will be a random distribution of data around the line y = 0.5x + 200 as shown in the figure below.

In Visual Studio, create a new Analysis Services Multidimensional and Data Mining Project.

In this tip, we will name the project LinearRegressionExample. Click on OK when finished with the New Project window.

In the Solution Explorer window, right-click on the Data Sources folder and choose “New Data Source…” to initiate the Data Source Wizard.

Click on “Next >”.

Choose your data connection, if one exists. If a data connection does not exist, click on “New…” to create a new data connection.

In this example, we are using a connection to the Tips database on the localhost.

Click on “Next >”.

On the Completing the Wizard screen, the data source name can be changed if desired. Click on “Finish”.

The new data source will appear in the Solution Explorer.

In the Solution Explorer window, right-click on the Data Source Views folder and choose “New Data Source View…” to launch the Data Source View Wizard.

Click on “Next >”.

On the Select a Data Source page in the Relational data sources list box, select the data source we created in the above step. Click on “Next >”.

On the Select Tables and Views page, move the table tblLinearRegression from the Available Objects list box to the Included Objects list box by selecting tblLinearRegression in the Available objects list box and then clicking on the “>” box. Click on “Next >”.

On the Completing the Wizard page, give the Data Source View a name and click on “Finish”.
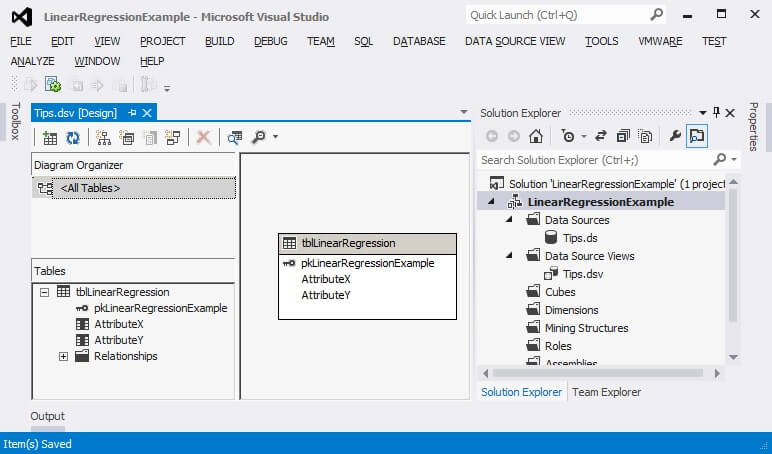
The data source view now appears in the Solution Explorer window. In the center of the image below, we see the columns listed in the table tblLinearRegression.
In the Solution Explorer, right-click on the Mining Structures folder and select “New Mining Structure…” to launch the Data Mining Wizard.
Click on “Next >”.

Press the “From existing relational database or data warehouse” radio button and then click “Next >”.
Next, check the Case box on the ColumnsForDataMining line. Click on “Next >”.

We will use 30% of our data for testing the mining model’s accuracy. Click on “Next >”.

Our mining structure now appears in the Solution Explorer.

The Mining Structure tab is selected by default. At this point the Analysis Services objects reside in the Visual Studio project. Click on the Mining Model Viewer tab.

Visual Studio will attempt to deploy the SSAS objects to the server specified in the project properties. When asked if “Would you like to build and deploy the project first?”, choose “Yes”.

When given the warning about the time it could take to process the mining model and asked “Do you wish to continue?”, choose “Yes”. The number of records in the view is not a large amount, so it should not take more than a minute to process.

When the Process Mining Model window appears, press the “Run…” button.

The Process Progress window will appear. When the process completes successfully, the informational message “Decision Trees found no splits for model” will display which is OK. Select “Close” in the Process Progress window and “Close” again in the Process Mining Model window.

Depending on your hardware configuration, the Load Mining Model Content window might appear stating to “Please wait…”. The Deployment Progress window will appear also stating that the SSAS objects were successfully deployed to the Analysis Services server.

Clicking on the Mining Legend tab (as shown on the bottom right of the following image) will give us the equation for the line that best fits the data.

The equation derived from the model is y = 0.501x + 197.609, which is approximately the y = 0.5x + 200 equation we set out to attain in this example. The y-intercept comes from the Coefficient column where the Term is blank.

The slope comes from the Coefficient column where the Term is Attribute X. Notice there are 7,000 Existing Cases. This is because we specified above that 30% of our records (3,000 out of 10,000) were used for testing the model while the remaining 70% were used for training the model.
 

In the figure below, the linear equation derived from the model is plotted on top of our original data, which shows that the line is an excellent best fit for our data.

Summary
In this tip, we have provided an introduction to the Linear Regression data mining algorithm in SQL Server 2014 Analysis Services.
Next Steps
Explore changes to the results by changing the source data used by the mining model. Also, check out these other tips on data mining in SQL Server Analysis Services.
- SQL Server 2012 Analysis Services Association Rules Data Mining Example
- Explaining the Calculations of Probability and Importance for Complex Association Rules in SQL Server 2012 Analysis Services
- Classic Machine Learning Example In SQL Server Analysis Services
- Microsoft NaÏve Bayes Data Mining Model in SQL Server Analysis Services
- Data Mining Clustering Example in SQL Server Analysis Services SSAS
- SQL Server Analysis Services Glossary

Dr. Dallas Snider is an Assistant Professor in the Computer Science Department at the University of West Florida. He received his Ph.D. in Integrated Computing and M.S. in Instrumental Sciences from the University of Arkansas at Little Rock. He received a B.A. in Physics from Hendrix College. Before joining UWF, he worked as a data warehouse developer for Northrop Grumman Information Systems and prior to that as a database application developer for Acxiom and Euronet. Dr. Snider’s teaching and research interests include data mining, data warehousing, information visualization, and software development.