Problem
In my last two tips, Over 40 queries to find SQL Server tables with or without a certain property and Finding SQL Server views with (or without) a certain property, I provided several metadata queries to find objects such as all tables without a clustered index or all views that use schemabinding.
One thing that has always bugged me about these types of one-off queries is the effort required to pull peripheral information that doesn’t exist in the simpler catalog views, such as schema name, if a table has a primary key, or how many instead of triggers exist on a table.
Solution
What I typically do to overcome this in a lot of my systems is to create my own set of metadata views that can be used to supplement information that would otherwise require cumbersome joins or multiple steps. First, let’s create a schema called metadata:
CREATE SCHEMA metadata AUTHORIZATION dbo;
Now, let’s create a very simple view call metadata.tables that includes the object_id, schema name, object name, and two-part name for all tables:
CREATE VIEW metadata.tables
AS
SELECT
t.[object_id],
[schema] = QUOTENAME(s.name),
[table] = QUOTENAME(t.name),
[object] = QUOTENAME(s.name) + N'.' + QUOTENAME(t.name)
FROM sys.tables AS t
INNER JOIN sys.schemas AS s
ON t.[schema_id] = s.[schema_id];
This immediately eliminates the need to ever join to sys.schemas, since you can just replace any calls to sys.tables with metadata.tables. It also allows you to avoid calls to metadata helper functions like OBJECT_SCHEMA_NAME (see this blog post for my reasons to avoid these).
You can of course include any other columns you might typically refer to, such as t.is_tracked_by_cdc or s.schema_id. But there are a whole bunch of other interesting facts buried in related (and sometimes obscure) catalog views and DMVs that could be made much more accessible. Some examples that I’ll cover here (and this is by no means an exhaustive list):
- number of rows and overall size of the table (for simplicity, let’s assume most people are happy mimicking the output of sp_spaceused);
- last user access to the table;
- number of columns;
- a comma-separated list of the column names;
- whether the table has an identity column;
- number of computed columns (and number of those that are persisted);
- number of columns that use:
- any LOB type (image, text, ntext, XML, varchar(max), nvarchar(max), varbinary(max))
- XML data type
- spatial data types (geography / geometry)
- hierarchyid data type
- rowversion data type (timestamp)
- GUIDs (uniqueidentifier data type)
- deprecated data types (image, text, ntext)
- alias data types
- whether the table has a clustered index;
- whether the table has a primary key;
- index information, such as:
- number of non-clustered indexes
- number of unique indexes
- number of filtered indexes
- number of XML indexes
- number of spatial indexes
- number of default constraints;
- number of check constraints;
- number of after triggers;
- number of instead of triggers;
- whether the table uses data compression (and, if so, which type);
- whether the table is partitioned (and how many partitions are used);
- number of inbound foreign keys (FKs that point to this table);
- number of outbound foreign keys (FKs that point to other tables); and,
- number of schemabound objects that reference the table.
Number of rows and size of the SQL Server table
Since we are going to mimic the output of sp_spaceused, we can simply borrow from its guts and create our own object that reports the same. The thing I don’t like about this procedure is that it could easily have been implemented as an inline table-valued function, then used in a set-based way for more than one table at a time. Here is my attempt to consolidate the procedural approach into a single, set-based statement:
CREATE FUNCTION metadata.tvf_spaceused
(
@object_id INT
)
RETURNS TABLE
AS
RETURN
(
SELECT
[rows],
reserved_kb = r,
data_kb = p,
index_size_kb = CASE WHEN u > p THEN u - p ELSE 0 END,
unused_kb = CASE WHEN r > u THEN r - u ELSE 0 END
FROM
(
SELECT
r = (SUM (p1.reserved_page_count) + COALESCE(MAX(it.r),0)) * 8,
u = (SUM (p1.used_page_count) + COALESCE(MAX(it.u),0)) * 8,
p = (SUM (CASE WHEN p1.index_id >= 2 THEN 0 ELSE
(p1.in_row_data_page_count + p1.lob_used_page_count + p1.row_overflow_used_page_count)
END) * 8),
[rows] = SUM (CASE WHEN p1.index_id IN (0,1)
THEN p1.row_count ELSE 0 END)
FROM sys.dm_db_partition_stats AS p1
LEFT OUTER JOIN
(
SELECT it.parent_id,
r = SUM(p2.reserved_page_count),
u = SUM(p2.used_page_count)
FROM sys.internal_tables AS it
INNER JOIN sys.dm_db_partition_stats AS p2
ON it.[object_id] = p2.[object_id]
WHERE it.parent_id = @object_id
AND it.internal_type IN (202,204,207,211,212,213,214,215,216,221,222,236)
GROUP BY it.parent_id
) AS it
ON p1.[object_id] = it.parent_id
WHERE p1.[object_id] = @object_id
) AS x);
In order to combine this with our base tables view, we can use CROSS APPLY:
SELECT
-- basic metadata
t.[object_id],
t.[schema],
t.[table],
t.[object],
-- mimic spaceused
su.[rows],
su.reserved_kb,
su.data_kb,
su.index_size_kb,
su.unused_kb
FROM metadata.tables AS t
CROSS APPLY metadata.tvf_spaceused(t.[object_id]) AS su
ORDER BY t.[object];
And this will produce output like this, using AdventureWorks2014
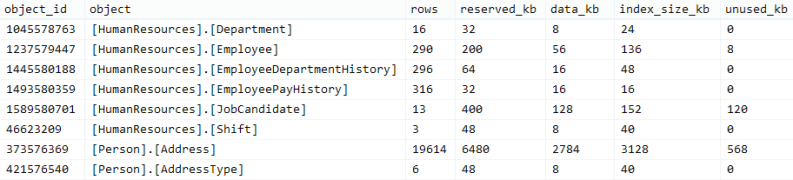
Note: I won’t demonstrate join and apply operations, or sample output, with each new function or view I introduce.
Last SQL Server table accessed
Keeping in mind that there are many caveats here, such as the fact that these DMVs only go back since the last restart and that not all user operations are really user operations, you can get a rough idea about when your tables were last accessed through this view:
CREATE VIEW metadata.table_access
AS
SELECT
[object_id],
last_read = MAX(last_read),
last_write = MAX(last_write)
FROM
(
SELECT [object_id],
last_read = (SELECT MAX(d) FROM (VALUES
(last_user_seek),(last_user_scan),(last_user_lookup))
AS reads(d)),
last_write = (SELECT MAX(d) FROM (VALUES
(last_user_update))
AS writes(d))
FROM sys.dm_db_index_usage_stats
) AS x GROUP BY [object_id];
All kinds of data about SQL Server columns
This view obtains all of the above-mentioned information about a table’s columns, including the overall count, a comma-separated list of column names, and the count of columns using certain data types.
CREATE VIEW metadata.columns
AS
SELECT
c.[object_id],
column_count = COUNT(c.column_id),
column_list = STUFF((SELECT N',' + QUOTENAME(name)
FROM sys.columns AS c2
WHERE c2.[object_id] = c.[object_id]
ORDER BY c2.column_id
FOR XML PATH, TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N''),
has_identity_column = COUNT(NULLIF(c.is_identity,0)),
computed_column_count = COUNT(NULLIF(c.is_computed,0)),
persisted_computed_column_count = COUNT(NULLIF(cc.is_persisted,0)),
LOB_column_count = COUNT
(
CASE
WHEN c.system_type_id IN (34,35,99,241) THEN 1
WHEN c.system_type_id IN (165,167,231) AND c.max_length = -1 THEN 1
END
),
XML_column_count = COUNT(CASE WHEN c.system_type_id = 241 THEN 1 END),
spatial_column_count = COUNT(CASE WHEN c.user_type_id IN (129,130) THEN 1 END),
hierarchyid_column_count = COUNT(CASE WHEN c.user_type_id = 128 THEN 1 END),
rowversion_column_count = COUNT(CASE WHEN c.system_type_id = 189 THEN 1 END),
GUID_column_count = COUNT(CASE WHEN c.system_type_id = 36 THEN 1 END),
deprecated_column_count = COUNT(CASE WHEN c.system_type_id IN (34,35,99) THEN 1 END),
alias_type_count = COUNT(NULLIF(t.is_user_defined,0))
FROM sys.columns AS c
INNER JOIN sys.types AS t
ON c.system_type_id = t.system_type_id
LEFT OUTER JOIN sys.computed_columns AS cc
ON c.[object_id] = cc.[object_id]
AND c.column_id = cc.column_id
GROUP BY c.[object_id];
All kinds of data about SQL Server indexes
Like the columns view, the indexes view obtains much of the detailed information about a table’s indexes, including whether it has a clustered index or a primary key, how many non-clustered indexes exist, and how many indexes are unique / filtered / XML / spatial.
CREATE VIEW metadata.indexes
AS
SELECT
i.[object_id],
i.has_clustered_index,
i.has_primary_key,
i.unique_index_count,
i.filtered_index_count,
p.nonclustered_index_count,
p.xml_index_count,
p.spatial_index_count
FROM
(
SELECT [object_id],
has_clustered_index = MIN(index_id),
has_primary_key = MAX(CONVERT(TINYINT,is_primary_key)),
unique_index_count = COUNT(CASE WHEN is_unique = 1 THEN 1 END),
filtered_index_count = COUNT(CASE WHEN has_filter = 1 THEN 1 END)
FROM sys.indexes AS i
GROUP BY i.[object_id]
) AS i
LEFT OUTER JOIN
(
SELECT [object_id],
nonclustered_index_count = COALESCE([2],0),
xml_index_count = COALESCE([3],0),
spatial_index_count = COALESCE([4],0)
-- columnstore, hash etc. too if you like
FROM
(
SELECT [object_id], [type], c = COUNT(*)
FROM sys.indexes
GROUP BY [object_id], [type]
) AS x
PIVOT (MAX(c) FOR type IN ([2],[3],[4],[5],[6],[7])) AS p
) AS p
ON i.[object_id] = p.[object_id];
Number of default and check constraints
This view returns the number of default and check constraints associated with a given object.
CREATE VIEW metadata.constraint_counts
AS
SELECT
[object_id] = parent_object_id,
default_constraint_count = COUNT(CASE t WHEN 'D' THEN 1 END),
check_constraint_count = COUNT(CASE t WHEN 'C' THEN 1 END)
FROM
(
SELECT parent_object_id, t = 'D'
FROM sys.default_constraints
UNION ALL
SELECT parent_object_id, t = 'C'
FROM sys.check_constraints
) AS c
GROUP BY parent_object_id;
Number of after and instead of triggers
Similarly, this view shows the number of triggers associated with a table, segmented by instead of or after triggers.
CREATE VIEW metadata.trigger_counts
AS
SELECT
[object_id] = parent_id,
after_trigger_count = COUNT(NULLIF(is_instead_of_trigger,1)),
instead_of_trigger_count = COUNT(NULLIF(is_instead_of_trigger,0))
FROM sys.triggers
GROUP BY parent_id;
SQL Server compression and partition information
This view grabs some simple information about whether data compression is used at the heap or clustered index level for a table, and whether the table is partitioned (and, if so, how many partitions there are).
CREATE VIEW metadata.basic_storage
AS
SELECT
[object_id],
[data_compression], -- on at least one partition
has_partitions = CASE partition_count WHEN 1 THEN 0 ELSE 1 END,
partition_count
FROM
(
SELECT
[object_id],
[data_compression] = MAX(COALESCE(NULLIF(data_compression_desc,'NONE'),'')),
partition_count = COUNT(*)
FROM sys.partitions
WHERE index_id IN (0,1)
GROUP BY [object_id]
) AS p;
This is meant to be very rudimentary, returning one pair of facts per table; this is not very meaningful if you might have different compression methods implemented on different indexes or partitions.
SQL Server Foreign key counts
This view represents the number of foreign keys, per object, in each direction.
CREATE VIEW metadata.foreign_key_counts
AS
SELECT
[object_id],
inbound_count = COUNT(CASE t WHEN 'I' THEN 1 END),
outbound_count = COUNT(CASE t WHEN 'O' THEN 1 END)
FROM
(
SELECT [object_id] = referenced_object_id, t = 'I'
FROM sys.foreign_keys
UNION ALL
SELECT [object_id] = parent_object_id, t = 'O'
FROM sys.foreign_keys
) AS c
GROUP BY [object_id];
Number of SQL Server schema-bound references
This view – designed for SQL Server 2008 and up – will show the count of that reference any given object and were created WITH SCHEMABINDING. Just a count can be a good start to see what kind of hill you’ll be climbing if you need to change any of these underlying tables.
CREATE VIEW metadata.schemabound_references
AS
SELECT
t.[object_id],
reference_count = COUNT(*)
FROM metadata.tables AS t
CROSS APPLY sys.dm_sql_referencing_entities(t.[object], N'OBJECT') AS r
WHERE EXISTS
(
SELECT 1
FROM sys.sql_modules AS m
WHERE m.[object_id] = r.referencing_id
AND m.is_schema_bound = 1
)
GROUP BY t.[object_id];
Pulling it all together
Those are all great little views on their own, and it’s very easy to join any one of them to metadata.tables, but you may want to have more fun and combine them. What I did in my case was create a view called “uber_table_info” – which basically joined or applied all of these views and functions into one single, set-based output, with exactly one row per table.
CREATE VIEW metadata.uber_table_info
AS
SELECT
-- basic metadata
t.[object_id],
t.[schema],
t.[table],
t.[object],
-- mimic spaceused
su.[rows],
su.reserved_kb,
su.data_kb,
su.index_size_kb,
su.unused_kb,
-- last access:
ta.last_read,
ta.last_write,
-- column info
c.column_count,
c.column_list,
c.has_identity_column,
c.computed_column_count,
c.persisted_computed_column_count,
c.LOB_column_count,
c.XML_column_count,
c.spatial_column_count,
c.hierarchyid_column_count,
c.rowversion_column_count,
c.GUID_column_count,
c.deprecated_column_count,
c.alias_type_count,
-- index info
i.has_clustered_index,
i.has_primary_key,
i.nonclustered_index_count,
i.unique_index_count,
i.filtered_index_count,
i.xml_index_count,
i.spatial_index_count,
-- constraint info
default_constraint_count = COALESCE(cc.default_constraint_count,0),
check_constraint_count = COALESCE(cc.check_constraint_count,0),
-- trigger info
after_trigger_count = COALESCE(tr.after_trigger_count,0),
instead_of_trigger_count = COALESCE(tr.instead_of_trigger_count,0),
-- storage info
st.[data_compression],
st.has_partitions,
st.partition_count,
-- foreign key counts - inbound, outbound
inbound_fk_count = COALESCE(fk.inbound_count,0),
outbound_fk_count = COALESCE(fk.outbound_count,0),
-- schema-bound references:
schemabound_references = COALESCE(sb.reference_count,0)
FROM metadata.tables AS t
CROSS APPLY metadata.tvf_spaceused(t.[object_id]) AS su
LEFT OUTER JOIN metadata.table_access AS ta
ON t.[object_id] = ta.[object_id]
INNER JOIN metadata.columns AS c
ON t.[object_id] = c.[object_id]
LEFT OUTER JOIN metadata.indexes AS i
ON t.[object_id] = i.[object_id]
LEFT OUTER JOIN metadata.constraint_counts AS cc
ON t.[object_id] = cc.[object_id]
LEFT OUTER JOIN metadata.trigger_counts AS tr
ON t.[object_id] = tr.[object_id]
LEFT OUTER JOIN metadata.basic_storage AS st
ON t.[object_id] = st.[object_id]
LEFT OUTER JOIN metadata.foreign_key_counts AS fk
ON t.[object_id] = fk.[object_id]
LEFT OUTER JOIN metadata.schemabound_references AS sb
ON t.[object_id] = sb.[object_id];
With this view I can easily identify tables by a very wide variety of filters and then get a whole bunch of other information about them – without having to go figure out and run subsequent queries. Whenever I find bits of information that I have to go manually determine two or three separate times, I create a new view or function and incorporate it.
Performance
I will be quite honest with you: none of this was done with runtime performance in mind, since investigations that dig deep into metadata are not things that end users are doing (or that anybody is doing often). So this isn’t going to be the fastest set of views in the world, especially if you query against the final view:
SELECT * FROM metadata.uber_table_info ORDER BY [object];
I don’t encourage you to look too closely at the query plan in that case, because it is quite massive and will likely make you cringe.

Again, this solution is here to save you time in figuring out all of these relationships and manually writing the query. Feel free to tweak it if you find any opportunities for performance enhancements; I would perhaps start at trying to reduce the amount of I/O against the system table syssingleobjrefs.
Conclusion
I suspect that people spend a lot of time re-inventing the wheel when trying to discover certain things about their metadata. This tip showed just the tip of the iceberg – how you can consolidate a lot of the information you might want to discover about tables into a handful of very handy metadata views. You can of course do similar things for any set of first-class entities in your databases – views, procedures, functions, etc. And you can put these views in the model database so that they’re automatically added to any *new* database.
If you’re using SQL Server 2012 or 2014, you could extend this solution to cover things like columnstore indexes and memory-optimized tables. Even if you’re not on the most recent version, you could also add enhancements such as identifying tables that have circular foreign key references, constraints that have user-defined functions in their definitions, or tables that have a clustered index with a GUID as a leading key column.
Next Steps
- Create these views and functions in your own database (download all the scripts here), and build your own views around them. Extend this type of solution to other entities beyond tables. Stop re-inventing the wheel every time you need to find some metadata in your system!
- Bookmark this page, in case you need quick access to these code samples in the future.
- Review the following tips and other resources:
- Over 40 queries to find SQL Server tables with or without a certain property
- Finding SQL Server views with (or without) a certain property
- Find all SQL Server columns of a specific data type using Policy Based Management
- Understanding Catalog Views in SQL Server 2005 and 2008
- Catalog Views (MSDN)
- Dynamic Management Views and Functions (MSDN)

Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He also blogs at sqlblog.org.
- MSSQLTips Awards: Author of the Year – 2016, 2023 | Leadership (200+ tips) – 2022



Sir, Very useful piece of code especially for the investigations during a migration.
If we have mutiple databases hosted on a single SQL instance, do we need to create all these views, function on each database for obtaining the result for each database? Please shed some light.
Thanks for the great code!
For my setup I had to change the join to: INNER JOIN sys.types AS t ON c.system_type_id = t.system_type_id and c.user_type_id = t.user_type_id the user_type_id is needed as in my setup system_type_id is not unique.
BR,
Martin
@a_sql_dba Because they don’t obey isolation semantics – meaning even if you put your metadata queries in read uncommitted, they may still block and be blocked.
https://sqlblog.org/2014/09/04/s1-bad-habits-metadata-helper-functions
I really, badly want to know why I should not use OBJECT_NAME and OBJECT_SCHEMA_NAME which I’m using since they’ve become available. Thanks.
Kris, unfortunately a former employer has moved or taken down a lot of my content without warning, and has been unresponsive. It’s going to take me some time to rebuild some of it, and even longer to fix all the now-dead links out there. :-(
Link not working : http://blogs.sqlsentry.com/aaronbertrand/bad-habits-metadata-helper-functions
I found this alternative, but not sure if it is what was intended
https://thwack.solarwinds.com/groups/data-driven/b/blog/posts/bad-habits-using-certain-metadata-helper-functions
The download file has been corrected.
-Greg
(Ah, I see what happened, somehow the stored procedure definition in the download has the _ stripped.)
Not sure I understand, every reference in the article contains an underscore (table_access) so any errors referencing the name with no underscore (tableaccess) must have happened after copying the script from the article?
Below comment still applies, should be metadata.table_access
Otherwise, this works really great, thinking about fetching the data on regular intervals to keep some sort of audit/log about the schema.