Problem
Let’s say we have a SQL Server table named Table1 and it is referenced by multiple tables via foreign keys (FKs) and these multiple tables again are referenced by other tables via FKs. If I want to delete some data or all data from Table1 and the FKs are not configured as cascading constraints on delete, then if I need to delete from Table1 I have to delete from the leaf level tables first which can get tricky to figure out.
Solution
There are generally two scenarios when deleting data from tables with FKs, one is to delete all of the data and the other is to delete a few records. Of course, for both scenarios we need to delete from the tables in the right order. The first scenario is a little simpler as we just need to delete all rows from the table, but the second scenario is more challenging as we need to delete rows with a WHERE clause combined with complex joins and/or subqueries.
There are two challenges that we will need to deal with:
- We may have complex and long foreign key relationships
- Foreign keys may be composed of multiple columns
This solution will first rely on recursion to search the whole “foreign key tree” starting from the root table, and log the information to a table, then we will loop through this table starting with the leaf level tables, and find the corresponding FKs and then compose the delete statement.
Create Stored Procedure to Display Foreign Key Tree
First we compose a stored procedure to “scan the FK tree” via recursion, here is the code:
use MSSQLTips -- change to your own db
if object_id('dbo.usp_searchFK', 'P') is not null
drop proc dbo.usp_SearchFK;
go
create proc dbo.usp_SearchFK
@table varchar(256) -- use two part name convention
, @lvl int=0 -- do not change
, @ParentTable varchar(256)='' -- do not change
, @debug bit = 1
as
begin
set nocount on;
declare @dbg bit;
set @dbg=@debug;
if object_id('tempdb..#tbl', 'U') is null
create table #tbl (id int identity, tablename varchar(256), lvl int, ParentTable varchar(256));
declare @curS cursor;
if @lvl = 0
insert into #tbl (tablename, lvl, ParentTable)
select @table, @lvl, Null;
else
insert into #tbl (tablename, lvl, ParentTable)
select @table, @lvl,@ParentTable;
if @dbg=1
print replicate('----', @lvl) + 'lvl ' + cast(@lvl as varchar(10)) + ' = ' + @table;
if not exists (select * from sys.foreign_keys where referenced_object_id = object_id(@table))
return;
else
begin -- else
set @ParentTable = @table;
set @curS = cursor for
select tablename=object_schema_name(parent_object_id)+'.'+object_name(parent_object_id)
from sys.foreign_keys
where referenced_object_id = object_id(@table)
and parent_object_id <> referenced_object_id; -- add this to prevent self-referencing which can create a indefinitive loop;
open @curS;
fetch next from @curS into @table;
while @@fetch_status = 0
begin --while
set @lvl = @lvl+1;
-- recursive call
exec dbo.usp_SearchFK @table, @lvl, @ParentTable, @dbg;
set @lvl = @lvl-1;
fetch next from @curS into @table;
end --while
close @curS;
deallocate @curS;
end -- else
if @lvl = 0
select * from #tbl;
return;
end
go
Create Sample Tables and Data
The following T-SQL creates a few tables with FKs. Some of the FKs contain two columns and some tables have multiple FKs.
Open a new SSMS window, and run the following code.
use MSSQLTips -- change to your proper db GO drop table dbo.Q1, dbo.Q2, dbo.Q3, dbo.P1, dbo.P2, dbo.P3, dbo.N1, dbo.N2, dbo.M; GO -- sample tables with FKs create table dbo.M (id int primary key, M_c1 int not null, M_c2 datetime not null, M_c3 char(10) not null, M_c4 datetime); create unique index ux1_A on dbo.M (M_c1); create unique index ux2_A on dbo.M (M_c2, M_c3); create table dbo.N1 (id int primary key, N1_c1 int, N1_c2 datetime, N1_c3 char(10), N1_c4 datetime); create unique index ux1_N1 on dbo.N1 (N1_c1, N1_c3); create unique index ux2_N1 on dbo.N1 ( N1_c2); alter table dbo.N1 add constraint FK_N1_M foreign key (N1_c1) references dbo.M (M_c1); create table dbo.N2 (id int primary key, N2_c1 int, N2_c2 datetime, N2_c3 char(10), N2_c4 datetime); create unique index ux1_N2 on dbo.N2 (N2_c1); create unique index ux2_N2 on dbo.N2 (N2_c3, N2_c4); alter table dbo.N2 add constraint FK1_N2_M foreign key (N2_c2, N2_c3) references dbo.M (M_c2, M_c3); create table dbo.P1 (id int primary key, P1_c1 int, P1_c2 datetime, P1_c3 char(10), P1_c4 datetime); create unique index ux1_P1 on dbo.P1 (P1_c1); alter table dbo.P1 add constraint FK_P1_N1 foreign key (P1_c1, P1_c3) references dbo.N1 (N1_c1, N1_c3); create table dbo.P2 (id int primary key, P2_c1 int, P2_c2 datetime, P2_c3 char(10), P2_c4 datetime); create unique index ux1_P2 on dbo.P2 (P2_c1); create unique index ux2_P2 on dbo.P2 (P2_c2, P2_c3); alter table dbo.P2 add constraint FK_P2_N1 foreign key (P2_c2) references dbo.N1 (N1_c2); alter table dbo.P2 add constraint FK_P2_N2 foreign key (P2_c3, P2_c4) references dbo.N2 (N2_c3, N2_c4); create table dbo.P3 (id int primary key, P3_c1 int, P3_c2 datetime, P3_c3 char(10), P3_c4 datetime); alter table dbo.P3 add constraint FK_P3_N2 foreign key (P3_c1) references dbo.N2 (id); create table dbo.Q1 (id int primary key, Q1_c1 int, Q1_c2 datetime, Q1_c3 char(10), Q1_C4 datetime); alter table dbo.Q1 add constraint FK_Q1_P1 foreign key (Q1_c1) references dbo.P1 (P1_c1); create table dbo.Q2 (id int primary key, Q2_c1 int, Q2_c2 datetime, Q2_c3 char(10), Q2_c4 datetime); alter table dbo.Q2 add constraint FK_Q2_P2 foreign key (Q2_c1) references dbo.P2 (id); create table dbo.Q3 (id int primary key, Q3_c1 int, Q3_c2 datetime, Q3_c3 char(10), Q3_c4 datetime); alter table dbo.Q3 add constraint FK1_Q3_N2 foreign key (Q3_c1) references dbo.N2 (id); alter table dbo.Q3 add constraint FK2_Q3_P2 foreign key (Q3_c2, Q3_c3) references dbo.P2 (P2_c2, P2_c3); GO -- populate all tables insert into dbo.M (id, M_c1, M_c2, M_c3, M_c4) select 1, 10, '2015-01-01', 'AB1', '2015-01-02' union all select 2, 20, '2015-01-02', 'AB2', '2015-01-03' union all select 3, 30, '2015-01-03', 'AB3', '2015-01-04'; insert into dbo.N1 (id, N1_c1, N1_c2, N1_c3, N1_c4) select 11, 20, '2015-01-01', 'CD1', '2015-01-02' union all select 21, 30, '2015-01-02', 'CD2', '2015-01-03' union all select 31, 10, '2015-01-03', 'CD3', '2015-01-04'; insert into dbo.N2 (id, N2_c1, N2_c2, N2_c3, N2_c4) select 11, 11, '2015-01-01', 'AB1', '2015-01-02' union all select 12, 22, '2015-01-02', 'AB2', '2015-01-03' union all select 13, 33, '2015-01-03', 'AB3', '2015-01-04'; insert into dbo.P1 (id, P1_c1, P1_c2, P1_c3, P1_c4) select 100, 20, '2014-01-01', 'CD1', '2015-01-02' union all select 101, 30, '2014-01-02', 'CD2', '2015-01-03' union all select 102, 10, '2014-01-03', 'CD3', '2015-01-04' insert into dbo.P2 (id, P2_c1, P2_c2, P2_c3, P2_c4) select 200, 20, '2015-01-01', 'AB1', '2015-01-02' union all select 201, 30, '2015-01-02', 'AB2', '2015-01-03' union all select 202, 10, '2015-01-03', 'AB3', '2015-01-04' insert into dbo.P3 (id, P3_c1, P3_c2, P3_c3, P3_c4) select 301, 11, '2010-01-01', 'EF1', '2015-02-02' union all select 302, 13, '2010-01-02', 'EF2', '2015-02-03' union all select 303, 12, '2010-01-03', 'EF3', '2015-02-04' insert into dbo.Q1 (id, Q1_c1, Q1_c2, Q1_c3, Q1_c4) select 1001, 10, '1999-10-11', 'GH1', '2015-01-02' union all select 1011, 20, '2000-10-12', 'GH2', '2015-01-03' union all select 1021, 30, '2001-10-13', 'GH3', '2015-01-04' insert into dbo.Q2 (id, Q2_c1, Q2_c2, Q2_c3, Q2_c4) select 2001, 201, '2009-11-11', 'IJ1', '2014-01-12' union all select 2011, 202, '2000-12-12', 'IJ2', '2013-01-13' union all select 2021, 200, '2010-03-13', 'IJ3', '2012-01-14' insert into dbo.Q3 (id, Q3_c1, Q3_c2, Q3_c3, Q3_c4) select 3001, 11, '2015-01-01', 'AB1', '2015-01-02' union all select 3011, 12, '2015-01-02', 'AB2', '2015-01-03' union all select 3021, 13, '2015-01-03', 'AB3', '2015-01-04'; GO SELECT [Table]='M', ID, C1=M_c1, C2=M_c2, C3=M_c3, C4=M_c4 FROM DBO.M union all SELECT [Table]='N1', ID, C1=N1_c1, C2=N1_c2, C3=N1_c3, C4=N1_c4 FROM DBO.N1 union all SELECT [Table]='N2', ID, C1=N2_c1, C2=N2_c2, C3=N2_c3, C4=N2_c4 FROM DBO.N2 union all SELECT [Table]='P1', ID, C1=P1_c1, C2=P1_c2, C3=P1_c3, C4=P1_c4 FROM DBO.P1 union all SELECT [Table]='P2', ID, C1=P2_c1, C2=P2_c2, C3=P2_c3, C4=P2_c4 FROM DBO.P2 union all SELECT [Table]='P3', ID, C1=P3_c1, C2=P3_c2, C3=P3_c3, C4=P3_c4 FROM DBO.P3 union all SELECT [Table]='Q1', ID, C1=Q1_c1, C2=Q1_c2, C3=Q1_c3, C4=Q1_c4 FROM DBO.Q1 union all SELECT [Table]='Q2', ID, C1=Q2_c1, C2=Q2_c2, C3=Q2_c3, C4=Q2_c4 FROM DBO.Q2 union all SELECT [Table]='Q3', ID, C1=Q3_c1, C2=Q3_c2, C3=Q3_c3, C4=Q3_c4 FROM DBO.Q3
The diagram below shows the relationships for the tables we just created.
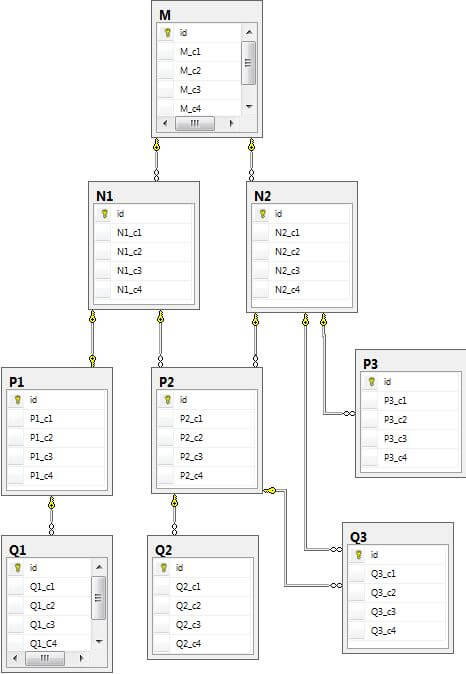
Display Foreign Key Tree
Let's open another SSMS query window, and run the following code to show the FK tree. We want to use the highest level table, which is the dbo.M table for the sample tables we created.
-- if you just want to see the FK hierarchy, then run this-- and check the result under Message tab use MSSQLTips exec dbo.usp_SearchFK 'dbo.M' --two part naming convention
We will see the following result:

Deleting Specific SQL Server Records with Foreign Keys
Let's say I want to delete a record in dbo.M table WHERE id=2. We can open a new SSMS query window and run the following script.
-- the following is an example to show what code can be generated to do the table deletionset nocount on;
if object_id('tempdb..#tmp') is not null
drop table #tmp;
create table #tmp (id int, tablename varchar(256), lvl int, ParentTable varchar(256));
insert into #tmp
exec dbo.usp_SearchFK @table='dbo.M', @debug=0;
declare @where varchar(max) ='where M.id=2' -- if @where clause is null or empty, it will delete tables as a whole with the right order
declare @curFK cursor, @fk_object_id int;
declare @sqlcmd varchar(max)='', @crlf char(2)=char(0x0d)+char(0x0a);
declare @child varchar(256), @parent varchar(256), @lvl int, @id int;
declare @i int;
declare @t table (tablename varchar(128));
declare @curT cursor;
if isnull(@where, '')= ''
begin
set @curT = cursor for select tablename, lvl from #tmp order by lvl desc
open @curT;
fetch next from @curT into @child, @lvl;
while @@fetch_status = 0
begin -- loop @curT
if not exists (select 1 from @t where tablename=@child)
insert into @t (tablename) values (@child);
fetch next from @curT into @child, @lvl;
end -- loop @curT
close @curT;
deallocate @curT;
select @sqlcmd = @sqlcmd + 'delete from ' + tablename + @crlf from @t ;
print @sqlcmd;
end
else
begin
declare curT cursor for
select lvl, id
from #tmp
order by lvl desc;
open curT;
fetch next from curT into @lvl, @id;
while @@FETCH_STATUS =0
begin
set @i=0;
if @lvl =0
begin -- this is the root level
select @sqlcmd = 'delete from ' + tablename from #tmp where id = @id;
end -- this is the roolt level
while @i < @lvl
begin -- while
select top 1 @child=TableName, @parent=ParentTable from #tmp where id <= @id-@i and lvl <= @lvl-@i order by lvl desc, id desc;
set @curFK = cursor for
select object_id from sys.foreign_keys
where parent_object_id = object_id(@child)
and referenced_object_id = object_id(@parent)
open @curFK;
fetch next from @curFk into @fk_object_id
while @@fetch_status =0
begin -- @curFK
if @i=0
set @sqlcmd = 'delete from ' + @child + @crlf +
'from ' + @child + @crlf + 'inner join ' + @parent ;
else
set @sqlcmd = @sqlcmd + @crlf + 'inner join ' + @parent ;
;with c as
(
select child = object_schema_name(fc.parent_object_id)+'.' + object_name(fc.parent_object_id), child_col=c.name
, parent = object_schema_name(fc.referenced_object_id)+'.' + object_name(fc.referenced_object_id), parent_col=c2.name
, rnk = row_number() over (order by (select null))
from sys.foreign_key_columns fc
inner join sys.columns c
on fc.parent_column_id = c.column_id
and fc.parent_object_id = c.object_id
inner join sys.columns c2
on fc.referenced_column_id = c2.column_id
and fc.referenced_object_id = c2.object_id
where fc.constraint_object_id=@fk_object_id
)
select @sqlcmd =@sqlcmd + case rnk when 1 then ' on ' else ' and ' end
+ @child +'.'+ child_col +'=' + @parent +'.' + parent_col
from c;
fetch next from @curFK into @fk_object_id;
end --@curFK
close @curFK;
deallocate @curFK;
set @i = @i +1;
end --while
print @sqlcmd + @crlf + @where + ';';
print '';
fetch next from curT into @lvl, @id;
end
close curT;
deallocate curT;
end
go
We will get the following result, which we can then copy to another query window and execute.
delete from dbo.Q1 from dbo.Q1 inner join dbo.P1 on dbo.Q1.Q1_c1=dbo.P1.P1_c1 inner join dbo.N1 on dbo.P1.P1_c1=dbo.N1.N1_c1 and dbo.P1.P1_c3=dbo.N1.N1_c3 inner join dbo.M on dbo.N1.N1_c1=dbo.M.M_c1 where M.id=2; delete from dbo.Q2 from dbo.Q2 inner join dbo.P2 on dbo.Q2.Q2_c1=dbo.P2.id inner join dbo.N1 on dbo.P2.P2_c2=dbo.N1.N1_c2 inner join dbo.M on dbo.N1.N1_c1=dbo.M.M_c1 where M.id=2; delete from dbo.Q3 from dbo.Q3 inner join dbo.P2 on dbo.Q3.Q3_c2=dbo.P2.P2_c2 and dbo.Q3.Q3_c3=dbo.P2.P2_c3 inner join dbo.N1 on dbo.P2.P2_c2=dbo.N1.N1_c2 inner join dbo.M on dbo.N1.N1_c1=dbo.M.M_c1 where M.id=2; delete from dbo.Q2 from dbo.Q2 inner join dbo.P2 on dbo.Q2.Q2_c1=dbo.P2.id inner join dbo.N2 on dbo.P2.P2_c3=dbo.N2.N2_c3 and dbo.P2.P2_c4=dbo.N2.N2_c4 inner join dbo.M on dbo.N2.N2_c2=dbo.M.M_c2 and dbo.N2.N2_c3=dbo.M.M_c3 where M.id=2; delete from dbo.Q3 from dbo.Q3 inner join dbo.P2 on dbo.Q3.Q3_c2=dbo.P2.P2_c2 and dbo.Q3.Q3_c3=dbo.P2.P2_c3 inner join dbo.N2 on dbo.P2.P2_c3=dbo.N2.N2_c3 and dbo.P2.P2_c4=dbo.N2.N2_c4 inner join dbo.M on dbo.N2.N2_c2=dbo.M.M_c2 and dbo.N2.N2_c3=dbo.M.M_c3 where M.id=2; delete from dbo.P3 from dbo.P3 inner join dbo.N2 on dbo.P3.P3_c1=dbo.N2.id inner join dbo.M on dbo.N2.N2_c2=dbo.M.M_c2 and dbo.N2.N2_c3=dbo.M.M_c3 where M.id=2; delete from dbo.P1 from dbo.P1 inner join dbo.N1 on dbo.P1.P1_c1=dbo.N1.N1_c1 and dbo.P1.P1_c3=dbo.N1.N1_c3 inner join dbo.M on dbo.N1.N1_c1=dbo.M.M_c1 where M.id=2; delete from dbo.Q3 from dbo.Q3 inner join dbo.N2 on dbo.Q3.Q3_c1=dbo.N2.id inner join dbo.M on dbo.N2.N2_c2=dbo.M.M_c2 and dbo.N2.N2_c3=dbo.M.M_c3 where M.id=2; delete from dbo.P2 from dbo.P2 inner join dbo.N2 on dbo.P2.P2_c3=dbo.N2.N2_c3 and dbo.P2.P2_c4=dbo.N2.N2_c4 inner join dbo.M on dbo.N2.N2_c2=dbo.M.M_c2 and dbo.N2.N2_c3=dbo.M.M_c3 where M.id=2; delete from dbo.P2 from dbo.P2 inner join dbo.N1 on dbo.P2.P2_c2=dbo.N1.N1_c2 inner join dbo.M on dbo.N1.N1_c1=dbo.M.M_c1 where M.id=2; delete from dbo.N1 from dbo.N1 inner join dbo.M on dbo.N1.N1_c1=dbo.M.M_c1 where M.id=2; delete from dbo.N2 from dbo.N2 inner join dbo.M on dbo.N2.N2_c2=dbo.M.M_c2 and dbo.N2.N2_c3=dbo.M.M_c3 where M.id=2; delete from dbo.M where M.id=2;
Deleting All Data From All Tables
If you set @where to NULL or '' (empty string), the script will generate a bunch of delete table statements without any table joins and create them in the order they need to be executed as shown below.
delete from dbo.Q1 delete from dbo.Q2 delete from dbo.Q3 delete from dbo.P3 delete from dbo.P1 delete from dbo.P2 delete from dbo.N1 delete from dbo.N2 delete from dbo.M
Summary
When the FK DELETE cascade option is not "enabled", deleting data from tables with FKs in the right dependency order is no easy task. In this tip, a recursive stored procedure is created to traverse through all the FKs which have a common ancestor table, and then all the child / parent FK relationship will be recorded together with the information of how deep (i.e. level) this FK is from the ancestor, so we can use the info to delete table(s) starting from the leaf level up to the ancestor table at the root level.
Table cleanup can be a lengthy topic with many scenarios, such as deleting all tables in a database, deleting one or a few tables, or just deleting a few records in one master table which are referenced by multiple level of other tables. The solution can be used to delete or truncate tables by disabling/re-enabling, or dropping/recreating FKs, or temporarily modifying FKs to enable the delete cascade option. In this tip, I just tried to solve the most complex scenario to me, which I could not find a solution.
Next Steps
This generator script can be easily modified to run the dynamically generated SQL directly instead of printing out the statements, but sometimes it is better to first see the code that is going to be executed.
There are many good foreign key related table manipulation tips, please check out the following:
- Drop and Re-Create All Foreign Key Constraints in SQL Server
- Truncate All Tables in a SQL Server database
- Identify all of your foreign keys in a SQL Server database
- List Tables in Dependency (Foreign Key) Order - SQL Server

Jeffrey Yao is a senior SQL Server consultant with 15 years of database administration, his current interests are on database administration automation and visualization. He enjoys reading the concise and smart sql tips and loves R&D work in DBA Engineering topics. His blog is at: http://www.sqlservercentral.com/blogs/jeffrey_yao/.

@Jeffery to fix the nesting level exceeded (limit 32). I just added an additional exit condition in usp_SearchFK
while (@@fetch_status = 0 and @lvl <= 20) — Or what ever level you want to bail on
this happens when you have a table dependent on itself (Parent, Child in the same table)
has anyone found a way to get around the error?
Maximum stored procedure, function, trigger, or view nesting level exceeded (limit 32). @Jeffery
@WJ how you solve this issue!
Does anyone have a version of this script that would use aliases for table names during script creation? This script has errors if one of the tables has multiple foreign keys from the same table. Any help is appreciated