Problem
SQL Server 2016 comes with the integration of the popular language R into the database engine. This feature has been introduced in SQL Server 2016 preview CTP 3.0 and is called SQL Server R Services. You can write R code in your favorite R development environment, such as RStudio or Revolution R Enterprise, or you can run R code directly on SQL Server using stored procedures. In this tip, executing R code in a client development environment is introduced.
Solution
SQL Server 2016 preview
As mentioned earlier, at the time of writing SQL Server 2016 is still in preview (at the time of writing CTP 3.0 has been released). This means that the features of R Services can still change and that functionality might change, disappear or be added.
Prerequisites
In the documentation, the environment where you write and execute your R code is referenced as the data science workstation. You can find more information here. The following two tips describe how you can set up this data client workstation and how you need to configure the server:
- SQL Server 2016 R Services: Guide for Server Configuration
- SQL Server 2016 R Services: Guide for Client Configuration
Introduction to RevoScaleR
When you installed all of the Revolution R Enterprise software, the R package RevoScaleR was installed as well. This package enables you to run high-performance “big data” analytics. The package provides several data sources – SQL Server included of course – and various compute contexts which can be used with the high performance analytical functions. A compute context defines where the R code is executed. You can either choose the run the code locally on your own computer – like most R distributions – or you can create a SQL Server compute context. With a SQL Server compute context, the R code is run inside SQL Server and it can benefit from its computational power, which is exactly the point of SQL Server R Services and the Advanced Analytics Extensions feature. However, not all features are already included in the SQL Server 2016 CTP3.0 preview. For example, parallel execution is not yet included. You can find an overview of the missing features in the MSDN article Known Issues for SQL Server R Services.
When Revolution R Enterprise is installed, a few user manuals and demo scripts are included. You can easily find the location of the demo scripts using the command rxGetOption(“demoScriptsDir”);.

Similar, you can find the directory with the sample data using the command rxGetOption(“sampleDataDir”);.

In the same parent folder, you can find the folder doc which contains several useful user manuals.

A very interesting manual is the RevoScaleR SQL Server Getting Started Guide. You can find a slightly more up-to-date version here.
Writing and executing R scripts locally using SQL Server data
With SQL Server R Services, it’s straight forward to run R scripts over your own data stored inside SQL Server. RevoScaleR provides you with easy to use functions to help you interacting with SQL Server. As an example, let’s try to connect to SQL Server, run a query and create a histogram of its results.
First we have to create the connections string (keep in mind R is case sensitive). Then, using the function RxSQLServerData, we can define the data set that we wish to retrieve from SQL Server.
sqlServerConnString <- "Driver=SQL Server;Server=localhost;Database=AdventureWorksDW2014;Uid=myUser;Pwd=myPassword"; sqlServerAges <- RxSqlServerData(sqlQuery = "SELECT Ages = DATEDIFF(YEAR,[BirthDate],GETDATE()) FROM [dbo].[DimCustomer]",connectionString = sqlServerConnString,colInfo = list(Ages = list(type = "integer")));
Note: by prefixing a function name with a question mark, you can call the help page of that particular function.
You can either define a table or a query. If you use a query, do not end it with a semicolon or you will get an error. In our example we selected all of the ages from the customer dimension from AdventureWorks. The object sqlServerAges does not contain the actual result set. Instead, it’s just an instance of the RxSqlServerData class which merely describes the source of the data.

RevoScaleR has its own plotting functions. For example, using rxHistogram we can easily create a histogram plot over the ages of the customers:
rxHistogram(~Ages,data=sqlServerAges,histType="Percent"); #Ages is the name of the column or the result set

If you want to do further analysis on the data set inside R, or if you want to use other plotting functions (of other R packages perhaps), you can simply import the data from SQL Server into a data frame using the rxImport function. Let’s import the data and use the general hist function to create a histogram this time.
df <- rxImport(inData=sqlServerAges); #import to data frame head(df); #show the first few rows of the data hist(df$Ages);

Writing R scripts like described in this paragraph doesn’t require installing the Advanced Analytics Extensions feature of SQL Server. All you need to do is follow the instructions of the tip SQL Server 2016 R Services: Guide for Client Configuration to set-up your data science workstation with RevoScaleR.
Using a SQL Server compute context
When you write R scripts locally using the RevoScaleR package, but they are executed inside SQL Server, you are using a SQL Server compute context. In the previous paragraph, we were using a local compute context. This means that the resources of your machine was used to do the R calculations. All SQL Server did was run the query and return the results. However, if you want to do more powerful and more resource-demanding analysis, you might need the calculational power of SQL Server to do the calculations in-database. Let’s find out how you can switch the compute context to SQL Server.
The documentation tells you to create a shared directory on the client machine, but it doesn’t specify why. Testing shows you can create a SQL Server execution context without a shared directory. Maybe it’s needed for more advanced features. Anyway, with the following commands you can specify the shared directory and create one if needed.
sqlShareDir <- paste("c:\\AllShare\\", Sys.getenv("USERNAME"), sep="");
#dir.create(sqlShareDir, recursive = TRUE) #enable this command to create the directory
The following parameters specify how we want the R session to handle the output:
sqlWait <- TRUE; # we want to wait for the results sqlConsoleOutput <- FALSE # we don't want console output from the in-database computations
Now we can define the SQL Server compute context and use the function rxSetComputeContext to use it:
sqlCompute <- RxInSqlServer(connectionString = sqlServerConnString,shareDir = sqlShareDir,wait = sqlWait,consoleOutput = sqlConsoleOutput); rxSetComputeContext(sqlCompute);
At the bottom of the development environment, we can see the compute context has changed to the SQL Server database.

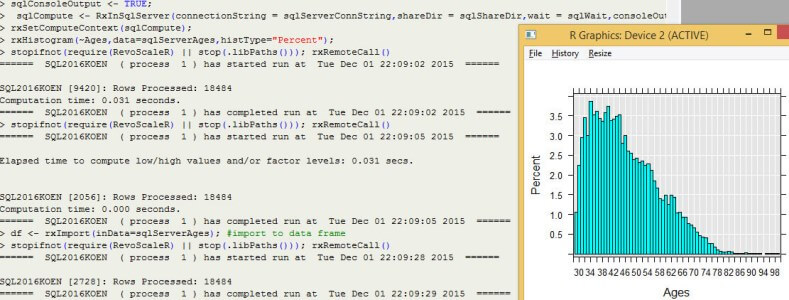
When you now execute R code using the RevoScaleR package, the computations are now done in the SQL Server database. Regular R code is still executed locally. If you enable the console output, you get an idea of the row counts processed and the durations of the various calculations.
Note that using a SQL Server execution context will only work if you configured the server as in the tip SQL Server 2016 R Services: Guide for Server Configuration.
Conclusion
Using the RevoScaleR package, you can easily extract data out of SQL Server into your data science work station for further analysis. If the server is configured with the Advanced Analytics Extensions, you can also run the R code – with RevoScaleR functions – directly on the server. The results are then returned to the client.
Next Steps
- Configuring the client and the server:
- For more info on R Services:
- Installing SQL Server R Services
- SQL Server R Services
- Configure and Manage Advanced Analytics Extensions
- A white paper about RevoScaleR: Revolution R Enterprise ScaleR: Fast, Highly Scalable R on Multiple Processors
- For more SQL Server 2016, read these other SQL Server 2016 Tips.

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025
