Problem
How do I show relationships between pairs of rows in a table where the rows share the same value on a field? I need the pair-wise relationships to appear in a separate result set from the original source table. In addition, rows in the source table that do not share a value should be excluded from the derived result set.
Solution
In typical business computing domains, such as banking and healthcare, rows in source data can sometimes share a common value. Two persons can be linked to the same debt. Repeat visits to a hospital for a patient for the same medical diagnosis is another example. When a patient repeatedly visits a hospital for the same diagnosis, it may denote poor treatment. When two or more persons are linked to the same debt, then one person may be a source of information about the primary debtor or a linked person can even be responsible for paying the debt which the first person has not already paid.
The source row for this type of problem must consist of at least two columns. One column includes unique identifiers for each entity that can enter into a link. The second required column includes a linked value column. The linked value column can be numeric or text based. Any two source rows with the same linked column value are considered linked by the value that they share. If the linked column value for a source row occurs just once or is not populated, then the source row is not linked to any other source row.
The derived result set is computed from the identifier column and linked value column in the source result set. Each row in the derived result set will include two identifiers, such as debtor id or hospital visit id for a patient. Any one source row identifier can be paired with one or more other values on different rows. There is one pair of identifiers per row in the derived result set. Each pair of rows in the derived result set share a common value, such as a debt identifier or a medical diagnosis. Rows in the source table that do not link to other rows by a value, such as debt identifier for which there is only one potential payer, should be excluded from the derived result set.
A sample source and derived data set
The following screen shot shows the format for a source result set for this kind of problem. The PersonID column has numeric values of 1 through 20. The GroupID column shows the letters A through F along with some blank rows. A blank GroupID value for a PersonID row denotes a person who is not linked to any other person. The column of GroupID values is the linked value column. The column of PersonID values denotes entities that are linked by common values in the GroupID column.
When the same GroupID value exists on two rows, such as for PersonID values of 5 and 6, then those two persons belong to the same group. Similarly, if the same GroupID value appears on three rows, such as for PersonID values 7, 8, 9, then all three corresponding persons belong to the same group.

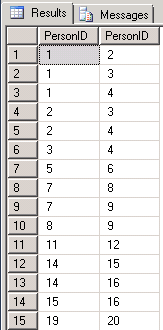
All the derived result set rows are listed below to help clarify the construction of the derived result set. As you can see, source rows with matching GroupID values form pairs with all other PersonID values. However, the order of PersonID values is not relevant. Therefore, if PersonID 1 appears first in a pair with PersonID 2, then there is no need to show PersonID 2 first in a pair with PersonID 1. Notice also that a PersonID value never matches itself — so PersonID 5 cannot match PersonID 5.
The number of rows in the derived result set depends on the number of rows in the source table with matching linked values. Within a linked value, the number of rows in the derived result set is the combinations of two entities with the same linked value.
- For example, PersonID values 5 and 6, both have GroupID B. These are the only two persons with this GroupID value, and they therefore add just one row to the derived result set. See row 7 in the derived result set.
- In contrast, PersonID values 7, 8, and 9 share GroupID C. Because our derived result set is based on combinations of 2 from the set of three persons, these three persons contribute three rows to the derived result set: 7 and 8, 7 and 9, and finally 8 and 9. See rows 8, 9, and 10 in the derived result set.
- PersonID values 1, 2, 3, and 4 all share GroupID value A. These four persons add six rows to the derived result set. The combinations in the derived result set have values of 1 and 2, 1 and 3, 1 and 4, 2 and 3, 2 and 4, and finally 3 and 4. See rows 1 through 6 in the derived result set.
Code for computing the derived result set
The following script illustrates one approach for computing the derived result set from the source result set. In fact, the following script generated the derived result set in the preceding screen shot from the source data displayed in the initial screen shot. A download file for this tip includes an INSERT statement with the sample data referenced by the code described below. The sample data presented in this first example were especially constructed to make it easy to understand the topic presented. Another subsequent example shows other data that lends itself to computing pair-wise relationships between entities that share linked values.
Persons_Groups in the FROM clauses denotes the source result set with PersonID and GroupID columns; this data source points at the data displayed in the initial screen shot. Two nested subqueries reference the source result set — once each for the first and second person in a pair within the derived result set. The contents of the derived result set appear in the preceding screen shot.
An INNER JOIN operator and its ON clause combine the result set from each sub-query by their GroupID values. This part of the solution ensures that pairs are only for source data rows with the same GroupID value.
WHERE clauses further refine the solution. For example, the WHERE clause within each subquery removes all rows from the derived result set with a blank GroupID value. Another WHERE clause just after the ON clause for the INNER JOIN operator restricts the derived result set to combinations, and not permutations, of PersonID values two at a time. This WHERE clause also eliminates the possibility of any PersonID row in the source result set from matching itself in the derived result set.
The ORDER BY clause is just to make the derived result set easily show the matched pairs within a GroupID value. It is not strictly necessary for deriving the pairs from the source data.
-- How do I enumerate all linked persons by pair without enumerating any person -- more than once; persons link to one another through GroupID -- enumerate all PersonID linking to another PersonID via a GroupID SELECT [1st].PersonID, [2nd].PersonID FROM ( SELECT * FROM Persons_Groups WHERE GroupID != '' ) [1st] INNER JOIN ( SELECT * FROM Persons_Groups WHERE GroupID != '' ) [2nd] ON [1st].GroupID = [2nd].GroupID WHERE [1st].PersonID < [2nd].PersonID ORDER BY [1st].PersonID
Source data for a more typical example
The source data set in the preceding example was especially structured for the pair-wise linking problem. For example, there were just two columns — one for the entities being linked and another for the linked value. In addition, rows were ordered by PersonID value and the linked values also were ordered in the same way. In general, the identifiers for persons and the order of the linked values will not have the same order. In addition, all persons with a linked value had one shared with at least one other person. With real world data, it can readily happen that some entities have a linked value that is not shared with any other entity. In other words, a linked value need not always indicate a value shared by two or more entities. When the data have this kind of distribution, then the code for the solution must account for this possibility.
The next screen shot shows a data source for pair-wise linking that includes four columns. In this case, the linking is among persons who own distinct accounts. The ID column values denote a person who owns an account, and the ACCOUNT# denotes the distinct accounts. The link_val column indicates a set of values for linking persons represented by person ID values. The link_name column denotes the type of value for linking persons. In this example, persons are eligible for linking by just one type of linked value because the link_name column value is always A. However, I have encountered requirements where entities can match one another on more than just one type of linked value.
The rows of the source result set are sorted by link_value (see the screen shot below), but this is not necessary for the solution. The sort order is only for simplifying the presentation of the solution.
- The first pair of persons with ID values of 7 and 8 have the same link_val of 21470. Therefore, persons corresponding to ID values of 7 and 8 link to one another through their common link_val of 21470.
- The third person with an ID value of 19 has a distinct link_val of 22592. This person will not be in the derived result set because the person does not share a link_val with any other person.
- The five persons in rows 11 through 15 share a link_val of 54887. These persons have ID values of 5, 6, 16, 17, 18. There are 10 pairs of persons for this set of 5 persons. The ID value pairs are: (1) 5 and 6, (2) 5 and 16, (3) 5 and 17, (4) 5 and 18, (5) 6 and 16, (6) 6 and 17, (7) 6 and 18, (8) 16 and 17, (9) 16 and 18, (10) 17 and 18.

Code for computing the derived result set for a more typical example
The following script demonstrates a slightly re-factored version of the code from the initial example for the second source data set. The derived result set contains three columns — one for the ID value of each person in a pair and a third value for the link_val by which the persons pair. An ORDER BY clause at the end of the script orders the rows of the derived result set by link_val, the ID value for the first person in a pair, and the ID value for the second person in a pair. The screen shot after the script shows the derived result set.
The SELECT statement for the result set cross joins two subqueries and then cleans up the output with two WHERE criteria. One subquery is for the first person in a pair. A second subquery is for the second person in a pair. Each subquery contains the ID and link_val of each person from the source data set (##SQLServerTips_LinkedAccounts).
The WHERE criteria determine which rows from the cross join are retained in the derived result set.
- The first criterion is that the first and second person in a pair must have the same link_val.
- The second criterion is that the ID value for the first person must be less than the ID for the second person.
-- generate id value pairs for ordering rows in more typical example
SELECT
distinct_first_person.[ID] fid
,distinct_second_person.[ID] sid
,distinct_first_person.link_val
FROM
(
SELECT
##SQLServerTips_LinkedAccounts.link_val
,##SQLServerTips_LinkedAccounts.[ID]
FROM ##SQLServerTips_LinkedAccounts
) distinct_first_person
CROSS JOIN
(
SELECT
##SQLServerTips_LinkedAccounts.link_val
,##SQLServerTips_LinkedAccounts.[ID]
FROM ##SQLServerTips_LinkedAccounts
) distinct_second_person
WHERE distinct_first_person.link_val = distinct_second_person.link_val
AND distinct_first_person.[ID] < distinct_second_person.[ID]
ORDER BY link_val, fid, sid
The result set from the preceding query shows a separate row for each pair of persons with a matching link_val. Furthermore, the rows are ordered by link_val. The fid column is for the first person, and the sid column is for the second person.
You can verify the output by comparing the source data for the second example with the result set in the result set below.
- For example, the first two rows in the source data are for persons with ID values of 7 and 8. Each of these persons have the same link_val of 21470. No other person has a link_val of 21470. As a result, there is just one pair for link_val 21470.
- The link_val 22592 is for the person with an ID value of 19. No other person has a link_val of 22592. As a result, the person with an ID value of 19 does not appear in the result set.
- The next three rows in the source data set are for persons with ID values of 9, 10, and 11. Each of these persons share the same link_val of 25238. Because there are three persons in the set, there are also three pairs. The first pair is for persons with ID values of 9 and 10. The second pair is for persons with ID values of 9 and 11. The last pair for the 25238 link_val is for persons with ID values of 10 and 11.

Next Steps
I hope you find this solution interesting whether or not you have a need exactly like the topic presented in the Problem. I regularly implement real-world business solutions like the ones described in this tip. However, even if you do not find yourself requiring this kind of solution, the tip still has value because it illustrates using subqueries and joins and WHERE clauses — techniques that you are likely to use in many different development applications. In addition, the tip demonstrates how you can use INNER JOIN and CROSS JOIN clauses more or less interchangeably to resolve the problem. Hopefully, the general approach and code discussed in this tip will get you thinking about non-standard ways of applying these T-SQL techniques in your own development work.
After you read the samples described in the tip, you can try out the code for either sample with the download for the article. The download for each sample includes an INSERT statement for loading the source data for a sample and a script for generating the derived result set.
Download the sample data and code for this tip.

Rick Dobson is a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been a practicing Python developer for more than the past half decade – with a special emphasis for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. If you are interested in growing your skills in any of these areas especially as they relate to financial securities, consider visiting his blog at https://securitytradinganalytics.blogspot.com/2023/12/.
- MSSQLTips Awards: Leadership (200+ tips) – 2025 | Author of the Year Contender – 2017-2024


