Problem
There are many tips and articles out there that solve SQL Server problems using a Numbers table as part of the solution – whether it be an explicit Numbers table, or a set derived from existing objects (like spt_values or sys.all_objects), or even a recursive CTE generated at runtime. But what exactly does the Numbers table do, how does it work, and why is it often better than iterative solutions?
Solution
I have been using and advocating Numbers tables for years – my first public article on the subject appeared when SQL Server 2000 was still “the latest release.” But I must confess, I haven’t put a whole lot of thought into relaying exactly how the table works, and how it can solve problems in very efficient ways.
The core concept of a Numbers table is that it serves as a static sequence. It will have a single column, with consecutive numbers from either 0 or 1 to (some upper bound). The upper bound, will depend on your business requirements. Here is sample output for the first few rows of a Numbers table:

Next, let’s look at the population of a Numbers table. There are many ways to do this; my favorite is to use a CROSS JOIN of system objects – this way whether I need a table with 100 rows or 100 million, I can generate those series without a whole lot of additional thought (and without loops, which will be a common theme here).
DECLARE @UpperBound INT = 1000000;
;WITH cteN(Number) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id]) - 1
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] INTO dbo.Numbers
FROM cteN WHERE [Number] <= @UpperBound;
CREATE UNIQUE CLUSTERED INDEX CIX_Number ON dbo.Numbers([Number])
WITH
(
FILLFACTOR = 100, -- in the event server default has been changed
DATA_COMPRESSION = ROW -- if Enterprise & table large enough to matter
);
This table stores a million rows in a little under 12 MB (a bit more if you can’t use compression). Note that the space used will be directly related to the upper bound you require, so don’t pick a higher number than you need. For most use cases, a million is probably overkill; I’ll try to indicate below how large the numbers table should be for that specific task. Here is a breakdown of size requirements for a few common sizes:
| Number Range | Size (KB) | |
|---|---|---|
| Uncompressed | Compressed | |
| 0 – 255 | 16 | 16 |
| 0 – 4,000 | 88 | 88 |
| 0 – 8,000 | 152 | 152 |
| 0 – 100,000 | 1,560 | 1,112 |
| 0 – 1,000,000 | 13,640 | 11,528 |
| 0 – 10,000,000 | 135,432 | 111,112 |
| 0 – 100,000,000 | 718,920 | 683,808 |
Interesting to note that compression made absolutely no difference until we got past 8,000 rows – and probably not enough difference to justify its use in any case. Also there was a slight saving if I forced the 4,000 or 8,000 row versions of the table to use SMALLINT, but not enough to justify the sacrifice in interoperability, since many of the functions used in combination will expect INT as input.
You may also consider using In-Memory OLTP for this table – you could make the durability schema only and populate the table in a startup procedure. You wouldn’t get all of the Hekaton benefits, since there is no write concurrency to handle, but you would get some. Alternatively, you could consider storing the table on a read-only filegroup (unless you think it is likely that your upper bound will change in the future). You can’t use both In-Memory OLTP and a read-only filegroup, though. :-)
Now that we have a Numbers table ready for use, let’s take a look at how the table can be used in simple, set-based queries.
Generating Sets
One common request I see is to generate a set of dates – given a start date and end date, I want to see each date in that range represented by a row. Let’s say we want a single resultset with a row for each day in January 2016. In a traditional looping approach, you would do something like this:
DECLARE @dates TABLE([Date] date);
DECLARE @StartDate date = '20160101', @EndDate date = '20160131';
WHILE @StartDate <= @EndDate
BEGIN
INSERT @dates([Date]) SELECT @StartDate;
SET @StartDate = DATEADD(DAY, 1, @StartDate);
END
SELECT [Date] FROM @dates ORDER BY [Date];
That is pretty straightforward logic, and returns the 31 days of January in the expected order:

But I dislike it for a couple of reasons – most importantly, the looping and incrementing, but also the fact that a table variable (or #temp table, or some other structure) has to be used to mask the row-by-row processing in order to return a single resultset. Let’s look at another common way people solve this problem, with a recursive CTE:
DECLARE @StartDate date = '20160101', @EndDate date = '20160131';
;WITH cteD([Date]) AS
(
SELECT [Date] = @StartDate
UNION ALL
SELECT DATEADD(DAY, 1, [Date]) FROM cteD
WHERE DATEADD(DAY, 1, [Date]) < @EndDate
)
SELECT [Date] FROM cteD
ORDER BY [Date]
OPTION (MAXRECURSION 3660); -- up to ten years
However, I shy away from the CTE approach for two reasons. One is that it is slightly unintuitive and hard to explain how it works. The other is that, as I’ve proven in the past, it does not scale well to larger sets. I tend to avoid solutions that I can only use in limited, low-row-count scenarios if I’m going to have to switch to other solutions at scale anyway.
So, I prefer to use the Numbers table for this, which – again in my experience – scales better than the recursive CTE and the loop, and is simpler than those solutions as well. This is also one case where having a 0 in the table can even further simplify the query. Essentially, I want to use the numbers to “increment” the date, starting at the start date, and adding first 0 days, then 1 day, then 2 days, and so on, until I’ve reached the end date. I can do this using a set-based approach as follows:
DECLARE @StartDate date = '20160101', @EndDate date = '20160131';
SELECT [Date] = DATEADD(DAY, Number, @StartDate)
FROM dbo.Numbers
WHERE Number <= DATEDIFF(DAY, @StartDate, @EndDate)
ORDER BY [Number];
The query adds 0, 1, 2, … 30 days to @StartDate; the upper bound of 30 is determined by the where clause, based on the number of days between the two variables. Let’s change the query slightly to output more columns to better illustrate what is happening:
DECLARE @StartDate date = '20160101', @EndDate date = '20160131';
SELECT
StartDate = @StartDate,
[Number],
[Date] = DATEADD(DAY, Number, @StartDate)
FROM dbo.Numbers
WHERE Number <= DATEDIFF(DAY, @StartDate, @EndDate)
ORDER BY Number;
Results:
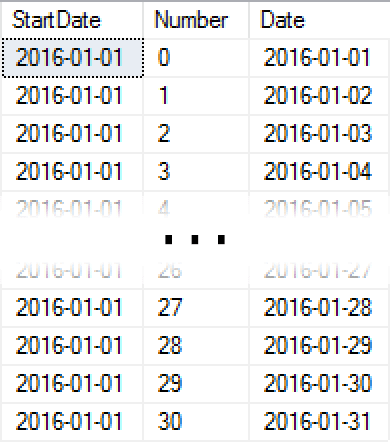
As you can see in the output, we’re simply taking each Number, adding that many days to @StartDate, and ending up with the sequence of dates in our desired range. This performs well because we can read the set of numbers we need with a very efficient range scan on the clustered index, starting right from the “beginning” of the table – and if you’re using the Numbers table enough, it will always be in memory.
Another way to express this is to instead use TOP, however in this case you need to add 1 to the day delta to include the last day in the range:
DECLARE @StartDate date = '20160101', @EndDate date = '20160131';
SELECT TOP (DATEDIFF(DAY, @StartDate, @EndDate) + 1)
[Date] = DATEADD(DAY, Number, @StartDate)
FROM dbo.Numbers
ORDER BY [Number];
These queries change slightly, of course, if your Numbers table starts at 1 instead of 0.
You can also use this to generate all kinds of other sequences. Time intervals, for example; provide a row for every 15 minutes of the day. The query logic remains largely the same:
SELECT [Interval] = CONVERT(time(0), DATEADD(MINUTE, Number * 15, '0:00'))
FROM dbo.Numbers
WHERE Number < 24*4
ORDER BY [Number];
Results:
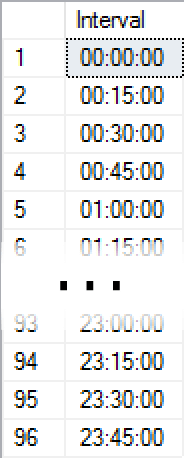
So, starting at midnight, add 15 minutes until we’ve reached 96 rows (4 rows per hour). Again, the query looks slightly different if your Numbers table is 1-based instead of 0-based:
SELECT [Interval] = CONVERT(time(0), DATEADD(MINUTE, (Number-1) * 15, '0:00'))
-- changed Number to (Number-1) -----------------^^^^^^^^^^
FROM dbo.Numbers
WHERE Number <= 24*4 -- changed < to <=
ORDER BY [Number];
How about something even simpler, like all of the upper case characters from A-Z?
SELECT Letter = CHAR(Number)
FROM dbo.Numbers
WHERE Number >= 65
AND Number <= 90
ORDER BY Number;
Results:
Letter ------ A B C ... X Y Z 26 row(s) affected.
For purposes like these, the upper bound of your Numbers table would have to cover the maximum number of date intervals or other values you need to produce. If you are producing dates, and your maximum date range is 10 years for a daily report, for example, you would need about 366 * 10 = 3,660 rows. A year-long report where every row represents a 10-minute slot would require 6 * 24 * 366 = 52,704 rows.
Conclusion
In this tip, I have explained the concept behind a Numbers table, showed an efficient way to populate it with your required set of numbers, and demonstrated how it can be used to generate a sequence of date or time intervals. In my next tip, I will show how you can use this table to find gaps in existing data, fill in gaps in reports, and explain how it helps with more advanced tasks like splitting strings.
Next Steps
- See these related tips and other resources:

Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He also blogs at sqlblog.org.
- MSSQLTips Awards: Author of the Year – 2016, 2023 | Leadership (200+ tips) – 2022


