Problem
We can enforce uniqueness of values in specific column(s) in a SQL Server table by creating a unique constraint or a unique index on those column(s). What’s the difference and how does SQL Server handle these differently?
Solution
Before getting started, let me briefly describe SQL Server unique indexes vs. unique constraints:
- A unique index ensures that the values in the index key columns are unique.
- A unique constraint also guarantees that no duplicate values can be inserted into the column(s) on which the constraint is created. When a unique constraint is created a corresponding unique index is automatically created on the column(s).
Let’s investigate these concepts with an example. First, let’s create a test environment:
USE master GO -- Creating database CREATE DATABASE TestDB GO USE TestDB GO -- Creating table CREATE TABLE TestTable ( ID INT, Value INT, NewValue INT, CONSTRAINT PK_TestTable_ID PRIMARY KEY (ID) ) GO
Creating a SQL Server Unique Index or Unique Constraint
Suppose we need to enforce the uniqueness of the data in the “Value” field in the TestTable. We can accomplish this with either SQL Server Management Studio (SSMS) or T-SQL code.
In SSMS we can right click on the table name, then choose “Design”, then right-click on the table design window and choose “Indexes/Keys” and add a new index on the “Value” column by choosing “Yes” in the “Is Unique” field as shown below:

In the screen shot above, we can see that for enforcing uniqueness we can choose either “Index” or “Unique Key” in the “Type” field. In both cases SQL Server by default creates a unique non-clustered index (if there is no clustered index on the table we can create a unique index/key as clustered) on the selected column(s). In this situation, the type of index does not impact the query plan selected by the SQL Server engine and there were no performance differences based on my testing.
However we can see that when we choose “Unique Key” some index creation options become unavailable (Ignore Duplicate Keys and Re-compute statistics):

If we choose “Index”, theses options are available:

Let’s do the same thing using T-SQL code (if you have saved the previous changes in SSMS, you need to drop the created index, so it can be created using T-SQL):
USE TestDB GO -- Creating unique index CREATE UNIQUE INDEX UIX_TestTable_Value ON TestTable(Value) GO --Creating unique constraint ALTER TABLE TestTable ADD CONSTRAINT UC_TestTable_NewValue UNIQUE (NewValue) GO
As a result we can see that there are two unique non-clustered indexes on the table TestTable:
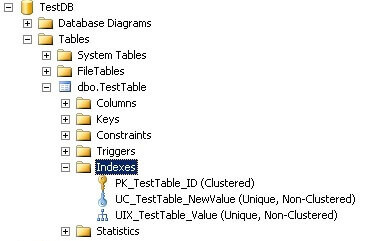
We can also see these indexes using T-SQL:
USE TestDB GO EXEC sys.sp_helpindex @objname = N'TestTable' GO

When creating a unique constraint with T-SQL, some index creation options are unavailable just like in SSMS. Here we will test this to see what happens.
USE TestDB GO -- Creating unique index CREATE UNIQUE INDEX UIX_TestTable_Value ON TestTable(Value) WITH IGNORE_DUP_KEY GO -- Creating unique constraint ALTER TABLE TestTable ADD CONSTRAINT UC_TestTable_NewValue UNIQUE (NewValue) WITH IGNORE_DUP_KEY GO
The first index creation statement succeeds and the index is created, but the second fails:

Dropping a SQL Server Unique Index or Unique Constraint
Now let’s try to drop these indexes:
USE TestDB GO -- Dropping indexes DROP INDEX TestTable.UIX_TestTable_Value GO DROP INDEX TestTable.UC_TestTable_NewValue GO
We can see that the first index has been deleted, however the second cannot be deleted with the “DROP INDEX” command and an error arises:

We need to first drop the unique key constraint:
USE TestDB GO --Dropping constraint ALTER TABLE TestTable DROP CONSTRAINT UC_TestTable_NewValue GO
Which automatically drops the corresponding index:

Disable a SQL Server Unique Constraint
Now let’s check if it is possible to disable a unique constraint. The following command disables all constraints on the “TestTable” table:
USE TestDB GO -- Creating unique constraint ALTER TABLE TestTable ADD CONSTRAINT UC_TestTable_NewValue UNIQUE (NewValue) GO -- Disabling all constraints ALTER TABLE TestTable NOCHECK CONSTRAINT ALL GO
We will try to insert a duplicate data into “NewValue” column:
USE TestDB GO -- Inserting duplicate data INSERT INTO TestTable(ID, Value, NewValue) VALUES(1, 1, 2) GO INSERT INTO TestTable(ID, Value, NewValue) VALUES(2, 2, 2) GO SELECT * FROM TestTable GO
The result shows that a “duplicate key violation” occurs:

Only the first row is inserted:

This means that disabling all constraints on the table does not refer to unique constraints. In other words it is not possible to insert duplicate data into the table by disabling a unique constraint.
Conclusion
Generally there is no functional difference between a unique index and a unique constraint. The latter is also listed as a constraint, however this is only a method to emphasize the purpose of the index. There is no difference for the query optimizer whether the index is created as a unique index or a unique constraint, therefore there is no performance difference. However there are some differences for creation where some index creation options are not available for unique constraints.
Next Steps
Read additional information:
- Create Unique Indexes
- UNIQUE Constraints
- Read more Indexing Tips
- Read more Constraint Tips

Sergey Gigoyan (LinkedIn) is a Senior Technical Architect specializing in data and databases with more than 15 years of experience. Sergey focuses on modern data architectures, database design and development, performance tuning and optimization, high availability solutions, BI development and DW design. He has worked with SQL Server, Oracle, and PostgreSQL databases, as well as cloud-based data solutions (AWS and Azure). Sergey also has extensive experience with modern data stacks such as Snowflake and dbt.
Sergey’s experience spans various industries. He had the privilege of working with IT giants such as Oracle as a Principal Data Engineer and BlackBerry as well as innovative startups. He helped deliver complex database solutions and advanced data strategies.
Sergey is also the author of “Building a Successful Career in IT – How I Did It” where he provides actionable advice on thriving in the ever-evolving IT industry.
- MSSQLTips Awards: Champion (100+ tips) – 2024 | Author of the Year – 2020


The biggest difference between unique constraints and unique indexes is that in a unique index can have covering non key columns (included columns) in the index but not with unique constraints.