Problem
You have been tasked with remodeling part of the production database following complaints about data integrity and poor performance. During your investigations, you find evidence of a poorly thought-out, denormalised design. What approach do you take to produce a more robust system?
Solution
This tip presents a database table containing approx. 25,000 rows with fictional products, sales and customer details mixed in multiple columns. The table is unnormalised and contains inconsistent data, no relations, and evidence of a number of other design anti-patterns. In this tip, we will step through initial assessment; entity-attribute identification; table redesign and table normalization, with the end result being a new set of database tables ready to accept data.
To keep our scope focused, this tip will not cover data migration, fixing data quality issues, writing new CRUD (CReate, Update, Delete) queries or optimizing query performance – these are actions that will depend heavily on your environment and on the application(s) using your tables, although there are sections near the end of this tip that discuss these issues.
If you would like to follow along, simply download and attach the SQL Server (2012) data file attached to this tip. Don’t attach this in production, and make sure you have permission from your DBA if necessary. For instructions on how to attach a database, see this advice from Microsoft: Attach a Database.
Introduction
Okay, let’s introduce the table. After some investigation of the data entry system, we have identified dbo.SalesTable as the core table where orders, customer details and products are recorded. Here is the definition:
USE [MSSQLTIPS] GO CREATE TABLE [dbo].[SalesTable]( [OrderNo] [varchar](40) NULL, [SaleDate] [varchar](14) NULL, [ProductID] [int] NULL, [ProductDescription] [varchar](100) NULL, [ProductTags] [varchar](500) NULL, [LineItemPrice] [numeric](16, 2) NULL, [TotalSalePrice] [numeric](16, 2) NULL, [CustomerName] [varchar](100) NULL, [CustomerAddress1] [varchar](100) NULL, [CustomerAddress2] [varchar](100) NULL, [CustomerAddress3] [varchar](100) NULL, [CustomerAddress4] [varchar](100) NULL, [CustomerAddress5] [varchar](100) NULL, [CustomerPhoneNo] [varchar](20) NULL, [CustomerEmail] [varchar](100) NULL, [RepeatCustomer] [varchar](3) NULL, [PromoCode] [varchar](20) NULL, [DiscountAppliedPc] [varchar](3) NULL, [DiscountAppliedAbs] [numeric](16, 2) NULL, [NewTotalSalePrice] [numeric](16, 2) NULL ) ON [PRIMARY]
Here’s what the data looks like when we query the top few rows:


Those with an eagle eye for detail can spot a number of problems already. Let’s take a quick look, column-by-column, working left-to-right:
- OrderNo is a GUID, but has a datatype of VARCHAR(40) instead of UNIQUEIDENTIFIER
- OrderNo is being used as a primary key but has no primary key constraint
- SaleDate is in a non-standard YYYYMMDDHHMMSS format
- SaleDate is being stored as a VARCHAR(14) instead of in a DATETIME format
- No relation to a products table is defined on ProductID
- ProductDescription contains NULLs
- ProductTags contains multiple data values in the same column separated by commas
- No relation to a tags table for ProductTags
- TotalSalePrice is duplicated for each line item
- All Customer details are duplicated for each line item
- CustomerAddress details are inconsistent – data in different columns
- Address is an attribute of customer but this attribute is spread over multiple columns according to a subtype of the data (more on this later)
- CustomerAddress5 is actually a postcode (UK version of ZIP code)
- No space to store countries for international orders
- CustomerPhoneNo is inconsistent, some containing spaces, and no country codes.
- CustomerEmail data duplicated for each line item too and is not tied to the customer data.
- RepeatCustomer field is populated ‘No’ for every customer’s first order (by SaleDate) and ‘Yes’ for other orders. These are difficult fields to maintain (more on why later)
- PromoCode, DiscountAppliedPc and DiscountAppliedAbs are largely NULL-populated
- NewTotalSalePrice is largely redundant, confusing and could lead to errors
In terms of design, the following problems can also be identified:
- NULL and empty strings are interchangeably used throughout the data set
- No keys or constraints on the table – although other tables like Products or Customers might exist, these aren’t evidenced in the design
- No primary key – table is a heap and therefore is at a performance disadvantage
- Mix-up of various entities means that CRUD (CReate, Update, Delete)-type queries run extremely slowly
- No indexing of any sort exists
- Updating a single field can mean updating multiple fields (i.e. updating a discount applied)
- No consistency of data over time (i.e. change in customers’ addresses)
Wow – that’s quite a few problems on a first pass, and we likely haven’t identified them all! Tables like this are more common in businesses than you might think. When working with data entry design tools (like, but not only, Microsoft Access) or when a development team design and implement a ‘quick n’ dirty’ web interface for information capture, getting the database design right can fall down the list of priorities in favor of fast deployment or application-side design concerns. It is very easy (and some DBAs would say prevalent) for tables like this to grow organically from a quick, basic solution to becoming the lynchpin of the application – and therefore critical for the business.
For an entertaining and relevant example of unchecked organic growth, check out this article from DailyWTF – it details a case where a bank used what became termed as the ‘Great Excel Spreadsheet’: http://thedailywtf.com/articles/The-Great-Excel-Spreadsheet. One particularly critical part had the comment ‘DO NOT EVER ATTEMPT TO CHANGE THIS CALCULATION! EVER!’ and the spreadsheet itself had a dedicated employee assigned to maintain it. This kind of ‘God object’ can occur quite quickly as code review and refactoring become less of a priority than shipping new features.
First Steps – Entity/Attribute Identification
Okay, this is one messy table. Let’s start by identifying the main features – the entities, and their attributes. If you’re unfamiliar with entities and attributes, think of them like this: an entity is a ‘thing’, and an attribute is something about that ‘thing’ which defines it. An instance of an entity is one particular example of the ‘thing’ which includes its attributes. Putting it in the context of cars: An entity could be called ‘car’. It has the attributes ‘make’, ‘model’, ‘year’, ‘color’, ‘engine size’. One instance of the car could be a ‘Ford Explorer’ with attributes ‘make: Ford’, ‘model: Explorer’, ‘year: 2009’, ‘color: red’ and ‘engine size: 2.0L’.
To relate this to databases – typically, an entity will have a database table. Each row in the table describes an instance of the entity. Each column in the table describes an attribute of the entity. Thus, each value in the table represents one attribute of one instance of the entity. This is the basis of the Entity-Attribute-Value (EAV) model.
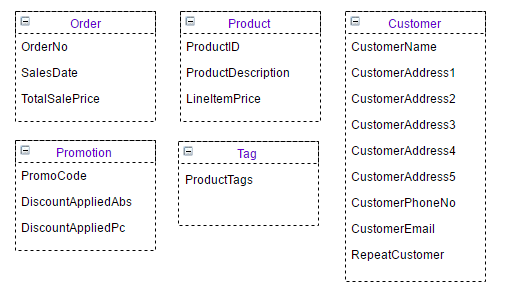
So let’s start to pick apart the dbo.SalesTable table using this model. Looking at the column data, we can see the following entities within the table. Below each entity, I have listed the attributes:
- Order
- OrderNo
- SaleDate
- TotalSalePrice
- PromoCode
- DiscountAppliedAbs
- DiscountAppliedPc
- TotalSalePrice
- Product
- ProductID
- ProductDescription
- ProductTags
- LineItemPrice
- Customer
- CustomerName
- CustomerAddress1
- CustomerAddress2
- CustomerAddress3
- CustomerAddress4
- CustomerAddress5
- CustomerPhoneNo
- CustomerEmail
- RepeatCustomer
Can we identify any other entities here? Let’s look at the Order, Product and Customer entity attributes and see if we can identify any ‘things’ within these attributes:
- Order
- OrderNo
- SaleDate
- TotalSalePrice
- Promotion
- PromoCode
- DiscountAppliedAbs
- DiscountAppliedPc
- Product
- ProductID
- ProductDescription
- Tag
- ProductTags
- LineItemPrice
- Customer
- CustomerName
- Address
- CustomerAddress1
- CustomerAddress2
- CustomerAddress3
- CustomerAddress4
- CustomerAddress5
- Address
- CustomerPhoneNo
- CustomerEmail
- RepeatCustomer
- CustomerName
We have identified three more entities; Promotion, Tag and Address. Why are these entities? Well, a promotion exists outside the dependence of a customer, a product or an order. A promotion could be described as a function which alters the price of an order or a product by a fixed value – it is an independent ‘thing’, so let’s model it as an independent entity.
A ‘tag’ is a classification (or an attribute) of a product. In our data set, we have tags such as ‘DIY’ or ‘Garden’. However, a tag could apply to multiple products, and a single product can have multiple tags. This is a many-to-many relationship, which means we should abstract the ‘tag’ concept away from the parent ‘Product’ entity and model it separately. But why? What happens if we don’t?
Well, this many-to-many relationship means we would need to define multiple tag columns (or attributes) in the product entity, and multiple product attributes in the tag entity. So instead of representing tag values (like DIY, Garden) as row values, we would need to represent them using columns like ‘tag1’ or ‘tag2’, or worse – by defining a series of columns for each unique tag value and assigning bitwise values to indicate whether they were in use. This is a particularly prevalent design antipattern that you may have seen before in production – if you haven’t, ask your DBA if you can take a look at your SharePoint database!
Address could be considered an entity in its own right. After all, an address is a ‘thing’ with attributes that include house number, postcode, country etc. However, addresses do tend to have a fixed, known number of attributes. It is often easier to represent these using multi-column attributes (CustomerAddress1, CustomerAddress2 …) than define a separate address table and use keys, because not all addresses are known beforehand. Inserting new addresses and defining a new key (then relating this back to other tables) in runtime is more difficult and computationally-costly than a straightforward INSERT operation to a Customer table. This, of course, has a downside – data quality issues! To read more about options to help counter these issues, see ‘Data Quality Services’ here: https://msdn.microsoft.com/en-us/library/ff877917.aspx and ‘Master Data Services’ here: https://msdn.microsoft.com/en-us/library/ee633763.aspx
So, for our solution, we shall disregard Address as an entity, instead amalgamating the Address attribute set into Customer. This is an example where to over-normalize could be counter-productive.
Normalization
This is a great opportunity to segue into the topic of normalization. Now we have defined our entities, we can test them against the rules of normalization to identify opportunities to improve the design and create loose coupling between our entities by reducing dependencies.
There are three main types (or degrees) of normalization. These are referred to as first normal form (1NF), second normal form (2NF) and third normal form (3NF). Each of these degrees of normalization are cumulative, i.e. 2NF encompasses the requirements of 1NF and 3NF encompasses the requirements of 1NF and 2NF. There are further normal forms available up to 6NF and some specialist branches such as BNF, BCNF and DKNF, but these are not covered here and are rare to find in production systems.
1NF
First normal form (1NF) has just two rules. Firstly, the domain of the values (the range of the values that are allowed for an attribute, or column) must contain only indivisible values. What does this mean? Essentially this means a set of values must contain only single values, not multiple values in the same field. Here’s an example:
- Column ‘CustomerName’ is divisible by three: First name, Middle Name, Surname
- Column ‘LineItemPrice’ is indivisible: the single value cannot be broken down into meaningful sub-values.
Let’s clear up a source of confusion here – ‘indivisible’ means in the context of the entity that we are defining. So if we don’t care about customer first or last names, a whole-name entry is permissible and would satisfy 1NF if we do not need to divide that data. Likewise, ‘CustomerAddress1’ might contain house number and street address, but do we need to divide this data? Not really, not in the context of our application. So keeping this data as one string would satisfy 1NF.
The second requirement of 1NF is that no existing values in the domain have multiple values from that domain. This is closely related to the first requirement, but is not the same. The first requirement says that fields with multiple values are not allowed within a domain – the second requirement says that fields with multiple values must not exist within a domain. Therefore 1NF can still be breached by a table definition even if multiple values do not exist within any field of the column, but they would be allowed. Looking at our entity attributes, we find the following attributes have multiple values per field:
- Customer -> CustomerName (first name, middle name, last name)
- Tag -> ProductTags (multiple tags per field separated by commas)
To satisfy 1NF, let’s address these problems. Let’s replace CustomerName with three attributes – First Name, MiddleInitial and LastName (we are replacing the middle name with the first initial of the middle name, since we don’t need the middle name data). ProductTags is more difficult – let’s replace this single attribute with two attributes of the entity ‘Tag’ – TagId and TagDescription. This yields the following amended EAV model:

2NF
Let’s go a stage further and get our model into 2NF. By making the changes above, we have altered our model to fit 1NF. 2NF encompasses this and adds one more rule, which can be difficult to understand – no non-key column can be dependent on any subset of the candidate key. To rephrase this, we can say that no column in a given table that isn’t part of a candidate key (a key that uniquely defines the row) can be dependent on part of that key.
This is tricky to understand but we can apply it to our model by examining each entity in turn:
- ORDER – OrderNo will be used as our key. SalesDate is not dependent on order, and nor is TotalSalePrice – these are attributes. However, TotalSalePrice is derived from the combined LineItemPrice of products that constitute an Order. This means we do need to link Products to Orders – more on this shortly. The table has a single primary key so is in 2NF.
- PROMOTION – PromoCode is our primary key, and the discount values depend wholly on the key, so this table does not breach 2NF as it doesn’t depend on part of the key.
- PRODUCT – ProductDescription and LineItemPrice depend wholly on the primary key, ProductID so this table is in 2NF.
- TAG – TagDescription is dependent on TagId, so this table is in 2NF.
- CUSTOMER – We have a problem here, the table does not have a primary key. It is conceivable we could create a composite primary key from First Name, MiddleInitial and Surname, but then we find that each part of that key is dependent on other parts of the key (First Name -> Surname, for example), breaching 2NF. Let’s create a primary key column, a surrogate key, for a customer. We will call it CustomerID. With this in place, all other columns become dependent on this key, so the table is in 2NF. We could equally use a natural key such as CustomerEmail, but this way is neater.
Before we come on to third normal form, let’s consider the problem we have just identified. By splitting out the Order Entity from the Product and Customer entities, we have lost the linkage which defines what products formed part of an order and which customer placed the order.
We could simply add the CustomerID and ProductID fields into the Order entity. But here’s the problem – although the relationship between a Customer and an Order is one to many, the relationship between an Order and a Product is many to many and thus needs to be broken out into another table. If we did not, an Order could not have more than one Product without duplication of the OrderID.
To associate this data, we must create an intermediary entity/table. Let’s call this ‘OrderDetails’ and define it with an OrderDetailID, ParentOrderNo, CustomerID and ProductID.
3NF
3NF is trickier to define. A table is in third normal form if and only if it is in 2NF and every attribute within the table depends on the key, and only on the key. Another way of stating this is that every non-key attribute in the table is not transitively dependent on the key, i.e. doesn’t depend on another attribute that depends on the key.
For example, imagine the Promotion table had a column called ‘DiscountType’ with domain [Percentage,Absolute]. This column might indicate, for each promo code, whether it applied a percentage discount or a fixed (absolute) discount. This isn’t a problem, but for the existence of DiscountAppliedAbs and DiscountAppliedPc. If we applied this column, DiscountAppliedAbs and DiscountAppliedPc would both depend on DiscountType which would depend on PromoCode, the key. This is not allowed under 3NF.
We do, however, need to consider a constraint here. Clearly both a percentage and absolute discount cannot concurrently apply to an order. Thus, DiscountAppliedAbs also has a dependency on DiscountAppliedPc and vice versa. This table met 2NF as neither of these columns form part of the primary key, but fails 3NF due to this cross-dependency with OR without our proposed ‘DiscountType’ column. Let’s refactor this table to have columns ‘PromoCode’, ‘DiscountType’ and ‘Amount’ instead, which is compliant with 3NF as both DiscountType and Amount depend on PromoCode only.
Another issue arises when considering promotions. We have lost the linkage that connects the promotion to the order. As a promotion applies to a whole order in our business model, not an individual product, we can put a column PromoCode in the Order table. If the opposite were the case, we would have to add a linkage from Product. Things would get even more complicated if multiple promotions applied to multiple product subsets and/or to specific categories of customer.
When considering Order, we have another potential issue with TotalSalePrice. This references the total value of the order before any promotional discount. If we add the ‘NewTotalSalePrice’ column in the original table, the NewTotalSalePrice becomes dependent on TotalSalePrice and PromoCode and hence breaks 3NF. We will remove TotalSalePrice entirely, since this is simply a function of the sum of the LineItemPrices in ProductID included in OrderDetail for a particular Order. We can calculate the TotalSalePrice as a view, if necessary, rather than a table as to do otherwise is unnecessary duplication of data. This kind of analysis belongs in derived tables.
Finally, we have no linkage between Product and Tag. Seeing as this is a many-to-many relationship, we need an intermediary table. We’ll call this ProductTagMap with columns ‘ProductTagID’ (PK), ‘ProductID’ and ‘TagID’. This table is compliant to 3NF.
Here’s our 3NF-compliant EAV model:

Datatypes
Let’s now consider datatypes. One of the problems identified with the original datatypes was that they were ill-fitted to the type of data being stored. For example, GUIDs were being stored as VARCHAR(40) occupying 40 bytes per value (1MB alone in the column for 25k values) rather than UNIQUEIDENTIFIER type which occupies 16 bytes (400KB). Even the latter type isn’t great – we could use INT values instead at 8 bytes per value. With a positive range of 0-2^32-1, this provides around 2.1bn different OrderNos at a mere 200KB storage for 25k values (1/5 of the current storage requirement). INTs are also faster to parse and sort upon than UNIQUEIDENTIFIERs within the query optimizer partly due to their sequentially.
Rather than examine each field one by one in this tip, let’s skip through these now and assign new, appropriate datatypes. We must make sure that fields which have a foreign key relationship have the same datatype as their keys.
Here is the typed model:

Keys and Constraints
Let’s now define our primary keys and foreign keys on the model. To display this clearly, we’ll rearrange a few of the entities on the page. We’ll also add a key column to indicate if an attribute is a key or not.
The keys we’ll define are below and indicated on the diagram at the end of this section.

Note that primary key columns and columns on which a foreign key is defined must be NOT NULL.
We are also going to make a couple of alterations to Customer: first, let’s change CustomerAddress5 to Postcode, to force the use of the column for postcode data. We will also add Country too. Now, Country is a great candidate to use as a key against a separate Country table – we could add a country code, and look up the Country name in a separate table. For the purposes of simplicity, we’re not using a separate table for this, no dependency on the table exists so we’re still in 3NF.
Finally, we need to consider what we might still be missing – looking at OrderDetails, we can see it consists entirely of foreign keys. What value does this table add to our model? Upon further consideration, we notice that the table contains a row per product associated with an order – but not the price of the product or the quantity. What if the price of a product changes in the Product table? This would invalidate any calculated price. So we need to store this data here, as it is temporal – i.e., the underlying field may change over time, so we need to capture the current state. Let’s amend Product -> LineItemPrice to be called Product -> LineItemBasePrice, and add ProductQuantity and ProductPrice to the OrderDetails table.
This yields the following final database model:

Creating the Objects
If you are using ERWin Data Modeler, you now have an option to generate this SQL syntax automatically to create your tables. Without this tool, we must write this SQL script ourselves. If you are following along, start with the CREATE TABLE statements, define all the columns, then datatypes, then NULL/NOT NULL constraints, then define the primary and foreign keys separately with named keys. Below is my version of the complete table generation script. You will also find the generated tables in the attached database data file.
USE MSSQLTIPS GO CREATE TABLE Customer ( CustomerID INT NOT NULL, FirstName VARCHAR(100) NOT NULL, MiddleInitial VARCHAR(1), LastName VARCHAR(100) NOT NULL, CustomerAddress1 VARCHAR(255), CustomerAddress2 VARCHAR(255), CustomerAddress3 VARCHAR(255), CustomerAddress4 VARCHAR(255), Postcode VARCHAR(10), Country VARCHAR(255), CustomerPhoneNo VARCHAR(25), CustomerEmail VARCHAR(255) NOT NULL, RepeatCustomer BIT ) GO ALTER TABLE Customer ADD CONSTRAINT pk_CustomerID_Customer PRIMARY KEY (CustomerID) GO CREATE TABLE Product ( ProductID INT NOT NULL, ProductDescription VARCHAR(500), LineItemBasePrice NUMERIC(16,2) ) GO ALTER TABLE Product ADD CONSTRAINT pk_ProductID_Customer PRIMARY KEY (ProductID) GO CREATE TABLE Tag ( TagID INT NOT NULL, TagDescription VARCHAR(100) ) GO ALTER TABLE Tag ADD CONSTRAINT pk_TagID_Tag PRIMARY KEY (TagID) GO CREATE TABLE Promotion ( PromoCode VARCHAR(10) NOT NULL, TypeOfDiscount CHAR(1), Amount NUMERIC(16,2) ) GO ALTER TABLE Promotion ADD CONSTRAINT pk_PromoCode_Promotion PRIMARY KEY (PromoCode) GO CREATE TABLE [Order] ( OrderNo INT NOT NULL, SalesDate DATETIME, PromoCode VARCHAR(10) NULL ) GO ALTER TABLE [Order] ADD CONSTRAINT pk_OrderNo_Order PRIMARY KEY (OrderNo) ALTER TABLE [Order] ADD CONSTRAINT fk_PromoCode_Promotion FOREIGN KEY (PromoCode) REFERENCES Promotion (PromoCode) GO CREATE TABLE ProductTagMap ( ProductTagID INT NOT NULL, ProductID INT, TagID INT ) GO ALTER TABLE ProductTagMap ADD CONSTRAINT pk_ProductTagID_ProductTagMap PRIMARY KEY (ProductTagID) ALTER TABLE ProductTagMap ADD CONSTRAINT fk_ProductID_ProductTagMap FOREIGN KEY (ProductID) REFERENCES Product (ProductID) ALTER TABLE ProductTagMap ADD CONSTRAINT fk_TagID_ProductTagMap FOREIGN KEY (TagID) REFERENCES Tag (TagID) GO CREATE TABLE OrderDetails ( OrderDetailID INT NOT NULL, ParentOrderNo INT NOT NULL, CustomerID INT NOT NULL, ProductID INT NOT NULL, ProductQuantity INT NOT NULL, ProductPrice NUMERIC(16,2) NOT NULL ) GO ALTER TABLE OrderDetails ADD CONSTRAINT pk_OrderDetailID_OrderDetails PRIMARY KEY (OrderDetailID) ALTER TABLE OrderDetails ADD CONSTRAINT fk_ParentOrderNo_OrderDetails FOREIGN KEY (ParentOrderNo) REFERENCES [Order] (OrderNo) ALTER TABLE OrderDetails ADD CONSTRAINT fk_CustomerID_OrderDetails FOREIGN KEY (CustomerID) REFERENCES Customer (CustomerID) ALTER TABLE OrderDetails ADD CONSTRAINT fk_ProductID_OrderDetails FOREIGN KEY (ProductID) REFERENCES Product (ProductID) GO
Data Validation
Now we have defined our new model, we must decide whether inbound data is to be validated at the application side or at the client side. The jury is still out on this – those who believe business logic resides at the application versus those who are happy to use SQL Server constraints.
If you are willing to use SQL Server constraints, here are a few that you might consider. Note that constraints you put on may make data migration (from old to new) more difficult!
- Replacing INT PKs with INT IDENTITY PKs (for auto-generated PKs)
- Valid sale date (CHECK)
- Valid promo code (CHECK)
- Product exists? (CHECK)
- Repeat customer? (Calculated / DEFAULT)
…
and so on. The amount of business logic, from nil to full, that could sit at this layer depends entirely on the requirements of the business. Bear this in mind when designing new systems – you may need to refer back to project specifications to ensure you know where the constraints are expected to be enforced.
Data Migration
Migrating the existing data is not within the remit of this tip (for reasons of brevity – otherwise it could turn into a book!) This can be considerably difficult, especially when working with data in disparate systems or patchy, incomplete data. There are a number of techniques to use, but best practice in data migration is largely absent and it will depend entirely on the systems which are being migrated and the techniques with which you are most comfortable.
To use our examples, we would look first at migrating the data into tables which do not have foreign key dependencies on other tables. In our model, these are Customer, Tag, Promotion, Product. Following on from this, we would then migrate into the remaining tables. Be careful – if you have multiple FK relationships chained together, ensure you start at the parent of the chain and work down the descendants.
One order in which we could migrate is:
CUSTOMER, TAG, PROMOTION, PRODUCT, PRODUCTTAGMAP, ORDER, ORDERDETAILS
In terms of timing and execution, it is best to develop and practice this kind of operation in a development instance and script everything. Once you’re happy it’s all working perfectly, only then schedule downtime on production and make sure you have a valid backup first! It’s quite common for 80% of effort in the data transformation/migration to happen automatically with the other 20% requiring human input, so it may take some time.
Another option you may consider is not migrating at all – simply starting a new set of database tables, and changing app-side code to write to these tables, and read from the existing SalesTable and our new tables. This approach can be messy, however, as two schemas need to run alongside for this to work effectively.
Or, you could write an ETL process in SSIS to migrate the data which can be a lot more friendly than writing T-SQL code to migrate. This has the advantage of various functions like diversion of rows which error to a separate workflow – these rows can be dealt with manually.
Data Quality
As discussed earlier, data quality issues can arise when investigating legacy data. Addresses are one great example – there are now standardized databases available for address data cleanup (in the UK, the ‘DA’ database from Royal Mail). Master Data Services is a service that may provide access to other address repositories.
Other issues with data quality – you may find that data is missing, or incorrect. When planning your data migration, take into account the range of values in each column – don’t assume that a VARCHAR(20) field marked ‘TotalPrice’ will always contain numeric data! SSIS again is great at this, able to divert rows with invalid values to separate workstreams.
Queries and Performance
One popular argument against normalization is that queries take longer to run and are more complex to write. The latter is certainly true, although the former is arguable. Normalization has many advantages including the benefit of scalability and a clear, logical separation which is easier to develop against, minimizing code smells and hacky code in production.
A full set of SELECT and CRUD queries is not provided here, but as an example of a SELECT and the performance implications, here is a query to fetch a list of customers who have made more than one order in January 2016. The list is in descending order by amount spent. This kind of list might be ideal to provide a list of likely targets for a marketing department looking to introduce a reward card scheme.
SELECT c.CustomerID, c.CustomerEmail, SUM(od.ProductPrice) [TotalValueOfOrders], COUNT(DISTINCT o.OrderNo) [NoOfOrders] FROM dbo.Customer c INNER JOIN dbo.[OrderDetails] od ON c.CustomerID = od.CustomerID INNER JOIN dbo.[Order] o ON od.ParentOrderNo = o.OrderNo INNER JOIN dbo.Product p ON od.ProductID = p.ProductID WHERE o.SalesDate BETWEEN '2016-01-01' AND '2016-02-01' -- YYYYMMDD format GROUP BY c.CustomerID, c.CustomerEmail HAVING COUNT(DISTINCT o.OrderNo) > 1 ORDER BY SUM(od.ProductPrice) DESC
As you can see, this query is not particularly complex. Let’s look at the equivalent query against dbo.SalesTable. We don’t have a CustomerID so we’ll have to leave this out:
SELECT s.CustomerEmail, COUNT(DISTINCT s.OrderNo), SUM(s.LineItemPrice) FROM dbo.SalesTable s WHERE CAST(LEFT(SaleDate,4) + '-' + SUBSTRING(SaleDate,5,2) + '-' + SUBSTRING(SaleDate,7,2) AS DATE) BETWEEN '2016-01-01' AND '2016-02-01' GROUP BY s.CustomerEmail HAVING COUNT(DISTINCT s.OrderNo) > 1 ORDER BY SUM(s.LineItemPrice) DESC
Comparing the costs in the execution plans, our normalized query has a total cost of 0.06 – and our query against the existing table has a cost of 0.7. This means our new query against our new model is over ten times less expensive to run, which will add up to great performance gains in production.
Next Steps
This tip has dealt with the problem of redesigning just one messy table. Of course, in real environments there are often many tables involved in sub-standard database designs and a fully normalized design may not be possible, for various reasons. Hopefully this tip has given you some ideas on how to refactor messy tables and start to construct scalable designs – good design principles should apply from the smallest to the largest databases.
I can heartily recommend the following books and online resources (including tips from other MSSQLTips authors) for further information:
- Karwin, B. ‘SQL Antipatterns’ (2010), Pragmatic, ISBN 978-1-93435-655-5
- K Brian Kelley, ‘Understanding First Normal Form in SQL Server‘, MSSQLTips
- Armando Prato, ‘Logical Design‘, MSSQLTips
- Davidson, L., ‘Pro SQL Server 2012 Relational Database Design and Implementation’ (2012), Apress, ISBN 978-1430236955
- Microsoft (Q283878 / KB283878), ‘Description of the database normalization basics’, https://support.microsoft.com/en-gb/kb/283878
- All SQL Server Database Design Tips

Dr. Derek Colley is the lead technical consultant for Optimal Computing, a boutique data consultancy based in the UK NW helping clients troubleshoot, configure, plan and deploy their data platforms. He specializes in data integration and database performance optimization, and is a PhD candidate with Staffordshire University, looking into methods of integrating AL query selection algorithms with the cost-based query optimizer. In his spare time, he enjoys building robots, going outdoors, and spending time with his four children.
- MSSQLTips Awards: Trendsetter (25+ tips)


