Problem
Unique identifiers are one of the fundamental blocks of data modeling and well as data consumption. Every table modeling starts with a unique business key / identity key / surrogate key, etc. The impact of a unique identifier becomes more evident when the need is to consolidate common business entities for purposes like data warehousing and analytics. If the identifiers are unique within datasets, but not across datasets, this can become a data processing bottleneck. In case of merger and acquisition scenarios, data gets consolidated at a massive level across organizations and duplicate identifiers can pose significant challenges. The need is to have unique identifiers that can remain unique within the dataset, across datasets and even across organizations. In this tip, we will understand the mechanism to address the problem in question.
Solution
A GUID in SQL Server can generate unique IDs with the least probability of the exact ID being generated and/or used by someone else coincidently.
Before we dive into understanding the way of generating GUIDs in SQL Server, it’s necessary to understand some important concepts about GUID itself. So, let’s understand GUID conceptually.
- Unique Identifiers are broadly defined by two acronyms – GUID (Globally Unique Identifier) and UUID (Universally Unique Identifier). Both represent the same thing – unique IDs that are unique across space and time.
- The specification and the methodology of generating GUIDs is defined by IETF and the specification is known as RFC4122.
- GUIDs can be generated in multiple ways. The most common ones are based on Random number generation, Time clock sequence, Hardware based using MAC addressed of network cards, and Content based by calculating hash of the data using common hashing algorithms like MD5, AES, SHA and others.
- GUIDs are typically 128-bit in size and 32 digits long in the pattern of 8 digits – 4 digits – 4 digits – 4 digits – 12 digits
- Using the above mechanism, a total of approximately 1038 GUIDs can be generated, which are more than enough for everyone in the world to use GUIDs for trillions of data items per person.
Now that we have enough understanding of GUIDs, we can start focusing on the methods of creating GUIDs in SQL Server. There are two functions using which you can create GUIDs in SQL Server – NewID and NewSequentialID. And there’s a data type – "uniqueidentifier" which can be used to store GUIDs. It stores a 16-btye binary value.
SQL Server NEWID to Generate GUID
Let’s create a variable of uniqueidentifier data type. Type the below code in SSMS and execute.
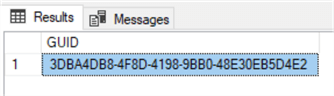
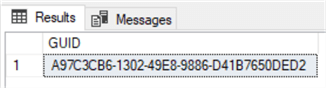
DECLARE @guid uniqueidentifier = NEWID SELECT @guid as 'GUID'
Here we created a variable named guid of data type uniqueidentifier. To generate a unique identifier, we need to assign a default method of creating it, and for that we have used the NEWID function which generates and returns a RFC4122 compliant GUID. The output of the above code would be as shown below. This would be different when you execute it on your machine, as the GUIDs are supposed to be globally unique at any given point in time. In fact, I executed the same code twice and each time the ID that came out was different as expected. This is the entire purpose of generating GUIDs.
While creating a new table, you can create a field of uniqueidentifer data type as assign the NEWID as the default function as shown below.
CREATE TABLE Product_A ( ID uniqueidentifier default newid(), productname varchar(50) )
Insert some records into this table using the below code.
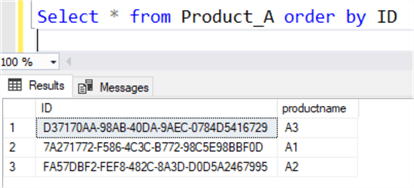
Insert Into Product_A(productname) values('A1') Insert Into Product_A(productname) values('A2') Insert Into Product_A(productname) values('A3') Select * from Product_A
The output would be as shown below.

One thing to note is regarding different operations that you can perform on GUIDs / uniqueidentifier data type. If you sort the ID field in the above table, the result is as shown below in my case. The IDs generated are not necessarily in increasing order, so if you sort the data by GUIDs, the data may not be in the same order in which you inserted. SQL Server sorts GUIDs typically from the 5th part of the GUID towards the 1st part, and the search algorithm is not well documented. The NewID function used randomness (random activity) as part of its GUID generation mechanism, so it cannot be guaranteed that every GUID that is generated would be in sequence or in order of higher values.
Also, only comparison operators are supported on GUIDs. For example, if you attempt to use an aggregation operator like sum, you would encounter an error as shown below.

SQL Server NEWSEQUENTIALID to Generate GUID
Let’s look at another GUID function available in SQL Server – NEWSEQUENTIALID. This function creates a GUID that is greater than any GUID previously created by this function on the same machine since Windows started. This mechanism of generating continuously higher values is a great fit when GUIDs are being used as row identifiers. Let’s test this characteristic of newsequentialid function.
Create a new table Product_B and execute the same steps that we did for the Product_A table. The only change to be done is that instead of newid function, use the newsequentialid function. The result should be like the one shown below.

When you query this new table and sort it by ID field, the result would be in the same order in which you inserted the data in the table. The reason is that newsequentialid function does not use randomness as part of the GUID generation, still ensuring that the ID is globally unique and greater than the last generated value on the same machine.

Consider if we had inserted data in two different products table, and these tables were owned by two different departments where both started their IDs from 1, 2 and 3. If we would have considered merging data from both the tables by using an operator like Union or loading data from both tables into a third common table having ID as the primary key, it would have generated errors as the data would have duplicate row identifiers.
In our case, this would not be a concern as the IDs are supposed to be globally unique and you can easily merge this data in a query or in a table or anywhere else globally. If my case, when I attempted to join the data from two tables in a common resultset using the Union operator, the result came out as shown below. Rows 2, 3, and 4 are from table B in a sequence as they were generated by the newsequentialid function. In contrast, the newid function generated GUIDs quite randomly, and values were higher and lower than the ones created by the newsequentialid function.

Both functions serve different use-cases where you may want to create GUIDs randomly or in-sequence. GUID is not always the best fit for use as an identifier. For example, for a 6-byte sized row, you may not want to use a 16-bit GUID as an identifier. As GUID is quite large in terms of its size, its recommended to consider evaluating other data types and use a GUID for selective scenarios where other data types like int, long and others cannot serve the purpose.
Next Steps
- Consider exploring more about new UUID from here.

Siddharth has more than 14 years of experience in the IT Industry, with more than a decade of experience in Business Intelligence and Analytics, for clients banking, logistics, government, Media Entertainment, products, life sciences and other domains. He has been a lead architect for a portfolio of 40+ apps, containing apps in web, mobile, BI, Analytics, data warehousing, reporting, collaboration, CMS, NoSQL and other technologies. He has several certifications and is a published author for online and print-media publications, as well as the MSDN Library.
In his present role, he remains responsible for architecture design, technology stack selection, infrastructure design, 3rd party products evaluation and procurement, and performance engineering. These applications use technologies like Elasticsearch / Lucene, MongoDB, SharePoint 2013 and 2010, jQuery-based framework like Highcharts and GoJS, SQL Server and the Microsoft Business Intelligence stack (SSIS, SSAS, SSRS, MDX, PowerPivot, PowerView), jQueryMobile, Bootstrap, iOS xCode framework, and many others.
- MSSQLTips Awards: Champion (100+ tips) – 2018 | Author of the Year – 2017 | Author Contender – 2016, 2018-2019


