Problem
For SQL Server database professionals a common task is synchronizing data between two tables. There are different ways of implementing a solution in SQL Server such as Change Data Capture or Change Data Tracking, replication, using triggers and so on. However, there are some situations when the above solutions are not applicable. For example source and destination tables are located in database systems from different vendors (for example Sybase and SQL Server).
Suppose, we have two tables in two different databases and the data in these tables needs to be fully synchronized. We can compare the data in these tables, update existing rows and add new rows. However, comparing all of the data in the tables is not an effective way and it would be better if we can detect changes in the source table and only apply these changes to the target. This problem can be solved by using the SQL Server rowversion data type.
Solution
In this article we’ll look at the rowversion data type and see how it can be used in data synchronization.
The values for a rowversion data type are automatically generated binary numbers which take 8 bytes of storage and are unique within a database. A non-nullable rowversion column is semantically equivalent to a binary(8) column and a nullable rowversion column is semantically equivalent to a varbinary(8) column. Columns with a rowversion data type are generally used for detecting changes in the row. You can have only one rowversion column in a table. When data is inserted or updated in a table that has a rowversion column, the database counter called the database rowversion is incremented. This incremented value is set as the value for the rowversion column for updated or inserted rows.
SQL Server rowversion Overview
Let’s create a sample database:
USE master GO CREATE DATABASE TestDB GO
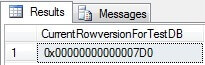
We can get the database’s current rowversion value with this query:
USE TestDB GO SELECT @@DBTS AS CurrentRowversionForTestDB
The result is the following:
Here are a few things to note. A timestamp data type is a synonym for rowversion. When we create a table with a column using a rowversion data type using T-SQL and then look at that column in SQL Server Management Studio (SSMS), we can see that the data type of column is timestamp:
USE TestDB GO CREATE TABLE TestTableA ( ID INT, Value INT, LastChange ROWVERSION ) GO

If we try to add a column with a rowversion data type in SSMS, we will notice that there is no rowversion in the data type list as shown below. The only choice is timestamp.

It is possible to create a table with a timestamp column without mentioning the column name and it will be automatically generated:
USE TestDB GO CREATE TABLE TestTableB ( ID INT, Value INT, TIMESTAMP ) GO

However, if we try this with rowversion we get an error:
USE TestDB GO CREATE TABLE TestTableC ( ID INT, Value INT, ROWVERSION )

Microsoft recommends using rowversion instead of timestamp in DDL statements, because the timestamp will be deprecated in future versions.
Example Using SQL Server rowversion
Let’s use the above created TestTableA to demonstrate the rowversion data type behavior. We will insert data into TestTableA table and we will see the values in the LastChange column:
USE TestDB GO SELECT @@DBTS AS DatabaseRowversion INSERT INTO TestTableA (ID, Value) VALUES(1, 2), (2, 2), (3, 3) SELECT * FROM TestTableA SELECT @@DBTS AS DatabaseRowversion
As we can see, the values have automatically been generated and the last one is the same as the databases current rowversion:

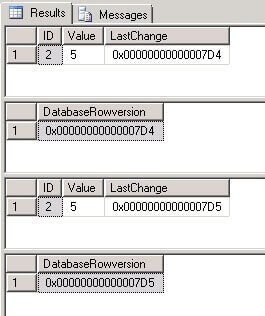
Now when we update the row, we can see that the value in the “LastChange” column for that row has changed:
USE TestDB GO SELECT @@DBTS AS DatabaseRowversion SELECT * FROM TestTableA WHERE ID=2 UPDATE TestTableA SET Value=5 WHERE ID=2 SELECT * FROM TestTableA WHERE ID=2 SELECT @@DBTS AS DatabaseRowversion

It is also important to note that after an update where the values have not been changed, the rowversion does still change:
USE TestDB GO SELECT * FROM TestTableA WHERE ID=2 SELECT @@DBTS AS DatabaseRowversion UPDATE TestTableA SET Value=Value WHERE ID=2 SELECT * FROM TestTableA WHERE ID=2 SELECT @@DBTS AS DatabaseRowversion
Detecting changes and updating target table
Now it’s is time to explore data synchronization using the rowversion data type using a simple example. Let’s assume that we have two tables – source and target – data on the target table needs to be periodically synchronized with data on the source table (it is assumed that the data in source table does not get deleted):
USE master GO --Creating databases CREATE DATABASE SourceDB GO CREATE DATABASE TargetDB GO --Creating tables USE SourceDB GO CREATE TABLE SourceTable ( ID INT IDENTITY(1,1), Value INT, LastChange ROWVERSION NOT NULL, CONSTRAINT PK_SourceTable_ID PRIMARY KEY CLUSTERED (ID) ) USE TargetDB GO CREATE TABLE TargetTable ( ID INT, Value INT, LastChange BINARY(8) NOT NULL, CONSTRAINT PK_TargetTable_ID PRIMARY KEY CLUSTERED (ID) )
We can see that “LastChange” column in the source table is created as a rowversion data type and the corresponding column in the target table is created as a binary(8) data type. The following code inserts data into the source table:
--Inserting data into the source database USE SourceDB GO INSERT INTO SourceTable(Value) VALUES(1),(2),(3),(4),(5) SELECT * FROM SourceTable SELECT @@DBTS AS SourceDBRowversion SELECT MAX(LastChange) AS MaxValueOfLastChange FROM SourceTable

Now we will synchronize data in the target and source tables. In order to not compare all of the data in the source and target tables, we will insert only changed data after the last synchronization from the source to the target table. To identify these changes, we will use the data in the “LastChange” column in the following way: first, we will find the maximum value in the “LastChange” column in the target table. After that we will choose only the rows from the source table where the value in the “LastChange” column is greater than the maximum value of the “LastChange” column in the target table and finally we will update the target table by using these rows from the source table. In this way we do not update rows on the target which have not changed in the source table after the last synchronization. We will use the MERGE command to implement this data synchronization process:
USE TargetDB
GO
--Data in TargetTable before update
SELECT *
FROM TargetTable
DECLARE @lastChange AS BINARY(8)
SET @lastChange=(SELECT MAX(LastChange) FROM TargetTable)
--Updating data in TargetTable table, merging by SourceTable table
MERGE TargetTable AS target
USING ( SELECT ID, Value, LastChange
FROM SourceDB.dbo.SourceTable o
WHERE LastChange > ISNULL(@lastChange,0)
) AS source
ON target.ID = source.ID
WHEN MATCHED AND ISNULL(target.Value,0)<>ISNULL(source.Value,0)
THEN UPDATE SET target.Value = source.Value, target.LastChange=source.LastChange
WHEN NOT MATCHED
THEN INSERT (ID, Value, LastChange)
VALUES(source.ID, source.Value, source.LastChange)
;
--Data in TargetTable after update
SELECT *
FROM TargetTable
After running this command for the first time in our test environment, all of the data in the source table will be inserted into the target table, because the target table is empty:

Now let’s do some updates in the source table:
--Inserting data into the source database USE SourceDB GO INSERT INTO SourceTable(Value) VALUES(6),(7),(8),(9),(10) UPDATE SourceTable SET Value=55 WHERE ID=5
After that let’s run the merge command again:
USE TargetDB
GO
DECLARE @lastChange AS BINARY(8)
SET @lastChange=(SELECT MAX(LastChange) FROM TargetTable)
--Updating data in TargetTable table, merging by SourceTable table
MERGE TargetTable AS target
USING ( SELECT ID, Value, LastChange
FROM SourceDB.dbo.SourceTable o
WHERE LastChange > ISNULL(@lastChange,0)
) AS source
ON target.ID = source.ID
WHEN MATCHED AND ISNULL(target.Value,0)<>ISNULL(source.Value,0)
THEN UPDATE SET target.Value = source.Value, target.LastChange=source.LastChange
WHEN NOT MATCHED
THEN INSERT (ID, Value, LastChange)
VALUES(source.ID, source.Value, source.LastChange)
;
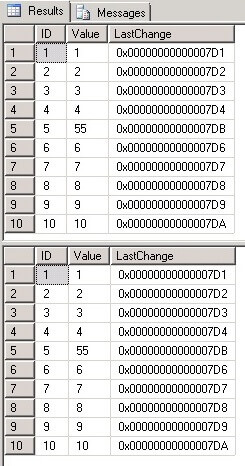
We will see that all changes made in source table are applied to the target and now the SourceTable and TargetTable tables are fully synchronized:
USE SourceDB GO SELECT * FROM SourceTable USE TargetDB GO SELECT * FROM TargetTable
Conclusion
To automate this data synchronization process you can create a synchronization script, stored procedure or SSIS package that runs on a predefined schedule.
All in all, the rowversion (timestamp) data type is very useful to detect data changes. They are synonymous data types, however as we can see in this tip, there are some differences between choosing one of them during implementation. Also, Microsoft recommends to use rowversion instead of timestamp, because it will be deprecated in future versions. Using the rowversion data type to track changes can be the best solution, especially when other solutions are not applicable to the given task. This method is often used in loading data warehouses.
Next Steps
Review this related information:
- https://msdn.microsoft.com/en-us/library/ms182776.aspx
- https://msdn.microsoft.com/en-us/library/ms182776(v=SQL.90).aspx
- https://msdn.microsoft.com/en-us/library/ms187366.aspx
- https://msdn.microsoft.com/en-us/library/bb933994.aspx

Sergey Gigoyan (LinkedIn) is a Senior Technical Architect specializing in data and databases with more than 15 years of experience. Sergey focuses on modern data architectures, database design and development, performance tuning and optimization, high availability solutions, BI development and DW design. He has worked with SQL Server, Oracle, and PostgreSQL databases, as well as cloud-based data solutions (AWS and Azure). Sergey also has extensive experience with modern data stacks such as Snowflake and dbt.
Sergey’s experience spans various industries. He had the privilege of working with IT giants such as Oracle as a Principal Data Engineer and BlackBerry as well as innovative startups. He helped deliver complex database solutions and advanced data strategies.
Sergey is also the author of “Building a Successful Career in IT – How I Did It” where he provides actionable advice on thriving in the ever-evolving IT industry.
- MSSQLTips Awards: Champion (100+ tips) – 2024 | Author of the Year – 2020



Thanks for the helpful article. I agree that the method is really useful. I also recommend reading this article on the topic.