By: Aaron Bertrand | Comments (3) | Related: More > DBA Best Practices
Problem
In a previous tip, Using schema binding to improve SQL Server UDF performance, Atif Shehzad showed us that using the WITH SCHEMABINDING option for a scalar function without table access can improve performance, as SQL Server knows that it doesn't need to introduce Halloween protection (which Paul White explains in further detail here, Craig Freedman provides some background on here, and the SQL Server Programmability Team has a blog post about here).
Aside from improved performance gained from avoiding Halloween protection, what other benefits can I get by using WITH SCHEMABINDING?
Solution
In addition to functions, WITH SCHEMABINDING can also be used with views and stored procedures, and there can be tangible benefits there that don't involve performance. Mainly these revolve around either preventing unauthorized or inadvertent changes, or preventing unexpected results.
Preventing Unauthorized/Inadvertent Changes
You can use WITH SCHEMABINDING on any module to prevent any inadvertent modifications to the objects referenced by the module. So, for example, if you have a function that relies on the data type of a column in a table, you can use WITH SCHEMDABINDING to ensure that the table doesn't change. Without SCHEMABINDING, the following scenario is possible:
CREATE TABLE dbo.ProductStatus ( StatusID tinyint, Label nvarchar(32), Enabled bit ); GO CREATE FUNCTION dbo.GetProductStatusLabel ( @StatusID tinyint ) RETURNS nvarchar(32) AS BEGIN RETURN (SELECT Label FROM dbo.ProductStatus WHERE StatusID = @StatusID); END GO -- now someone else comes along and: ALTER TABLE dbo.ProductStatus ALTER COLUMN StatusID bigint; ALTER TABLE dbo.ProductStatus ALTER COLUMN Label nvarchar(64);
Those changes - which may be made for very valid reasons - can break subsequent calls to the function, and that might not be obvious during regression tests (especially if nobody has inserted a StatusID > 255 or a Label > 32 characters). However, if the function is created WITH SCHEMABINDING:
CREATE FUNCTION dbo.GetProductStatusLabel ( @StatusID tinyint ) RETURNS nvarchar(32) WITH SCHEMABINDING AS BEGIN RETURN (SELECT Label FROM dbo.ProductStatus WHERE StatusID = @StatusID); END GO
You get an error message for either of the ALTER commands, e.g.:
The object 'GetProductStatusLabel' is dependent on column 'StatusID'.
Msg 4922, Level 16, State 9
ALTER TABLE ALTER COLUMN StatusID failed because one or more objects access this column.
In order to change the table, you'd have to modify the function to not use WITH SCHEMABINDING, then change the table, then modify the function again, to both reflect the new data types and to once again use WITH SCHEMABINGINDING:
ALTER FUNCTION dbo.GetProductStatusLabel ( @StatusID tinyint ) RETURNS nvarchar(32) --WITH SCHEMABINDING AS BEGIN RETURN (SELECT Label FROM dbo.ProductStatus WHERE StatusID = @StatusID); END GO ALTER TABLE dbo.ProductStatus ALTER COLUMN StatusID bigint; ALTER TABLE dbo.ProductStatus ALTER COLUMN Label nvarchar(64); GO ALTER FUNCTION dbo.GetProductStatusLabel ( @StatusID bigint ) RETURNS nvarchar(64) WITH SCHEMABINDING AS BEGIN RETURN (SELECT Label FROM dbo.ProductStatus WHERE StatusID = @StatusID); END GO
In this case, changes could be made to the other column that the function doesn't reference:
ALTER TABLE dbo.ProductStatus ALTER COLUMN Enabled int; -- success
A similar scenario exists with indexed views. WITH SCHEMABINDING is one of the requirements for an indexed view, for precisely this reason: Changes to the referenced columns in the underlying table can't be made while the indexed view is in place. This is an important thing to keep in mind when creating indexed views; they will have to be dropped and re-created if any columns need to change. The reason this is important is that this can be a much more disruptive change than altering a module.
Preventing Unexpected Results
I have an interesting example of unexpected results that I use in one of my presentations, and the situation could be completely avoided by using WITH SCHEMABINDING. Imagine you have a table with three columns, an int, a datetime, and a string:
CREATE TABLE dbo.SillyTable ( col1 int, col2 datetime, col3 varchar(32) ); INSERT dbo.SillyTable(col1, col2, col3) VALUES (1,'20000101','a'),(2,'20100101','b'),(3,'20150101','c');
Now, you have created a view that simply uses SELECT *:
CREATE VIEW dbo.SillyView AS SELECT * FROM dbo.SillyTable; GO
You've written an application that references the view, and maybe built other views on top of it. Now, someone comes along and makes bizarre but possible changes to the underlying table:
ALTER TABLE dbo.SillyTable DROP COLUMN col3; ALTER TABLE dbo.SillyTable ADD col4 datetime NOT NULL DEFAULT SYSDATETIME(); EXEC sys.sp_rename N'dbo.SillyTable.col1', N'col3', N'COLUMN'; EXEC sys.sp_rename N'dbo.SillyTable.col2', N'col1', N'COLUMN'; EXEC sys.sp_rename N'dbo.SillyTable.col4', N'col2', N'COLUMN';
Now your application, those other views, and even ad hoc queries don't look quite right, and in some cases will just outright break. Look at the results of these two queries:
SELECT col1, col2, col3 FROM dbo.SillyTable; SELECT col1, col2, col3 FROM dbo.SillyView;
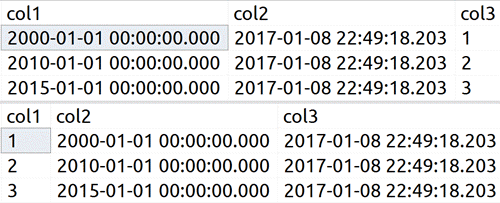
That's not good, right? That's just all kinds of messed up. What is happening is that the view is still referencing the old metadata for the columns, and so is returning data based on column ordinal, not column name.
We can fix this easily enough after the fact, using sp_refreshview:
EXEC sys.sp_refreshview N'dbo.SillyView';
But in this case, applying WITH SCHEMABINDING accomplishes two positive things: It prevents these columns from being changed under the view, and it prevents the bad habit of using SELECT *.
If we try to create a view that uses SELECT *, and apply WITH SCHEMABINDING:
CREATE VIEW dbo.SillyView2 WITH SCHEMABINDING AS SELECT * FROM dbo.SillyTable;
We get this error:
Syntax '*' is not allowed in schema-bound objects.
And of course when we fix that:
CREATE VIEW dbo.SillyView2 WITH SCHEMABINDING AS SELECT col1, col2, col3 FROM dbo.SillyTable;
If we try to drop or rename any columns from the view, we get these error messages:
Msg 5074, Level 16, State 1
The object 'SillyView2' is dependent on column 'col1'.
Msg 4922, Level 16, State 9
ALTER TABLE DROP COLUMN col2 failed because one or more objects access this column.
-- try to rename a column
Msg 15336, Level 16, State 1, Procedure sys.sp_rename
Object 'dbo.SillyTable.col1' cannot be renamed because the object participates in enforced dependencies.
Performance Troubleshooting
Okay, I said non-performance-related benefits, but there may be cases where Halloween protection is in place, causing a more expensive DML plan, but it is not obvious to the person trying to troubleshoot performance. So it is important to be able to identify that this might be the cause - as Paul White explained at the end of his last post on the Halloween problem, this protection "will not always show up as an extra Eager Table Spool, and scalar function calls may be hidden in views or computed column definitions, for example."
Summary
I am a big fan of SCHEMABINDING, and there are no valid downsides I can think of to always use WITH SCHEMABINDING on relevant functions and views. Some will say that having to touch additional modules to make changes to a single object might be a downside, but I don't see it that way at all. In fact I think it is essential to be forced to take all of these dependent objects into account before making a schema change of any kind. And in some cases, you will just happen to enjoy performance benefits as well.
Next Steps
- See these tips and other resources:






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
