Problem
I have a SQL Server user database with single file group containing two data files. If I were to insert 1GB worth of data into this database, does it mean each data file will always get 500MB worth of data because of Proportional Fill algorithm in SQL Server?
Solution
The problem description misunderstood the Proportional Fill algorithm implementation in SQL Server. Proportional Fill algorithm works based on free space and not about distributing equal amounts of data across data files as mentioned in the problem description.
For example, if you have a single file group containing two data files, each data file is 1GB is in size. Next you perform a data insertion which will require 1GB of database data space. After the data insertion is complete, you will notice that each data file will show its used data space as 500MB.
In another scenario, you now have a single file group containing two data files. The first data file size is 1GB and the second data file size is 2GB. With the Proportional Fill algorithm, it means when the SQL Server Storage Engine allocates extents, for every one extent allocated to the first data file, two extents will be allocated to the second data file in a round robin fashion. This round robin and Proportional Fill algorithm ensures the database data files in the file group will become full at approximately the same time weighing the individual data file size.
To demonstrate the scenario outlined in the second example, we will build an example and chart the database data files usage as a percentage. All the T-SQL scripts in this example are executed on SQL Server 2016 Developer Edition SP1.
Step 1 - Create a SQL Server user defined database
A SQL Server user defined database is created with a secondary file group “PF” containing two data files with different sizes. The first data file “File1” size will be 1GB, and the second data file “File2” size will be 2GB. The secondary file group “PF” will be set as the default file group.
USE master
GO
CREATE DATABASE [ProportionalFill]
CONTAINMENT = NONE ON PRIMARY
(NAME = N'ProportionalFill’, FILENAME = N'D:\SQLDATA\ProportionalFill.mdf', SIZE = 8196KB, FILEGROWTH = 65536KB),FILEGROUP [PF]
(NAME = N'File1', FILENAME = N'D:\SQLDATA\File1.ndf’, SIZE = 1024000KB, FILEGROWTH = 65536KB),
(NAME = N'File2', FILENAME = N'D:\SQLDATA\File2.ndf’, SIZE = 2048000KB, FILEGROWTH = 65536KB),
LOG ON
(NAME = N'ProportionalFill_log’, FILENAME = N'E:\SQLLOG\ProportionalFill_log.ldf’, SIZE = 1048576KB, FILEGROWTH = 65536KB)
GO
ALTER DATABASE [ProportionalFill} MODIFY FILEGROUP [PF] DEFAULT
GO
ALTER DATABASE [ProportionalFill] SET RECOVERY SIMPLE
GO
Step 2 - Check the initial SQL Server file group space utilization
When the data files in file group PF are created initially without any data, the amount of space utilization on both data files are the same. The query below provides the data file used space in MB for data file File1 and data file File2 in file group PF. The ID column is just a next numbering to capture the data file usage at every 1 second interval in the later step.
USE [ProportionalFill]
GO
SELECT 1 ID, (
SELECT
CASE WHEN f.fileid = 3
THEN CAST(FILEPROPERTY(f.name, 'SpaceUsed')/128.0 AS DECIMAL(10,2))
ELSE 0 END
FROM sysfiles f
WHERE f.groupid = 2 and f.fileid = 3
) AS [File1 Space Used in MB], (
SELECT
CASE WHEN f.fileid = 4
THEN CAST(FILEPROPERTY(name, 'SpaceUsed')/128.0 AS DECIMAL(10,2))
ELSE 0 END
FROM sysfiles f
WHERE f.groupid = 2 and f.fileid = 4
) AS [File2 Space Used in MB]
INTO ##temp
GO
Step 3 - Populate data files in the “PF” SQL Server file group
We will now prepare an insert script into a table residing on file group PF. A single data page in SQL Server is 8KB, so 380,000 data pages is approximately 3GB. For one row to occupy a single data page, we will just define one of the columns in the table definition to use CHAR(7000) as shown below.
CREATE TABLE ProportionalFill.dbo.mssqltips (COL1 INT IDENTITY(1,1), COL2 CHAR(7000) DEFAULT 'A');
SET NOCOUNT ON;
-- Each row will be 8K, to insert 3GB, we will insert 384,000 rows
DECLARE @i INT = 1
WHILE @i <= 384000
BEGIN
INSERT INTO ProportionalFill.dbo.mssqltips DEFAULT VALUES
SET @i += 1
END
Step 4 - Capture data space utilization in each SQL Server data file
We will now kick off the insert script in Step 3 to insert 380K rows into the test table. At the same time, we will execute the loop script below to capture the used data file space in file group PF from another query session.
USE [ProportionalFill]
GO
SET NOCOUNT ON;
DECLARE @i INT = 2
WHILE @i < 94
BEGIN
WAITFOR DELAY '00:00:01'
INSERT INTO ##temp
SELECT @ID,
(
SELECT
CASE WHEN f.fileid = 3
THEN CAST(FILEPROPERTY(f.name, 'SpaceUsed')/128.0 AS DECIMAL(10,2))
ELSE 0 END
FROM sysfiles f
WHERE f.groupid = 2 and f.fileid = 3
) AS [File1 Space Used in MB],
(
SELECT
CASE WHEN f.fileid = 4
THEN CAST(FILEPROPERTY(name, 'SpaceUsed')/128.0 AS DECIMAL(10,2))
ELSE 0 END
FROM sysfiles f
WHERE f.groupid = 2 and f.fileid = 4
) AS [File2 Space Used in MB]
SET @i += 1
END
Step 5 - Check the gathered results
In the test scenario, Step 3 and Step 4 completed in approximately 2 minutes and 28 seconds.
Data file “File1” is still 1GB in size, and data file “File2” is still 2GB in size. Step 3 has inserted approximately 3GB worth of data into the test table.
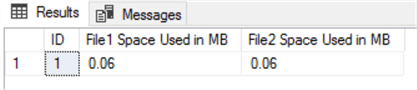
SELECT DB_NAME(database_id) AS DatabaseName, Name AS DataFileName, (size*8)/1024 DataFileSizeMB
FROM sys.master_files
WHERE DB_NAME(database_id) = 'ProportionalFill'
AND name IN ('File1', 'File2')
GO
SELECT
*
,[File1 Space Used in MB] / 1000 * 100 [File1 Space Used %]
,[File2 Space Used in MB] / 2000 * 100 [File2 Space Used%]
FROM ##temp
GO
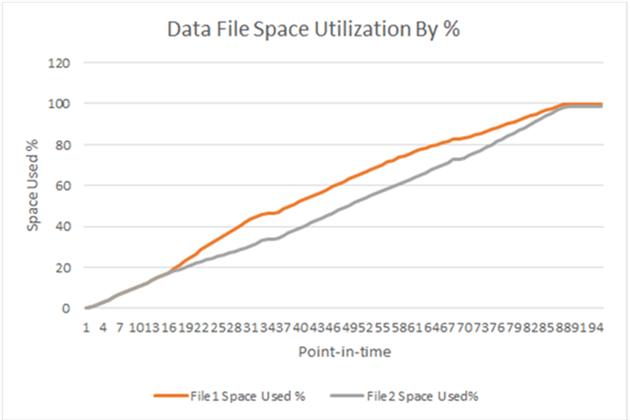
Step 6 - Chart the result in Line Graph
The line graph below shows the percentage of data file space used. As we can see, the line graph depicts SQL Server Proportional Fill algorithm when populating data files in file group “PF”. The Proportional Fill algorithm is not about distributing the equal amount of data across data files, it is about writing the proportional amount in the file to each file according to the free space within the file group. The end result is the data files are full at the same time.
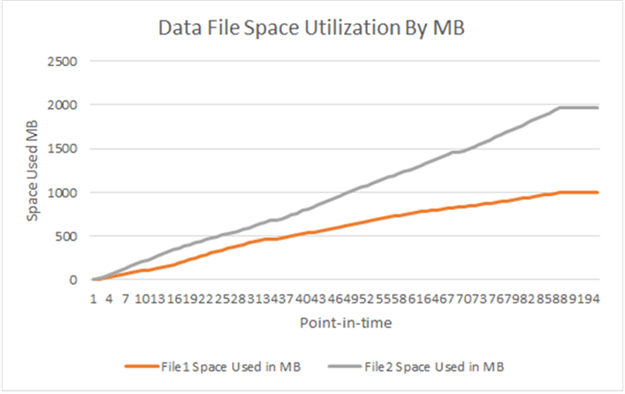
The line graph below shows the data file utilization by MB and we can clearly see the utilization rate of data file File2 is about twice the rate of data file File1. This is to be expected because data file File2 (2GB) is twice the size of data file File1 (1GB).
Conclusion
File groups use proportional fill strategy across all the files within each file group and uses a round robin algorithm to write a proportional amount to the free space in the file and to each file within the file group.
Understanding the proportional fill and round robin behavior in SQL Server is important not only for user databases, but especially in the case of tempdb as well. The SQL Server best practice is to have multiple tempdb data files to alleviate tempdb PFS and SGAM contention. It is easy to imagine when the tempdb data files sizes are uneven, then the extent allocations would be heavier on the bigger sized data files. This configuration would again cause a hotspot and not alleviate tempdb contention.
Next Steps

Simon Liew is an independent SQL Server Consultant in Sydney, Australia. He is a Microsoft Certified Master for SQL Server 2008 and holds a Master’s Degree in Distributed Computing.
- MSSQLTips Awards: Trendsetter (25+tips) – 2017 | Author of the Year Contender – 2016, 2017

Hi vishal,
The script is hard-coded to create and check secondary filegroup and data files to illustrate the proportional fill behaviour. Tempdb only allow to have a PRIMARY filegroup and whatever the code in this tip which checks a secondary filegroup would not be applicable to tempdb and it is not possible to create a secondary filegroup in tempdb.
buggy scripts, not capturing data in temp tables.