Problem
SQL Server vNext represents a major step towards making SQL Server a platform that gives you choices of development languages, data types, on-premises and in the cloud, and across operating systems by bringing the power of SQL Server to Linux, Linux-based Docker containers, and Windows. The SQL Server Query Processing Engine is an important component used to design the execution plan and execute a query efficiently. SQL Server 2017 improves the behavior of the design for the execution plan. In this tip we will get an overview of the SQL Server 2017 Adaptive Query Processing.
Solution
Introduction to SQL Server 2017
Microsoft announced the first community test preview (CTP 1.0) of SQL Server vNext on November 16, 2016, it runs on Windows, Linux (Redhat, SUSE, Ubuntu), Docker and MacOS. SQL Server vNext also includes the features added in SQL Server 2016 Service Pack 1. At the time of writing, SQL Server vNext is in preview, it can be downloaded as a free evaluation version for 180 days from Microsoft website at this link. In April 2017, Microsoft released Community Technology Preview (CTP) 2.0 of SQL Server vNext. Microsoft Officially announced that this Community Technology Preview (CTP) 2.0 of SQL Server vNext will be called SQL Server 2017.
SQL Server 2017 Query Plan Enhancements
When we submit a query to a SQL Server database, the query optimizer is used to generate the query plan based on the query processor tree and statistics. The optimizer will generate and evaluate multiple execution plans based on the calculation for the least amount of resources (CPU and IO) and query execution time. SQL Server queries the statistics to estimate the data based on the estimated execution plan. Performance of the query depends on the query plan. Some of the factors impacting selection of the execution plans are:
- Out of date statistics
- Improper indexing
- Badly written queries
- Re-work to modify the queries
Cardinality estimates are a prediction of the number of rows in the query results. The query optimizer uses these estimates to choose a plan for executing the query. The quality of the query plan has a direct impact on improving query performance. Cardinality estimates is a process that uses a combination of statistical techniques and assumptions to provide an estimated number of rows to the optimization process.
So consider a scenario where it estimates the number of rows as 100 and does all calculations, resource grants and selects an execution plan; however the actual number of rows are in the millions. In this case our query will not perform as expected. So we might see one or all of the following:
- Slow query performance
- Excessive resource consumption
- Impact SQL Server instance performance
So the normal behavior of SQL Server query processing is to analyse, create the execution plan and execute it based on the estimations. However the query processing engine cannot modify the execution plan at run time.
SQL Server 2017 introduced a new way of optimizing the SQL Server execution plan by mitigating the cardinality estimation errors in the query plan and adapting the plan execution based on the execution results, this feature is called Adaptive Query Processing.
Adaptive Query Processing and consists of three features:
- Interleaved Execution
- Adaptive Batch Mode Joins
- Adaptive Batch Mode Memory Grant Feedback
In this tip, we are going to explore details about the Interleaved Executions.
Interleaved Executions in SQL Server
SQL Server 2017 materializes cardinality estimates for Multi Statement Table Valued Functions (MSTVFs). Before SQL Server 2017, the cardinality estimate is set to a specific number of rows which results in improper selection of the query plan, indexes, joins, etc. In SQL Server 2017, while the query execution from the SQL Server optimizer can adjust the execution plan by actually executing a part of the query execution plan first. Based on the execution results (estimated number of rows) it can consider a better plan and execute the query with the modified plan. That’s why it is called Interleaved Execution.
Before we proceed further let me provide a basic example of Multi Statement Table Valued Functions (MSTVFs).
SQL Server Multi Statement Table Valued Functions (MSTVFs)
MSTVF are table valued functions setup with the following:
- Declare a table variable that is to be returned
- MSTVF must have a BEGIN/END block
- Inside the BEGIN/END block you need code that populates the table variable
So for our demo, we need to select the top(N) records from the Sales.Orders table that exists in the sample database WideWorldImporters. Query should return the customerID, OrderID fields. So the sample MSTVF would be:
create or ALTER function [dbo].[MSTVF_SalesOrders](@n int)
returns @t table([CustomerID] nvarchar(40), [OrderID] nvarchar(40))
with schemabinding
as
begin
insert @t([CustomerID], [OrderID])
select top(@n)
[CustomerID]
,[OrderID]
from
[Sales].[Orders];
return;
end
GO
Execute query on SQL Server 2016
In SQL Server 2017, we have a new compatibility_level of 140. In our test we will running the queries under the old compatibility level 130 first to see prior behavior.
Now we need to run select the top(10000) rows from the table using the MSTVF. Before running the query we will:
- Set the SQL Server database compatibility level to 130 (SQL Server 2016)
- Clear the cache
So our query will be
USE [WideWorldImporters]
GO
-- Set compatibility level of SQL Server SQL Server 2016
Alter database WideWorldImporters set compatibility_level = 130
go
-- Clear procedure cache for DB
Alter database scoped configuration clear procedure_cache;
go
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create or ALTER function [dbo].[MSTVF_SalesOrders](@n int)
returns @t table([CustomerID] nvarchar(40), [OrderID] nvarchar(40))
with schemabinding
as
begin
insert @t([CustomerID], [OrderID])
select top(@n)
[CustomerID]
,[OrderID]
from
[Sales].[Orders];
return;
end
GO
-- Run the query with mTVF
select
C = count_big(*)
from
[Sales].[Invoices] c
join dbo.MSTVF_SalesOrders(10500) t
on t.[CustomerID] = c.[CustomerID] and t.[orderid]=c.[orderid];
go
We need to capture the Actual Execution plan, so click on Actual Execution Plan in SSMS and execute the query and review the Actual Execution Plan as shown below.

Now if we hover the mouse over the table insert statement we can see the following:
- Estimated Number of rows: 100
- Actual Number of rows: 10500
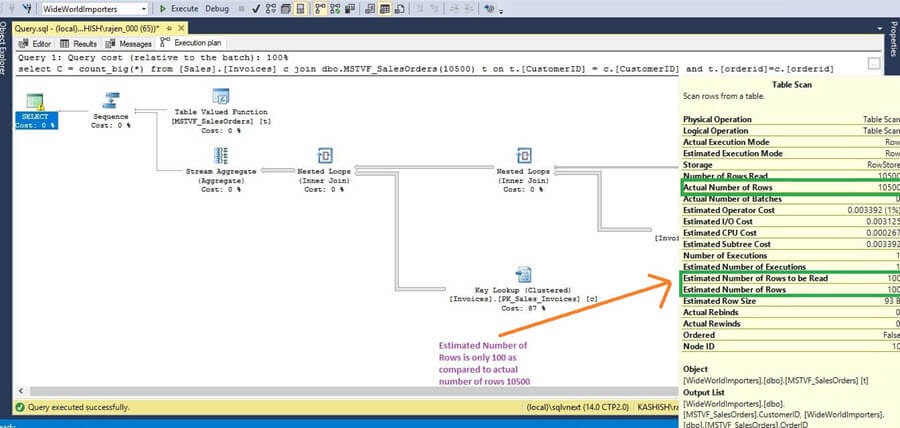
We can see that the MTVF cardinality is estimated as 100 rows, this is a fixed estimate starting in SQL Server 2014 where the estimate is set to 100 rows. If we try running the code in earlier versions of SQL Server the estimated rows will be 1 as shown below.
For this we will run the query with LEGACY_CARDINALITY_ESTIMATION set to On.
USE [WideWorldImporters]
GO
-- Set compatibility level of SQL Server SQL Server 2016
Alter database WideWorldImporters set compatibility_level = 130
go
-- Clear procedure cache for DB
Alter database scoped configuration clear procedure_cache;
go
--To Enable Cardinality Estimation
ALTER DATABASE SCOPED CONFIGURATION SET LEGACY_CARDINALITY_ESTIMATION = On;
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create or ALTER function [dbo].[MSTVF_SalesOrders](@n int)
returns @t table([CustomerID] nvarchar(40), [OrderID] nvarchar(40))
with schemabinding
as
begin
insert @t([CustomerID], [OrderID])
select top(@n)
[CustomerID]
,[OrderID]
from
[Sales].[Orders];
return;
end
GO
-- Run the query with MSTVF
select
C = count_big(*)
from
[Sales].[Invoices] c
join dbo.MSTVF_SalesOrders(10500) t
on t.[CustomerID] = c.[CustomerID] and t.[orderid]=c.[orderid];
go

Look at the memory allocation and we will compare it later with the SQL Server 2017 plan.
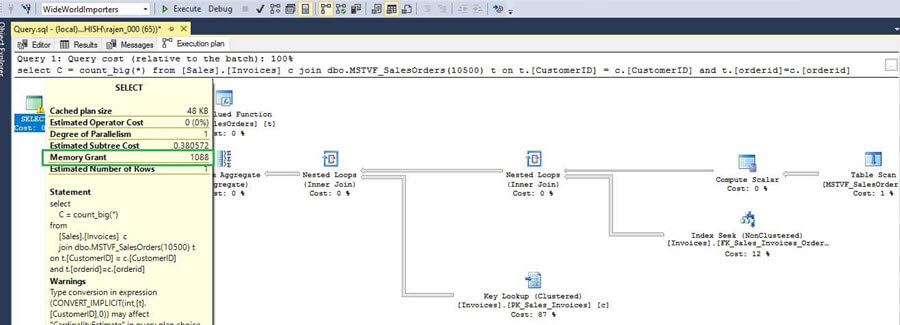
Execute MSTVF in SQL Server 2017
In the demo, I am using the CTP 2.0, so Interleaved Execution will be automatically enabled and we will enable trace flag 11005.
Now let’s run the query in SQL Server 2017 and observe the behavior.
USE [WideWorldImporters]
GO
-- Set compatibility level of SQL Server SQL Server 2017
Alter database WideWorldImporters set compatibility_level = 140
go
-- Clear procedure cache for DB
Alter database scoped configuration clear procedure_cache;
go
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create or ALTER function [dbo].[MSTVF_SalesOrders](@n int)
returns @t table([CustomerID] nvarchar(40), [OrderID] nvarchar(40))
with schemabinding
as
begin
insert @t([CustomerID], [OrderID])
select top(@n)
[CustomerID]
,[OrderID]
from
[Sales].[Orders];
return;
end
GO
-- Run the query with MSTVF
select
C = count_big(*)
from
[Sales].[Invoices] c
join dbo.MSTVF_SalesOrders(10500) t
on t.[CustomerID] = c.[CustomerID] and t.[orderid]=c.[orderid];
go


We can see that the estimated number of rows and the actual number of rows are the same (i.e. 10,500) which improves the efficiency for the query processor to decide the query plan.
If we look at the memory allocation we can also see that it is different from SQL Server 2016 or earlier versions, now it is properly allocation based on the estimated values.

Profiler review of Interleaved Execution
First, we will look at Profiler events in SQL Server 2016 or earlier.

During the execution without Interleaved Execution, the query starts executing, then the function is executed, the query continues execution and finishes the execution.
However, if we look at the same Profiler events in SQL Server 2017 for Interleaved Execution we see the execution of the MSTVF and the query is interleaved, at first MSTVF is executed, and then the query starts execution and reuses the MSTVF result.

Extended Events Review of Interleaved Execution
To get more insight of the Interleaved Execution process we can use Extended Events. SQL Server 2017, provides these new Extended Events:
interleaved_exec_stats_update - This event describe the statistics updated by interleaved execution.
- estimated_card - Estimated cardinality
- actual_card - Updated actual cardinality
- actual_pages - Updated actual pages
interleaved_exec_status - This event marks the interleaved execution.
- operator_code - Op code of the starting expression for interleaved execution.
- event_type - Whether this is a start of the end of the interleaved execution
- time_ticks - Time of this event happens
recompilation_for_interleaved_exec - Fired when recompilation is triggered for interleaved execution.
- current_compile_statement_id - Current compilation statement’s id in the batch.
- current_execution_statement_id - Current execution statement’s id in the batch.
So we will set the Extended Event session as per the below events:

We can see in the Extended Event session that it initially estimated the number of rows to be 100.

Now in another step, the intervalued_exec_status is executed which marks the Interleaved Execution as shown below:

In the next step, we can see that value is updated to 10,500 from the initial value of 100.

The Query Processor of SQL Server benefits from the new feature - interleaved execution, which is a part of the adaptive query processing features. This feature will increase performance of existing queries with MSTVFs and make MSTVF functions more usable in terms of performance in general.
Next Steps
- We will explore more about Adaptive Query Processing- SQL Server 2017 in future tips.
- Explore SQL Server 2017 in the preview.
- Read more SQL Server 2017 Tips.

Hi! I am Rajendra Gupta, Database Specialist and Architect, helping organizations implement Microsoft SQL Server, Azure, Couchbase, AWS solutions fast and efficiently, fix related issues, and Performance Tuning with over 14 years of experience.
I am the author of the book “DP-300 Administering Relational Database on Microsoft Azure.” I can be reached at: Rajendra.gupta16@gmail.com for any consulting help.
- MSSQLTips Awards:
- Author of the Year – 2022 | Author Contender – 2021/2023/2024 | Champion Award (100+ tips) – 2020