Problem
Most companies are faced with the ever-growing big data problem. See the computer world article for details. Not all data is stored in a structured format such as a comma separated value (CSV) file. Many industries store notes written by professionals in a freely formatted text field. How can IT professionals help business lines search those note fields for key words?
Solution
The ability to perform a full text index search has been in the SQL Server engine since the very early days. Today, we are going to learn about how to use this special indexing with Azure SQL database.
Business Problem
I am a big fan of the TV show Grimm. Each week, a Seattle police detective named Nick Burkhardt hunts down supernatural creatures that were described in fairy tales. In real life, a collection of fairy tales was first published in 1812 by the Grimm brothers, Jacob and Wilhelm. The collection is commonly known in English as Grimms’ Fairy Tales. During their time as authors, more stories were added to the collection. The seventh version of the book published in 1857 contained 211 fairy tales.
I thought a small sampling of the stories would be a great way to show off the features and benefits of full text indexing. The enclosed zip file contains sixty-two randomly selected fairy tales. I am going to assume that the Azure storage account and Azure SQL Server from my prior tip still exists. The purpose of this proof of concept is to build a GRIMM database and to explore full text indexing. A simple task list is given below as a guideline for this proof of concept.
| Task | Description |
|---|---|
| 1 | Load files into Azure blob storage. |
| 2 | Create Azure SQL database |
| 3 | Create external data source. |
| 4 | Populate main table with titles. |
| 5 | Use OPENROWSET to populate table with files. |
| 6 | Explore the FULL text indexing |
Sign into Azure
We must log in with a valid subscription owner before we can do any work in the PowerShell ISE. You will be prompted for credentials using a valid user name and password.
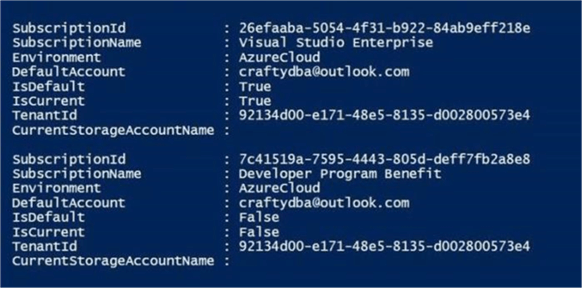
An account might have several subscriptions associated with it. The output below shows the subscriptions associated with craftydba@outlook.com user name. Since the Developer Program Benefit only has $25 associated with it, we want to make sure any new deployments are on the Visual Studio Enterprise subscription. The last step is to choose the correct subscription to work with.
Using a blob container
Most of the objects you create in Azure are contained inside what is called a resource group. For this project, I am going to re-use a resource group named rg4tips17, a storage account named sa4tips17 and a blob container named sc4tips17. Please see my article on “Using Azure to store and process large amounts of SQL data” for the PowerShell cmdlets to accomplish these tasks.
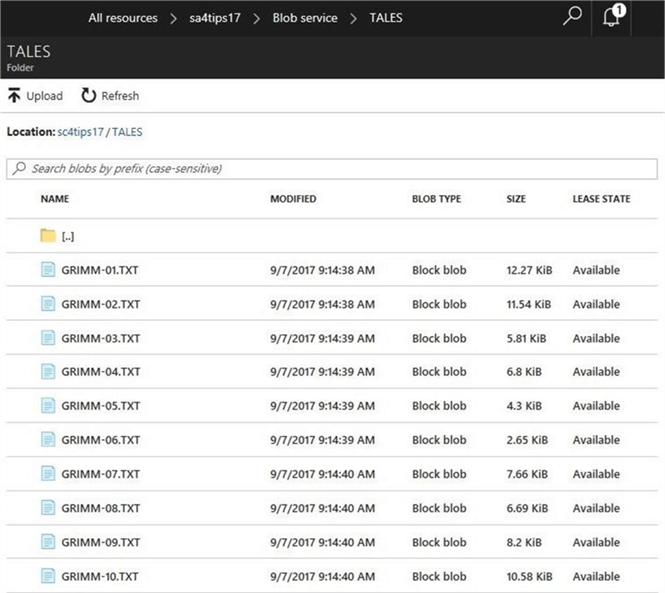
The image below shows the final blob container inside of the storage account.

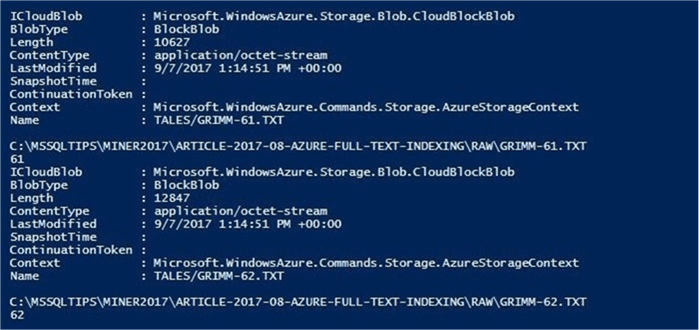
Taken from the PowerShell ISE command window, the image below depicts each of the fairy tale text files being loaded into the storage container. The enclosed PowerShell script has the sections that create the resource group, storage account and blob container commented out. In short, it uploads the files into blob storage.
I created a new folder called TALES to contain the text files. If you go log into the Azure Portal, you should have similar results as seen below.
I always like to make sure the file that was uploaded to a service was not changed in any way. The output in the PowerShell ISE console window shows the successful download of the first fairy tale to the c:\temp directory. Right below the output is windows explorer showing one downloaded file.

Creating the Azure SQL Server
For this proof of concept, I am going to re-use the logical SQL database server named sql4tips17 which is contained by the resource group named rg4tips17. The administrator account or user name for the server is jminer and the password is MS#tIpS$2017. Please see my article called “Deploying Azure SQL Database Using Resource Manager PowerShell cmdlets” for the details on these tasks.
The image below, taken from the PowerShell ISE command window, shows the Azure SQL server residing in the East US 2 region.

Security is a very important concern by every company. That is why Microsoft blocks all connections to the database by using a firewall. The image below shows a firewall rule named fr4laptop being added to allow my laptop access to the database server.

Defining the Azure SQL Database
I am going to use SQL Server Management Studio (SSMS) to manage my new Azure SQL server. Make sure you have the latest version of SSMS. Updates happen often and the newest version can be downloaded from here. We need to connect to the server to start crafting Transact SQL (T-SQL) scripts. Choose the database engine as the server type. Enter the fully qualified name of the Azure SQL Server. Pick SQL Server authentication as the security option and supply the login/password of the server administrator. The image below shows a typical connect to server dialog box.

By default, you should be in the master database. Execute the code snippet below to create the GRIMM database.
/* Create a database to hold the fairy tales */ -- Delete existing database DROP DATABASE IF EXISTS GRIMM GO -- Create new database CREATE DATABASE GRIMM ( MAXSIZE = 1GB, EDITION = 'STANDARD', SERVICE_OBJECTIVE = 'S1' ) GO
Switch the database context to our newly created database. Executing the code below creates a schema named STORIES. I think schemas are an underutilized object in most production databases. The power behind schemas is the ability to assign permissions to groups (users) at that level. In fact, you can have a simple user never see the other schemas he/she is not assigned to.
/* Create a schema to hold objects */ -- Delete existing schema. DROP SCHEMA IF EXISTS [STORIES] GO -- Add new schema. CREATE SCHEMA [STORIES] AUTHORIZATION [dbo] GO
A database must have at least one table to store data. The code snippet below creates a table named TBL_FAIRY_TALES.
/* Create a table to hold the fairy tales */ -- Delete existing table DROP TABLE IF EXISTS [STORIES].[TBL_FAIRY_TALES] GO -- Add new table CREATE TABLE [STORIES].[TBL_FAIRY_TALES] ( [MY_ID] [SMALLINT] IDENTITY(1, 1) NOT NULL, [MY_TITLE] [VARCHAR] (75) NOT NULL, [MY_TALE] [VARCHAR](MAX) NULL ) GO
If you successfully executed the code snippets above, your object explorer window should have one new table.

Defining an external data source
Microsoft provided the database developer with updated BULK INSERT and OPENROWSET Transact SQL commands. New syntax has been added to these commands to handle files located in blob storage. These commands depend on an external data source being defined.
Four simple steps can be used to create an external data source. First, a master key needs to be defined for a given unique password. Second, a share access signature (SAS) needs to be generated for the blob storage account. Third, a database credential should be built using the previous SAS token. Fourth, the external data source is created for access to the blob storage container.
Please see my article on “Bulk Inserting data into Azure SQL database” for details on how to accomplish this tasks.
I assume you can create a database credential named CRD_AZURE_4_TALES and create an external data source named EDS_AZURE_4_TALES without any help. The T-SQL code snippet below displays the newly defined database objects.
/* Show new database objects */ -- Display master key, database credential & external data source SELECT * FROM sys.symmetric_keys WHERE name = '##MS_DatabaseMasterKey##' SELECT * FROM sys.database_credentials WHERE name = 'CRD_AZURE_4_TALES' SELECT * FROM sys.external_data_sources WHERE NAME = 'EDS_AZURE_4_TALES' GO
The screen shot below is the output from executing the above T-SQL code snippet.

Loading the table with data
The one table in the GRIMM database contains the following fields: MY_ID – a surrogate key field to number of fairy tales, MY_TITLE – a variable length character field to store the title and MY_TALE – a large object binary field of type text that contains the story. The table value constructor allows the designer to create a derived table from in-line data. I could have just written sixty-two insert statements to start populating the table. However, the derived table is a more elegant solution.
/*
Insert just the titles (derived table)
*/
-- Add 62 titles
INSERT INTO [STORIES].[TBL_FAIRY_TALES] (MY_TITLE)
SELECT T.MY_TITLE FROM
(
VALUES
('THE GOLDEN BIRD'),
('HANS IN LUCK'),
('JORINDA AND JORINDEL'),
('THE TRAVELLING MUSICIANS'),
('OLD SULTAN'),
('THE STRAW, THE COAL, AND THE BEAN'),
('BRIAR ROSE'),
('THE DOG AND THE SPARROW'),
('THE TWELVE DANCING PRINCESSES'),
('THE FISHERMAN AND HIS WIFE'),
('THE WILLOW-WREN AND THE BEAR'),
('THE FROG-PRINCE'),
('CAT AND MOUSE IN PARTNERSHIP'),
('THE GOOSE-GIRL'),
('THE ADVENTURES OF CHANTICLEER AND PARTLET'),
('RAPUNZEL'),
('FUNDEVOGEL'),
('THE VALIANT LITTLE TAILOR'),
('HANSEL AND GRETEL'),
('THE MOUSE, THE BIRD, AND THE SAUSAGE'),
('MOTHER HOLLE'),
('LITTLE RED-CAP [LITTLE RED RIDING HOOD]'),
('THE ROBBER BRIDEGROOM'),
('TOM THUMB'),
('RUMPELSTILTSKIN'),
('CLEVER GRETEL'),
('THE OLD MAN AND HIS GRANDSON'),
('THE LITTLE PEASANT'),
('FREDERICK AND CATHERINE'),
('SWEETHEART ROLAND'),
('SNOWDROP'),
('THE PINK'),
('CLEVER ELSIE'),
('THE MISER IN THE BUSH'),
('ASHPUTTEL'),
('THE WHITE SNAKE'),
('THE WOLF AND THE SEVEN LITTLE KIDS'),
('THE QUEEN BEE'),
('THE ELVES AND THE SHOEMAKER'),
('THE JUNIPER-TREE'),
('THE TURNIP'),
('CLEVER HANS'),
('THE THREE LANGUAGES'),
('THE FOX AND THE CAT'),
('THE FOUR CLEVER BROTHERS'),
('LILY AND THE LION'),
('THE FOX AND THE HORSE'),
('THE BLUE LIGHT'),
('THE RAVEN'),
('THE GOLDEN GOOSE'),
('THE WATER OF LIFE'),
('THE TWELVE HUNTSMEN'),
('THE KING OF THE GOLDEN MOUNTAIN'),
('DOCTOR KNOWALL'),
('THE SEVEN RAVENS'),
('THE WEDDING OF MRS FOX'),
('THE SALAD'),
('THE STORY OF THE YOUTH WHO WENT FORTH TO LEARN WHAT FEAR WAS'),
('KING GRISLY-BEARD'),
('IRON HANS'),
('CAT-SKIN'),
('SNOW-WHITE AND ROSE-RED')
) AS T (MY_TITLE);
GO
-- Show table w/o tales
SELECT * FROM [GRIMM].[STORIES].[TBL_FAIRY_TALES];
GO
After executing the above T-SQL code, our table is partially populated. How can we populate the TEXT field with the fairy tale story (file)?

The OPENROWSET command can read both text and binary files from Azure Blob Storage. The T-SQL snippet below is our first try at reading in a fairy tale text file. We need to supply the path to blob storage file, the name of the data source and the large object binary (LOB) option. There are three valid options: BLOB - read in the file as a binary object, CLOB - read in the file as a character object, and NCLOB - read in the file as a unicode object.
The code snippet below does a test read on the first fairy tale file.
/*
Read in one file as a test
*/
SELECT *
FROM
OPENROWSET
(
BULK 'TALES/GRIMM-01.TXT',
DATA_SOURCE = 'EDS_AZURE_4_TALES',
SINGLE_CLOB
) AS RAW_DATA;
GO
The results window in SSMS shows the output below. As expected, the one row result set contains the raw characters from the text file. This includes carriage returns, line feeds and any other special characters that are embedded in the file.

I could have used a packing list file as a driver of the text file load process. However, this is just a proof of concept and I wanted to keep it simple. The code below uses dynamic SQL to load a temporary table with the text of each story. It is important that surrogate key matches the number of the text file. This number is used to update the correct record in the production table. Therefore, the preferred way to clear the table is to use the TRUNCATE TABLE command which resets the identity column. After executing the code below, the table now contains both titles and text for each fairy tale.
/*
Update tales with story text files
*/
-- delete work space
DROP TABLE IF EXISTS #TMP_TALE
GO
-- do not count rows
SET NOCOUNT ON;
-- local variables
DECLARE @VAR_CNT SMALLINT;
DECLARE @VAR_MAX SMALLINT;
DECLARE @VAR_STMT VARCHAR(2048);
-- setup counters
SELECT @VAR_CNT = 1;
SELECT @VAR_MAX = 62;
-- create work space
CREATE TABLE #TMP_TALE (MY_TALE VARCHAR(MAX));
-- load the tales
WHILE (@VAR_CNT <= @VAR_MAX)
BEGIN
-- clear work space
DELETE FROM #TMP_TALE;
-- make dynamic SQL statement
SELECT @VAR_STMT = '
INSERT INTO #TMP_TALE
SELECT BulkColumn
FROM
OPENROWSET
(
BULK ''TALES/GRIMM-' + REPLACE(STR(@VAR_CNT, 2, 0), ' ', '0') + '.TXT'',
DATA_SOURCE = ''EDS_AZURE_4_TALES'',
SINGLE_CLOB
) AS RAW_DATA;'
-- debugging info
PRINT @VAR_STMT;
PRINT "";
-- load file into work space
EXEC (@VAR_STMT);
-- update fairy tale table
UPDATE [GRIMM].[STORIES].[TBL_FAIRY_TALES]
SET MY_TALE = (SELECT MY_TALE FROM #TMP_TALE)
WHERE MY_ID = @VAR_CNT;
-- increment counter
SELECT @VAR_CNT = @VAR_CNT + 1;
END;
GO
-- count rows
SET NOCOUNT OFF;
-- delete work space
DROP TABLE IF EXISTS #TMP_TALE
GO
-- Show table with tales
SELECT * FROM [GRIMM].[STORIES].[TBL_FAIRY_TALES];
GO
The SSMS results window seen below represents a completely loaded table.

In a nutshell, our test database named GRIMM is ready for use. It is now time to learn about indexing.
Standard indexing
If you paid attention to the definition of the table, you would notice that no primary key index was defined. Thus, the table is considered a heap. For large tables, this could be an issue since a full table scan is required to find a row.
Two T-SQL commands come to mind when looking for a pattern inside a text field. The LIKE operator allows the developer to use pattern matching. It returns boolean value which is either a true or false. The PATINDEX text function can also be used to find patterns within a text field. It returns a non-zero value for the starting position of the pattern.
The code snippet below looks for fairy tales that involving a wolf.
/*
Looking for the big bad wolf!
*/
-- Using like operator
SELECT * FROM [STORIES].[TBL_FAIRY_TALES] T WHERE T.MY_TALE LIKE '%wolf%'
GO
-- Using patindex function
SELECT * FROM [STORIES].[TBL_FAIRY_TALES] T WHERE PATINDEX('%wolf%', T.MY_TALE) > 0
GO
The results window seen below shows that seven fairy tales involve a wolf in the story.

If we look at the execution plan for each query, we see that a full table scan is being used. Each row in the table is retrieved using the row identifier (file number, data page number, and slot on the page). This is not an optimal query plan.

Does adding a primary key to the table improve the query plan? The code snippet below changes the table to have a primary key constraint.
/* Add primary key and re-test previous queries */ -- Delete existing primary key IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[STORIES].[TBL_FAIRY_TALES]') AND name = N'PK_FAIRY_TALES_ID') ALTER TABLE [STORIES].[TBL_FAIRY_TALES] DROP CONSTRAINT [PK_FAIRY_TALES_ID] GO -- Add index on id (primary key - clustered) ALTER TABLE [STORIES].[TBL_FAIRY_TALES] ADD CONSTRAINT PK_FAIRY_TALES_ID PRIMARY KEY(MY_ID) GO
Now, the data is physically ordered in the data pages by the MY_ID field. However, both T-SQL statements must retrieve the MY_TALE field and scan the whole text field for the pattern. Instead of a table scan, the query optimizer comes up with a cluster index scan. We have not improved our execution plan at all!

What happens if we add a non-clustered index to the table? The code snippet below tries to add an index to the MY_TALE field.
/*
Indexes have a byte limit
*/
-- Try to add index to text data type?
CREATE NONCLUSTERED INDEX IDX_FAIRY_TALES_TXT
ON [STORIES].[TBL_FAIRY_TALES] (MY_TALE)
GO
This SQL statement fails compilation. See the image below for the error message. First, a field defined as varchar(max) is not supported as a data type. Second, there are byte size limits on standard indexes. Please see this tip for details by database engine version.

To summarize, standard clustered and non-clustered indexing can’t handle TEXT fields.
Creating a Full Text index
The solution to this problem is to leverage full text indexing. Two simple steps are used to create the index.
A full text catalog is a virtual object not associated with a file group. This has not always been the case in versions prior to 2008. The sys.fulltext_catalogs catalog view can be used to determine if a catalog exists by name. Use the DROP FULLTEXT CATALOG command to remove an existing catalog and the CREATE FULLTEXT CATALOG command to define a new catalog. A catalog may have one or more indexes associated with it.
The code below creates our FT_GRIMM_CATALOG database object.
/* Create a full text catalog */ -- delete existing catalog IF EXISTS (SELECT * FROM sys.fulltext_catalogs WHERE name = N'FT_GRIMM_CATALOG') DROP FULLTEXT CATALOG FT_GRIMM_CATALOG GO -- create new catalog CREATE FULLTEXT CATALOG FT_GRIMM_CATALOG AS DEFAULT; GO
A full text index depends on a unique non-nullable index being defined on the base table. In our case, we have a primary key constraint that satisfies this requirement. The sys.fulltext_indexes catalog view can be used to determine if an index exists by name. Use the DROP FULLTEXT INDEX command to remove an existing index and the CREATE FULLTEXT INDEX command to define a new index. A full text index can be associated with only one full text catalog and a table can only have one full text index.
How does a full text index differ from a regular index?
A full-text index is a special type of token-based functional index that is built and maintained by the Full-Text Engine for SQL Server. The process of building a full-text index differs from building other types of indexes. Instead of constructing a B-tree structure based on a value stored in a particular row, the Full-Text Engine builds an inverted, stacked, compressed index structure based on individual tokens from the text being indexed. Quote from MSDN.
The initial population of the full text index finds words in the MY_TALE text field, converted the words to tokens and stores the entries in an inverted index. The ALTER FULLTEXT INDEX allows you to change many properties of the index.
The code below creates a full text index. Please note, the index is associated with a given table/catalog is not given an actual name.
/*
Create a full text index
*/
-- delete existing full text index
IF EXISTS (SELECT * FROM sys.fulltext_indexes WHERE object_id = object_id('[STORIES].[TBL_FAIRY_TALES]') )
DROP FULLTEXT INDEX ON [STORIES].[TBL_FAIRY_TALES]
GO
-- Create full text index
CREATE FULLTEXT INDEX ON [STORIES].[TBL_FAIRY_TALES] ([MY_TALE]) KEY INDEX PK_FAIRY_TALES_ID ON FT_GRIMM_CATALOG;
GO
-- Enable the index
ALTER FULLTEXT INDEX ON [STORIES].[TBL_FAIRY_TALES] ENABLE;
GO
-- Start the population
ALTER FULLTEXT INDEX ON [STORIES].[TBL_FAIRY_TALES] START FULL POPULATION;
GO
The T-SQL snippet displays the newly created database objects used in full text indexing.
/*
Show new database objects
*/
-- table indexes
SELECT *
FROM sys.indexes i
JOIN sys.objects o ON i.object_id = o.object_id
WHERE is_ms_shipped = 0;
-- full text catalog
SELECT * FROM sys.fulltext_catalogs;
-- full text indexes
SELECT * FROM sys.fulltext_indexes;
GO
The output below was taken from the results window in SSMS.
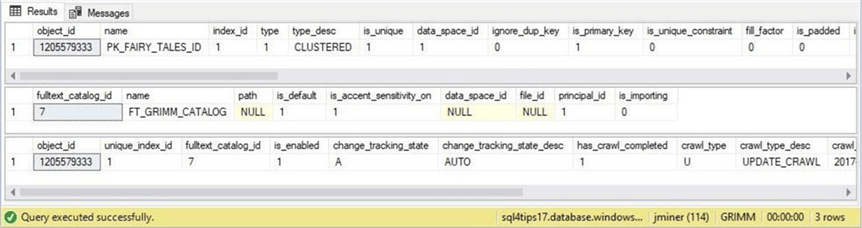
Now that we have a full text index, how do we use it in a simple query?
Using a Full Text index
I am going to introduce four different ways to use a full text index.
The CONTAINS predicate uses a fuzzy match to words and phrases. The example below looks for the word ‘wolf’ in the fairy tales. We see the execution plan joins the results of the full text match to the clustered index for an improved query plan.
-- Search for the word 'wolf' - (7) results SELECT MY_ID, MY_TITLE FROM [STORIES].[TBL_FAIRY_TALES] T WHERE CONTAINS(T.MY_TALE, 'wolf') GO

The FREETEXT predicate finds values that match the meaning and not just the exact wording of the words in the search condition. The example below looks for the word ‘wolf’ in the fairy tales. We see a similar improved query plan.
-- Search for the word 'wolf' - (7) results SELECT MY_ID, MY_TITLE FROM [STORIES].[TBL_FAIRY_TALES] T WHERE FREETEXT(T.MY_TALE, 'wolf') GO

The next two statements are used just like tables in the FROM clause of a typical SELECT statement. The CONTAINSTABLE table valued function performs a fuzzy match to words and phrases. On the other hand, the FREETEXTTABLE table value function matches the meaning and not just the exact wording for the search phrase. Both functions return a RANK field. Higher the number equates to a better overall match.
By changing the search phrase to “big bad wolf”, we end of with thirty-three matches instead of seven. Just like the previous predicate functions, improved query plans are produced when using the full text index.

In summary, write T-SQL queries using the two predicate functions and/or the two table valued functions to leverage the full text index.
Fuzzy Results
The results from using the predicate and/or table value functions might not always align with what you expect from a wild card search pattern. For instance, let us look for the four characters of the word herd. Executing a simple query using the LIKE command, we see a result set of seven records. If we use our newly discovered predicate functions, there is only one record in the results window.
The T-SQL snippet below looks for the word (string) herd.
/* Show new database objects */ -- Returns 7 records SELECT * FROM [STORIES].[TBL_FAIRY_TALES] T WHERE T.MY_TALE LIKE '%herd%' GO -- Returns 1 record SELECT MY_ID, MY_TITLE FROM [STORIES].[TBL_FAIRY_TALES] T WHERE CONTAINS(T.MY_TALE, 'herd') GO -- Returns 1 record SELECT MY_ID, MY_TITLE FROM [STORIES].[TBL_FAIRY_TALES] T WHERE FREETEXT(T.MY_TALE, 'herd') GO
The image below shows the result set of the full text index searches. It contains only one result.

If we open the original text document with notepad++, we can see that word herd is stand alone with spaces on both sides. Why are the documents containing the word shepherd being missed by the full text index?

We need a better understanding of how the full text indexing works to figure this out.
When you create a full text index, there are three change tracking states. I am going to ignore the OFF state since we do want to update our index. The AUTO state means any future updates to the rows in the table are caught by the CRAWL process. In our example, any inserts, updates or deletes are caught by the process in a short period of time. The MY_TALE field is parsed for key words which in turn update the inverted index. Any noise words in the STOPLIST are not stored. Of course, white space does not count as words. The MANUAL state tells the process to ignore any record changes until the state is changed back to AUTO.
There are a bunch of dynamic management views that can be used to gain insight into the full text indexing process. We want to look at the sys.dm_fts_index_keywords_position_by_document view to gain insight into which documents (rows) contain a keyword and what positions in the document (field) do the keywords start at. A document id is the unique index value. This is the same primary key index that we used when we defined the full text index.
The code below retrieves all the documents that contain the words herd and shepherd. This list can be quite lengthy. I used a trick with the FOR XML clause to create a sub-query to combine all the positions into a comma separated value list. This reduces the result set drastically.
/*
Show new database objects
*/
-- Where are the keywords?
SELECT DISTINCT
keyword,
display_term,
column_id,
document_id,
CONVERT(varchar(max),
(
SELECT position as [text()], ',' as [text()]
FROM sys.dm_fts_index_keywords_position_by_document (DB_ID('GRIMM'), OBJECT_ID('[STORIES].[TBL_FAIRY_TALES]')) I
WHERE I.display_term = O.display_term and I.column_id = O.column_id and I.document_id = O.document_id
FOR XML path('')
)
) as positions
FROM
sys.dm_fts_index_keywords_position_by_document (DB_ID('GRIMM'), OBJECT_ID('[STORIES].[TBL_FAIRY_TALES]')) O
WHERE
O.display_term like 'herd' or
O.display_term like 'shepherd'
GO
The image below shows the output from the code above. We now see that the word herd occurs one time and the word shepherd occurs six times.
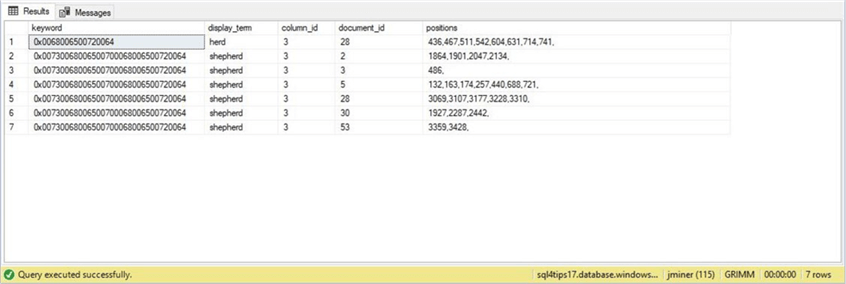
To recap, the differences in query results comes from the fact that full text indexing does not allow partial matches. You have to match on whole words.
Considerations when loading data
There are two ways to handle indexing when a large data import is about to happen. One way is to keep the index on the table and re-organize the index after the data load. This may slow down the load process drastically. Another way is to drop the index and create it after the data load is finished.
However, full text indexing gives us a third option. We can change the change tracking state to MANUAL, then make the massive table change. At the end of the load process, we can either start an UPDATE POPULATION alter index action, or set the change tracking state back to AUTO. Let us try this technique with one record.
-- Set to manual tracking ALTER FULLTEXT INDEX ON [STORIES].[TBL_FAIRY_TALES] SET CHANGE_TRACKING MANUAL; GO Let us run a Query X that looks for the word shepherd. -- Query X - look for the word 'shepherd' SELECT MY_ID, MY_TITLE, [RANK] FROM [STORIES].[TBL_FAIRY_TALES] AS T JOIN CONTAINSTABLE(STORIES.TBL_FAIRY_TALES, MY_TALE, ' "shepherd" ') FTS ON T.MY_ID = FTS.[KEY] ORDER BY [RANK] DESC; GO
The output below taken from the SSMS results window shows six matching records.

We are going to set the story for ‘THE LITTLE PEASANT’ to NULL using the code below.
-- set the story to null UPDATE [STORIES].[TBL_FAIRY_TALES] SET MY_TALE = NULL WHERE MY_ID = 28 GO -- show the update SELECT * FROM [STORIES].[TBL_FAIRY_TALES] WHERE MY_ID = 28; GO
The output from the SELECT statement shows the updated field containing a NULL value.

If we execute the Query X again, we receive six records. This is not accurate since document 28 has no fairy tale text. This is expected since the index has not been updated. If we set the change tracking state to AUTO right now, the CRAWL process will find the modified records and update the full text index.
-- Set to auto tracking ALTER FULLTEXT INDEX ON [STORIES].[TBL_FAIRY_TALES] SET CHANGE_TRACKING AUTO; GO
If we wait a few seconds and rerun the Query X that has the CONTAINSTABLE table value function, we will see the following results. Five records is exactly what we were looking for.

To sum things up, be conscious of the system impact when performing a large data load. Consider manually populating the full text index after the data load.
Reducing the noise
Many industries have words that are very commonly used. However, these words do not have real meaning. For instance, the word patient in doctor’s notes is not interesting. Every person at the hospital is considered a patient!
Microsoft has supplied the developer with the notion of a STOP LIST and STOP WORDS. By default, there is a SYSTEM STOPLIST list that contains words like ‘the’, ‘and’, ‘but’, etc. In our GRIMM tales collection, our authors deem the word ‘shepherd’ as not interesting.
How can we add this word to a STOP LIST?
The sys.fulltext_stoplists catalog view can be used to determine if a custom stop list exists by name. Use the DROP FULLTEXT STOPLIST command to remove an existing list and the CREATE FULLTEXT STOPLIST command to define a new list. A stop list can be created from scratch or be copied from an existing stop list. The SYSTEM STOPLIST is a default list stored in the resource database.
The code below creates our FT_STOP_LIST database object.
/* Create a custom stop list */ -- delete existing stop list IF EXISTS (SELECT * FROM sys.fulltext_stoplists WHERE name = 'FT_STOP_LIST' ) DROP FULLTEXT STOPLIST FT_STOP_LIST; GO -- create new stop list CREATE FULLTEXT STOPLIST FT_STOP_LIST FROM SYSTEM STOPLIST; GO
The ALTER FULLTEXT STOPLIST command allows the developer to add or delete words from the list. The code below adds the word shepherd to our custom stop list. To take advantage of this new stop list, we need to use the ALTER FULLTEXT INDEX command to modify our existing index.
/* Remove word from full text index */ -- add stop word to stop list ALTER FULLTEXT STOPLIST FT_STOP_LIST ADD 'shepherd' LANGUAGE 'English'; GO -- use new stop list ALTER FULLTEXT INDEX ON [STORIES].[TBL_FAIRY_TALES] SET STOPLIST = FT_STOP_LIST; GO
If we execute Query X from the previous section, an empty record set is returned. This is wicked awesome! We can now eliminate industry specific noise words from our full text index.

To reset our full text index, just set the stop list to the system default. Running Query X afterwards should return five records. I leave this exercise up to you.
/* Update full text index */ -- use default list ALTER FULLTEXT INDEX ON [STORIES].[TBL_FAIRY_TALES] SET STOPLIST = SYSTEM; GO
Summary
Today, we created a proof of concept Azure SQL database to explore full text indexing. We used techniques from prior articles to save the fairy tale text files to Azure Blob storage and load them into a variable length character (text) field inside a table. Both clustered and non-clustered indexing did not help us create optimal query plans.
Microsoft’s full text indexing saved the day. Instead of creating a normal binary tree index, full text indexing parses the text field into tokens. Key information, such as the document id that contains the token and the locations inside the text field where the token occurs, is saved to an inverted index. New predicates and/or table valued functions can be used to leverage the full text index. These newly constructed SELECT statements use improved query plans.
Like any index, the developer must consider fragmentation and data movement when performing a large batch load of data. We saw how the change tracking can be used to turn off and on the CRAWL process. This process detects the inserts, updates and deletes that occur to the table and updates the full text index accordingly.
Since full text indexing deals with words, not character patterns, it is important to only save words that have meaning. In this article, we saw how create a STOP LIST and STOP WORDS to remove noise words from our full text index. The complete T-SQL script is enclosed for your use.
The announcement of the addition of full text indexing to Azure SQL database is here. Going from an on-premise to in-cloud managed service model means some options are not supported by design. Three key options did not make it to the first release: document filter types for office/pdf, custom thesaurus file and semantic search. I did a quick test in which a full text index uses a document filter for MS Word. The only stored token was an end of file marker. Therefore, all three features are still not supported.
I hope you enjoyed this article on full text indexing. For more details, please read the documentation on full text search.
Next Steps
- Using Azure Search instead of full text indexing.
- Advanced full text indexing techniques.

John Miner is a Senior Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
He has over thirty years of data processing experience, and his architecture expertise encompasses all phases of the software project life cycle, including design, development, implementation, and maintenance of systems.
His credentials include undergraduate and graduate degrees in Computer Science from the University of Rhode Island. Also, he has earned certificates from Microsoft for Database Administration (MCDBA), System Administration (MCSA), Data Management & Analytics (MCSE), Data Science (MPP), Databricks Certified, and Fabric Certified.
John has been recognized with the Microsoft MVP award nine times for his outstanding contributions to the Data Platform community.
When he is not busy talking to local user groups or writing blog entries on new technology, he spends time with his wife and daughter enjoying outdoor activities. Some of John’s hobbies include wood working projects, crafting a good beer and playing a game of chess.
- MSSQLTips Awards: Author of the Year – 2019, 2022, 2023 | Champion (100+tips) – 2023