Problem
The European Space Agency (ESA) published the preliminary findings from the GAIA satellite in September 2016. The purpose of this satellite is to assemble a detailed 3D map of our Milky Way galaxy. To date, Gaia has pinned down the precise position in the sky and the brightness of 1,142 million stars. How can we load all this compressed comma separated data into Azure for aggregate analysis?
Solution
Microsoft has provided the database developer with Azure SQL Data Warehouse which is a massively parallel processing (MPP) database engine in the cloud. The large number of data files can be staged in Azure Standard Blob Storage and later loaded into the warehouse by using Polybase.
Business Problem
There are two primary data file feeds from this European Space Agency project.
First, the TGAS files contain information about the brightest 2 million stars in the Milky Way. There are 16 of these gnu zipped (gz) comma separated value (csv) files. Second, the GAIA files contain information about the remaining 1.1 billion stars that were detected by the two telescopes on the satellite. This is an additional 256 compressed files that need to be processed.
Because this is a complex problem, we are going to break the solution into three mini projects or articles.
- Using PowerShell, download files from European Space Agency and upload them to Azure Standard Storage.
- Using PowerShell, deploy an Azure SQL Data Warehouse in the same data center as the staged files.
- Leveraging Polybase and Transact SQL, load the data into tables and perform some basic analysis.
About The GAIA Project
At this time, I would like to provide a citation to the relevant work done by the European Space Agency and the Scientists of the GAIA project.
I am just a computer scientist looking for a large and interesting data set to work with.
“The Gaia spacecraft consists of three major functional modules: the payload module, the mechanical service module and the electrical service module. It carries a single integrated instrument that comprises three major functions: astrometry, photometry and spectrometry. The three functions use two common telescopes and a shared focal plane, with each function having a dedicated area on the large 0.5m × 1m CCD detector array.” Please read this fact sheet for information more about this interesting telescope.
Downloading Data Files
The data files for this project are located on the ESA website. The $srcpath variable contains the base URL for the data files. This is the source directory of all our files. The $dstpath variable contains the hard drive location in which the files will temporarily reside. This is the intermediate destination directory. The $gzfile is the name of the file which is dynamically created during each loop iteration. Last but not least, the Invoke-WebRequest cmdlet can be used to download a file from a given website.
The PowerShell script below downloads each of the GAIA data files (second data feed) from the ESA website to our local hard drive.
# Web site url
$srcpath = "http://cdn.gea.esac.esa.int/Gaia/gaia_source/csv/"
# Local file path
$dstpath = "C:\MSSQLTIPS\MINER2016\ARTICLE-2016-11-BLOB-STORAGE\GDATA\"
# Counter
$cnt = 0
# Loop thru 256 files
while ($cnt -lt 256)
{
# File name
$gzfile = "GaiaSource_000-000-{0:000}.csv.gz" -f $cnt
# Fully qualified source
$srcfull = $srcpath + $gzfile
# Fully qualified destination
$dstfull = $dstpath + $gzfile
# Download file
Invoke-WebRequest $srcfull -OutFile $dstfull
# Increment count
Write-Host $cnt
$cnt = $cnt + 1
}
At this point, if you followed all the directions correctly, you should have two hundred fifty six compressed files in the GDATA directory. See image below for a small selection of these files.

The PowerShell script below downloads each of the TGAS data files (first data feed) from the ESA website to our local hard drive. Please note that the $srcpath, $dstpath and $gzfile variables have been updated for this new data source.
# Web site url
$srcpath = "http://cdn.gea.esac.esa.int/Gaia/tgas_source/csv/"
# Local file path
$dstpath = "C:\MSSQLTIPS\MINER2016\ARTICLE-2016-11-BLOB-STORAGE\TDATA\"
# Counter
$cnt = 0
# Loop thru 16 files
while ($cnt -lt 16)
{
# File name
$gzfile = "TgasSource_000-000-{0:000}.csv.gz" -f $cnt
# Fully qualified source
$srcfull = $srcpath + $gzfile
# Fully qualified destination
$dstfull = $dstpath + $gzfile
# Download file
Invoke-WebRequest $srcfull -OutFile $dstfull
# Increment count
Write-Host $cnt
$cnt = $cnt + 1
}
If you followed all the directions correctly, you should have sixteen compressed files in the TDATA directory. Please see image below for details.

Profiling Data Files
The first step in profiling the data files is to extract the raw data file from the compressed file format. I used the 7-zip utility to save the GAIA data file to my desktop. Next, I opened the file with NotePad++ application and navigated to the bottom of the page. Both programs are freeware under the GPL licensing.
Here are some things you can observe by looking at the file. The actual name of the columns (fields) can be obtained from the header line in the file. This will be useful when creating the table schema. The text file is in UNIX format with just line feeds (LF).
The most important observation is the numbers of rows which is 218,454 if we drop the header line. See image below. Since all files are the same size, we can take the number of rows times two hundred fifty six files. As a result, we can estimate that we have 55,924,280 rows of data. This is well shy of the 1 billion rows highlighted by the article.
Be that as it may, this is the first of many yearly datasets to come regarding this project. With almost 56 million rows of data available today, there is plenty of data to demonstrate the capabilities of the data warehouse cloud service.

With this surprising result, I am curious if the TGAS data set will be around the 2 million records?
The image below shows that 15 of the 16 files have 134,867 rows of data. The last file is smaller in size. If we do the math, we have 2,023,005 rows of data without including the last file. In a nutshell, it is always prudent to profile the data before going thru a time consuming load. It will save you grief from the garbage-in equals garbage-out proverb.

Azure Storage Concepts
Storage objects are the basic building blocks of some higher level Azure services. For instance, Azure SQL data warehouse stores the table data as files on premium blob storage. Also, every storage object has to be carved out of a storage account, each storage account can hold a maximum of 500 TB of data, and each subscription can have up to 200 storage accounts. Wow, that is a lot of data! Please see Azure documentation for subscription service limits.
There are four types of storage objects. Containers, tables, queues and shares can be instantiated to solve a particular business problem. I will talk more about each type of storage object in a future article. If you cannot wait, take a look at the Azure documentation on storage.

To solve our business problem, we need to store compressed data files in one or more containers. Since I am a lazy programmer, I am going to use one container. Containers can store any type of data and are analogous to a file directory. There are three types of blobs: block – optimized for transmitting large amounts of data, page – a collection of 512 k pages optimized for random read/writes and append – a random size block of data is added at the end of the blob. We are going to choose the default, which is a block blob.
The image below shows a sample Contoso Retail storage account with two containers and three files.

Azure Subscription
We must log in with a valid subscription owner before we can do any work. The Add-AzureRmAccount cmdlet will prompt you for credentials.

An account might have several subscriptions associated with it. Use the Get-AzureRmSubscription cmdlet to list the subscriptions associated with craftydba@outlook.com.
The output from this command shows two subscriptions. Since the Developer Program Benefit only has $25 associated with it, usually we want to make sure any new deployments are on the Visual Studio Enterprise subscription. However, we will use the Developer Program subscription since Azure Blob storage is very reasonable price.
Last but not least, use the Set-AzureRmContext cmdlet to choose the correct subscription.

The PowerShell script below logs into the portal, lists the subscriptions and selects the correct subscription. Of course, manual intervention is needed for the sign on and coding the correct subscription id ahead of time.
# # Azure Subscriptions # # Prompts you for azure credentials Add-AzureRmAccount # List my subscriptions Get-AzureRmSubscription # Pick my Developer one $SubscriptionId = '7c41519a-7595-4443-805d-deff7fb2a8e8' Set-AzureRmContext -SubscriptionId $SubscriptionId
Resource Group
The concept behind the Resource Manager model is that all Azure components that make up a solution are created or destroyed as a group. Thus, the key object that binds all the items together is a resource group.
When dealing with resource groups, there are three cmdlets you should know.
- New-AzureRmResourceGroup cmdlet – Creates a named group in a location that you select.
- Get-AzureRmResourceGroup cmdlet – Lists all resource groups defined for an account.
- Remove-AzureRmResourceGroup cmdlet – Removes a named resource group.
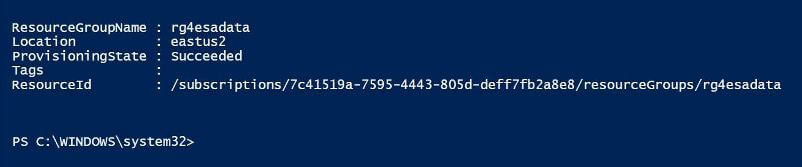
The PowerShell script below creates a resource group named rg4esadata in the East US 2 location.
# # Create a resource group # # New resource group New-AzureRmResourceGroup -Name "rg4esadata" -Location "East US 2" # List resource groups Get-AzureRmResourceGroup # Delete resource group # Remove-AzureRmResourceGroup -Name "rg4esadata" -Force
The image below shows the resource groups associated with the Developer Program subscription.
Storage Account
The concept behind the Standard Storage Account is that containers, tables, queues, and shares can be defined inside the account. Destroying the account removes all the objects. So be very cautious when deleting a storage account.
When dealing with storage accounts, there are three cmdlets you should know.
- New-AzureRmStorageAccount cmdlet – Creates a named storage account in a selected resource group.
- Get-AzureRmStorageAccount cmdlet – Lists all storage accounts defined for a resource group.
- Remove-AzureRmStorageAccount cmdlet – Removes a named storage account.
The PowerShell script below creates a storage account named sa4esadata in the rg4esadata resource group.
# # Create a storage account # # Create new storage account (lowercase) New-AzureRmStorageAccount -StorageAccountName 'sa4esadata' ` -ResourceGroupName "rg4esadata" -Location "East US 2" -Type "Standard_GRS" # Show the account Get-AzureRmStorageAccount -ResourceGroupName "rg4esadata" # Delete storage account #Remove-AzureRmStorageAccount -ResourceGroupName "rg4esadata" -Name 'sa4esadata'
The image below shows the storage account associated with the resource group.

There are two cmdlet parameters that I want to discuss in detail.
First, the -Kind parameter is used to determine if the storage account supports all objects (Storage) or just blobs (BlobStorage). The default is to allow all objects. On the other hand, if you are storing just blobs, the other kind allows for hot or cool storage. The latter is a real price savings for blobs that are accessed infrequently.
Second, the -SkuName or -Type parameter is used to determine the location and redundancy of the storage. Please see the list below for full details.
- Standard_LRS – Local redundant storage is replicated three times within a single data center and region. This redundancy protects your data from normal hardware failures, but not from the failure of a single data center.
- Standard_ZRS – Zone redundant storage maintains three copies of your data across two to three facilities within one or two regions. This type is more resilient than LRS but less resilient than GRS.
- Standard_GRS – Geo redundant storage maintains six copies of your data shared equally between a primary and secondary region. GRS provides the highest level of durability. The secondary region can be failed over to during an outage.
- Standard_RAGRS – Read access geo redundant storage is just like Standard GRS. However, the secondary region can be read from at any time. This is great for shared usage of the data.
- Premium_LRS – Premium locally-redundant storage is replicated three times within a single data center and region. Unlike the four above SKU’s, this storage uses Solid State Disks (SSD) for optimum performance.
Like most things in life, better speed and/or redundancy comes at an extra price. Choose the storage type that meets your budget and business requirements. Since I only want to post the files in Azure one time, we are going to use geo redundant storage for the greatest durability.
Storage Container
The concept behind the Storage Containers is that block, page and append blobs can be stored inside the container. Destroying the container removes all the objects. So be very cautious when deleting a storage container.
When dealing with storage containers, there are three cmdlets you should know.
- New-AzureStorageContainer cmdlet – Creates a named storage container in a selected storage account.
- Get-AzureStorageAccount cmdlet – Lists all storage containers defined for a storage account.
- Remove-AzureStorageAccount cmdlet – Removes a named storage container.
Did you notice something missing from the above commands? Maybe the two characters ‘Rm’?
The development group forgot to write a bunch of Resource Manager specific commands for storage containers. The work around is to get the storage context using the Get-AzureRmStorageAccount cmdlet and pipe this context to the old classic deployment model cmdlets to perform the needed actions.
The PowerShell script below creates a storage container named sc4esadata in the sa4esadata storage account.
# # Create a storage container # # Grab storage context - work around for RM $StorageContext = Get-AzureRmStorageAccount -Name 'sa4esadata' ` -ResourceGroupName "rg4esadata" # Create new container $StorageContext | New-AzureStorageContainer -Name 'sc4esadata' -Permission Off # Show the container $StorageContext | Get-AzureStorageContainer # Remove the container # $StorageContext | Remove-AzureStorageContainer -Name 'sc4esadata' -Force
The image below shows the storage account associated with the resource group.

Uploading Data Files
The PowerShell code to move files from the local hard disk to the Azure Storage Container as a blob is similar in nature to the download code. The $srcpath variable contains the hard drive local in which the files currently reside. This is the source directory of all our files. The $gzfile variable holds the name of the file which is dynamically created during each loop iteration. Last but not least, the Set-AzureStorageBlobContent cmdlet can be used to load the local file into the Azure Storage Container. The storage context is passed as a parameter since it uniquely identifies the target location.
The code below loads the GAIA data files to the storage container. Change the variables to load the TGAS data files to the same container. I leave this task as an exercise for you to do.
# Local file path
$srcpath = "C:\MSSQLTIPS\MINER2016\ARTICLE-2016-11-BLOB-STORAGE\GDATA\"
# Counter
$cnt = 0
# Loop thru 256 files
while ($cnt -lt 256)
{
# File name
$gzfile = "GaiaSource_000-000-{0:000}.csv.gz" -f $cnt
# Fully qualified source
$srcfull = $srcpath + $gzfile
# Upload file to azure
$StorageContext | Set-AzureStorageBlobContent -Container 'sc4esadata' -File $srcfull
# Increment count
Write-Host $cnt
$cnt = $cnt + 1
}
The image below shows the properties of file GaiaSource_000-000-000.csv.gz stored in Azure.

The image below shows the storage container named sc4esadata viewed from the Azure Portal.

If you followed all the directions correctly, you should have 271 files in the storage container taking up just over 11 GB of space.

Going the other way
With the popularity of the cloud growing, one might ask how do I download a blob file from Azure Standard Storage to my local hard disk? The Get-AzureStorageBlob cmdlet can be used to list the properties of a container or get the blob context of a single file. If we pass that blob context to the Get-AzureStorageBlobContent cmdlet, we can download a single file to our local hard drive. To recap, if we want to download all the files in the container, just use the for each loop to process all the files.
The PowerShell script below list all the blobs in the container and then downloads the GaiaSource_000-000-255.csv.gz file to the c:\temp directory.
# List all blobs in a container.
$StorageContext | Get-AzureStorageBlob -Container 'sc4esadata'
# Download file from azure
$StorageContext | Get-AzureStorageBlob -Container 'sc4esadata' `
-Blob "GaiaSource_000-000-255.csv.gz" | Get-AzureStorageBlobContent -Destination "c:\temp\"
If you run the above script, you should now have one compressed file in the temporary directory.

Estimating Costs
If you plan to leverage the Azure Services in the near future, you should get familiar with the Azure Pricing Calculator. For this business problem, I am going to estimate that we are going to use up to 20 GB of Standard GRS storage. Since reading and writing block blobs is relatively inexpensive, I am going to allow for 1 million storage transactions. The image below shows that our total monthly cost is $1.00.

Determining how storage transactions are calculated can be quite complicated. I am definitely no expert in this area. I am going to refer you to the Azure Storage Team blog article for more details.
Usually, estimation can be done by measuring one event and multiplying that event by the number of possible occurrences in a month. We recently loaded 271 files comprising of 11 GB of data. We can use that as our one event. The Azure Portal has an overview screen that shows the number of transactions broken down by storage type. Please see image below. We can see that this event only took around 4,500 transactions. Thus, our monthly over estimate is great for cost planning.

Summary
Humans have been looking at the stars for thousands of years. “The oldest accurately dated star chart appeared in ancient Egyptian astronomy in 1534 BC.” Please see wikipedia for more history on star charts. Today, we learned about how the European Space Agency is taking this task to a new level with the GAIA satellite. As a result of this project, a large data set of stars is publicly available for review.
The end goal is to load this dataset into Azure SQL Data Warehouse which is a massively parallel processing (MPP) database engine in the cloud for analysis. Before that can be done, we need to load the large number of data files into Azure Standard Blob Storage. A high level overview of Azure Storage was presented for a good understanding of various storage objects. A low level coding exercise using PowerShell was performed to do the following: download the files to a local hard disk, allocate all Azure objects to support a Storage Container, and upload the files to the container as Block Blobs. This PowerShell code will come in handy the next time we need to either upload or download files from Azure Storage.
If you want to learn more, check out Azure Documentation on this subject. Next time, we will work our second mini project, creating an Azure SQL Data Warehouse.
Next Steps
- We need to create an Azure SQL Data Warehouse in the same data center as the staged files. How can we deploy such a database using PowerShell?
- We need to load the raw data from Azure Blob storage into tables in the Azure SQL Data Warehouse. How can we leverage PolyBase and Transact SQL to load the data into tables and perform some basic analysis?
- There are many different ways to tune a database engine. How can we make the analysis of the data perform faster?
- There are many different ways to craft a solution to a problem. Are there any other faster Azure Cloud solutions to our problem?
- Check out these other Azure tips

John Miner is a Senior Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
He has over thirty years of data processing experience, and his architecture expertise encompasses all phases of the software project life cycle, including design, development, implementation, and maintenance of systems.
His credentials include undergraduate and graduate degrees in Computer Science from the University of Rhode Island. Also, he has earned certificates from Microsoft for Database Administration (MCDBA), System Administration (MCSA), Data Management & Analytics (MCSE), Data Science (MPP), Databricks Certified, and Fabric Certified.
John has been recognized with the Microsoft MVP award nine times for his outstanding contributions to the Data Platform community.
When he is not busy talking to local user groups or writing blog entries on new technology, he spends time with his wife and daughter enjoying outdoor activities. Some of John’s hobbies include wood working projects, crafting a good beer and playing a game of chess.
- MSSQLTips Awards: Author of the Year – 2019, 2022, 2023 | Champion (100+tips) – 2023


