Problem
Prior to the introduction of Massively Parallel Processing (MPP) architectures in the early 90s, the analytics database market was dominated by Symmetrical multiprocessing (SMP) architecture since around the 70s. SMP had drawbacks around sizing, scalability, workload management, resilience and availability and the MPP architecture addressed many of these SMP drawbacks related to performance, scalability, high availability, and read/write throughput. MPP had drawbacks related to cost, a critical need for data distribution, downtime for adding new nodes and redistributing data, limited ability to scale up compute resources on-demand for real time processing needs, and potential for over capacity given the limitations to isolate storage from compute.
An RDD in spark is similar to a distributed table in MPP in that many of the RDD operations have an equivalent MPP operation. RDD does, however, offer better options for real-time processing needs, ability to scale up nodes for batch processing, while also scaling storage (Data Lake) independently and cost-effectively from compute. Also, it is recommended over MPP for highly unstructured data processing (text, images, video, and more). Additionally, it offers the capability for large scale advanced analytics (AI, ML, Text/sentiment analysis and more). Seeing the many benefits that Spark and the Modern Data Lake Platform has to offer, customers are interested in understanding and getting started with the Storage and Serving Layers of the Data Lakehouse paradigm on Azure.
Solution
The Data Lakehouse paradigm on Azure, which leverages Delta Lake heavily for ACID compliant reliability of within its Data Lake storage, has become a popular choice for big data engineering, ELT, AI/ML, real-time data, and querying use cases. In this article, you will learn more about the Storage and Serving Layers of the Data Lakehouse which include Delta Lake, Synapse Analytics Dedicated SQL Pools, Relational, and Non-Relational Databases.
Architecture
As numerous modern Data Lakehouse technologies become generally available on the Azure data platform with demonstrated capabilities of outperforming traditional on-premises and cloud databases and warehouses, it is important to begin understanding this Lakehouse architecture, the typical components utilized in the Lakehouse paradigm, and how they all come together and contribute to realizing the Modern Data Lakehouse architecture. Azure’s modern resource-based consumption model for PaaS and SaaS services empower developers, engineers, and end users to use the platforms, tools, and technologies that best serves their needs. That being said, there are many Azure resources that serve various purposes in the Lakehouse architecture. The Storage and Serving Layer’s capabilities and tools will be covered in greater detail in subsequent sections.
With storage being cheap within the Data Lake comes the idea of the Lakehouse, however, there is a lack of ACID compliant features within data lakes that persist files as parquet format.
From a data serving and consumption perspective, there are a variety of tools on the Azure platform including Synapse Analytics on-demand and dedicated pools for storage and ad-hoc querying. Outside of the Azure platform, Snowflake also serves as a strong contender to the Synapse Dedicated Pool (SQL DW) as a dedicated data warehouse. All of these various tools and technologies serve a purpose in the Lakehouse architecture which make it a necessity to include them for the particular use case that they best serve rather than choosing between one or the other.
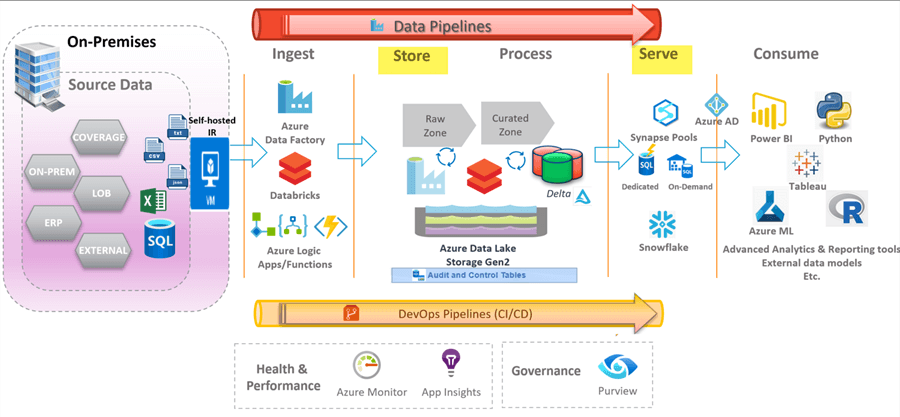
Storing and Serving
Once data is ingested and processed in Azure, it will be ready for storage and serving to a variety of consumers that may be internal and external to an organization. Within the Lakehouse architecture, there are a variety of platforms available for storing and serving data. ADLS gen2 is the storage platform of choice for the Lakehouse due to its cheap storage costs and compatibility with Delta Lake, which provides ACID compliant transactions along with strong features for optimizing, indexing, and performance tuning in the Lakehouse. In this section, you will learn more about Delta Lake and a variety of other big data storage systems including Synapse Analytics Dedicated Pools, Snowflake, SQL Databases, and NoSQL Databases and how they fit into the Lakehouse.
Delta Lake
Delta Lake is an open-source storage layer within the Lakehouse which runs on an existing Data Lake and is compatible with Synapse Analytics, Databricks, Snowflake, Data Factory, Apache Spark APIs and guarantees data atomicity, consistency, isolation, and durability within your lake. Databricks and Synapse Analytics workspaces also support queries that can be run on delta format files within the lake through a variety of languages within notebooks. For more information on Delta Lake, read my previous tip Getting Started with Delta Lake Using Azure Data Factory (mssqltips.com).
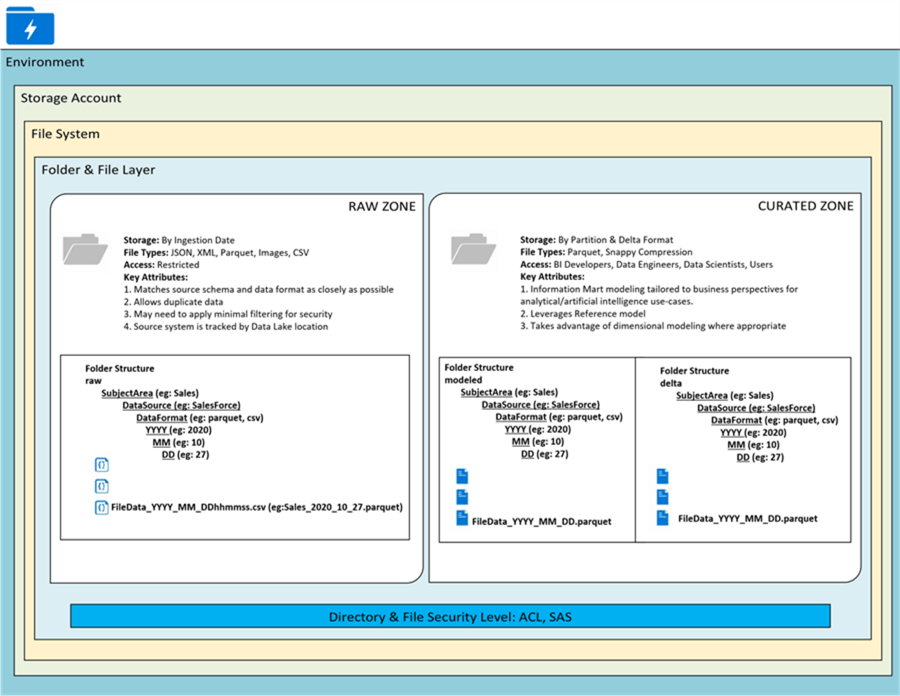
When designing a data lake, it is important to design the appropriate zones and folder structures. Typically, the Lakehouse can contain multiple zones including raw, staging, and curated. In its most simplistic form, there exists a raw and curated zone, as shown in the Figure below. The raw zone is basically the landing zone where all disparate data sources including structured, semi-structured, and un-structured data can land. The data in this zone is typically stored as parquet format but can also support JSON, CSV, XML, Images and much more. Parquet files, in columnar format, can be further compressed with what is called snappy compression with offers a 97.5% compression ratio. As data moves towards curation and consumption, there can be various other zones in between ranging from Data Science Zone to Staging Zone and more. Databricks typically labels their zones as Bronze, Silver, and Gold. Once the data is ready for final curation it would move to a Curated Zone which would typically be in delta format and also serves as a consumption layer within the Lakehouse. It is typically in this zone where the Lakehouse would store and serve their dimensional Lakehouse models to consumers. A data lake can have multiple containers to segregate access and each data lake storage account has up to 5 petabytes of storage capacity. There are a variety of security level access controls ranging that need to be considered when designing a Data Lake. Once curated data is available in the Delta Lake, it can be accessed via a variety of BI tools including Synapse Analytics Workspace for further analysis and insights, all within the Lakehouse.
Synapse Analytics Dedicated SQL Pools
Dedicated SQL pools, formerly called Azure SQL Data Warehouse, is a big data warehouse system that leverages a scale-out architecture to distribute compute of data processing across multiple nodes. A control node optimizes queries for parallel processing and passes the operations to the compute nodes for parallel processing. Dedicated SQL pools decouples storage from compute which supports sizing of compute independently of storage, much like Snowflake’s architecture. It also supports pausing and resuming of the compute resources as needed. It stores data in a relational table with columnar storage. Data Warehousing Units (DWU) are used to measure the size of a Dedicated SQL pool. Dedicated SQL pools represent a traditional big data warehouse and oftentimes fits into the Lakehouse architecture in the form of a serving layer which can easily connect to a variety of BI tools including Power BI and non-Azure tools such as Tableau and more. Dedicated SQL pools are similar to Snowflake data warehouse and often times are compared with Snowflake as a data warehouse choice. Both fit certain use cases and Dedicated SQL pools are well integrated with Azure and Synapse Analytics workspaces. The two types of main data distributions that are used in Dedicated SQL pools are hash and Round Robin distributed tables. You can find more details along with examples of these distribution types in my previous tip, Design and Manage Azure SQL Data Warehouse (mssqltips.com).
Relational Database
Interestingly, relational databases still play a role in modern data Lakehouse architectures because of their reliability and vast battle-hardened feature set from decades of iterations and product releases. Since the Lakehouse is still in its infancy and many fully native Lakehouse technologies are still evolving and growing, organizations prefer to have a hybrid architectural model where data can be served in both the Lakehouse and a traditional relational database. This approach solves for learning curve issues for getting ramped up with the Lakehouse’s capability along with the connectivity limitations for existing BI tools to seamlessly connect to parquet and/or delta format data in the Lakehouse. There are various options for relational databases on the Azure platform including SQL options, MariaDB, PostgreSQL, and MySQL so the database of choice will always be dependent on a variety of factors driven by the particular need and use case. Azure SQL Database is a cloud-computing database service (Database as a Service), that is offered by Microsoft Azure Platform which helps to host and use a relational SQL database in the cloud without requiring any hardware or software installation. For more details on deployment models, purchasing models, and service tiers, please see Microsoft’s article: What is the Azure SQL Database service? – Azure SQL Database | Microsoft Docs.
Non-Relational Databases
NoSQL databases also play a role in the Lakehouse paradigm due to their flexibility in handling un-structured data, millisecond response time, high availability. Cosmos DB is one such fully managed NoSQL database service, which offers automatic and instant scalability, data replication, fast multi-region reads/writes, and open-source APIs for MongoDB and Cassandra. With Cosmos DB’s Azure Synapse Link, users can get to near real-time insights on data stored in a transactional system. For a more detailed understanding of Cosmos DB’s Synapse Link, read my previous tip, Getting Started with Azure Synapse Link for Cosmos DB (mssqltips.com).
The following APIs are available in Cosmos DB:
SQL: provides capabilities for data users who are comfortable with SQL queries. Even though the data is stored in JSON format, it can easily be queried by using SQL-like queries.
MongoDB: existing instances of MongoDB can be migrated to Azure Cosmos DB without major effort.
Gremlin: can be used for storing and performing operations on graph data and supports native capabilities for graph modeling and traversing.
Casandra: dedicated data store for applications created for Apache Cassandra where users have the ability to interact with data via CQL (Cassandra Query Language)
Table: can be used by applications prepared natively for close working with Azure Storage tables.
Next Steps
- Read more about Designing an Azure Data Lake Store Gen2
- Read more about Getting Started with Delta Lake Using Azure Data Factory
- Read more about Snowflake Data Warehouse Load with Azure Data Factory and Databricks
- Read more about Getting Started with Azure Synapse Link for Cosmos DB
- Read more about How to Implement a Databricks Delta Change Data Feed Process

Ron C. L’Esteve is a Data and AI Leader and professional Author residing in Chicago, IL, USA. He is well-known for his impactful books and article publications on Azure Data & AI Architecture, Engineering, and Leadership. Ron holds a Master of Business Administration (M.B.A.) and Master of Science in Corporate Finance (M.S.F.) from Loyola University Chicago. Ron possesses deep technical skills and experience in designing, implementing, leading, and delivering modern Azure Data & AI projects for numerous clients around the world. He is a Motorola Certified Six Sigma Green Belt, a Microsoft Global Challenger, and also holds numerous additional Microsoft, Snowflake, and Databricks professional certifications in Big Data Engineering, Artificial Intelligence, Apache Spark and Data Platform Architecture.
- MSSQLTips Awards: Champion (100+ tips) – 2023 | Author of the Year – 2020-2021 | Rookie of the Year – 2019


