Problem
Many organizations and customers are considering Snowflake data warehouse as an alternative to Azure Synapse Analytics. In a previous article, Loading Azure SQL Data Warehouse Dynamically using Azure Data Factory, loading from Azure Data Lake Storage Gen2 into Synapse DW using Azure Data Factory was covered in depth. Applying the same patterns to loading data into Snowflake DW present a few challenges and options with both Databricks and Azure Data Factory. What are the options for dynamically loading ADLS2 data into Snowflake DW and what is the recommended option based on an analysis of the capabilities and limitations of the various options?
Solution
There is more than one option for dynamically loading ADLS gen2 data into a Snowflake DW within the modern Azure Data Platform. Some of these options which we be explored in this article include 1) Parameterized Databricks notebooks within an ADF pipeline, 2) Azure Data Factory’s regular Copy Activity, and 3) Azure Data Factory’s Mapping Data Flows. After going through detailed end-to-end demonstrations of these various options, we will cover recommendations based on capabilities and limitations of the options from the various ADF pipeline execution runs.
The architectural diagram below illustrates the Azure resources being evaluated for dynamically loading data from a SQL Database (AdventureWorks) into an ADLSgen2 storage account using Azure Data Factory for the ELT and a Snowflake ADF_DB for the Control and logging tables. Finally, we will evaluate the various options (Databricks vs Data Factory) for dynamically loading the ADLS2 files into Snowflake.

Linked Services and Datasets
The following linked services will need to be created in Azure Data Factory.
Base Linked Services

An ADLS2 linked service will serve as the container and landing zone for the snappy compressed files.
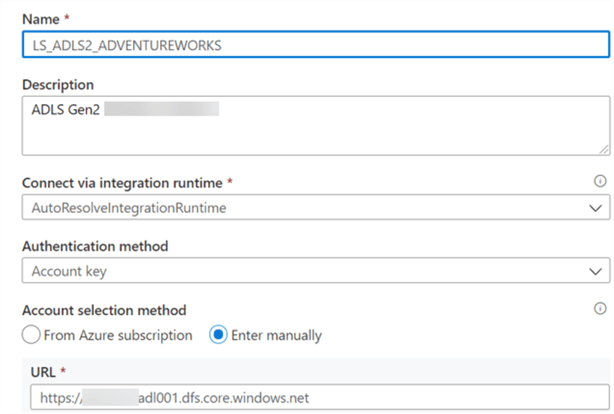
A sample Adventureworks Azure SQL Database will serve as the source SQL Database.

The Snowflake ADF_DB will be used as the control database to house the Control, logging, audit tables within the ADF pipelines.
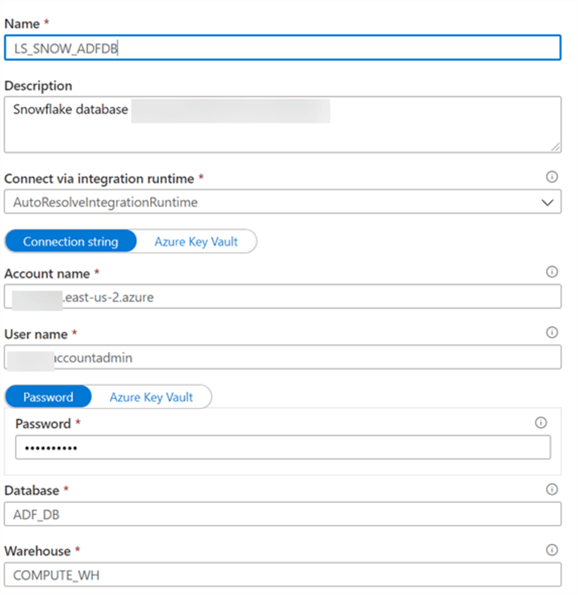
The Snowflake Adventureworks DB will serve as the destination/target Snowflake DB where all AdventureWorks tables will land.

The Azure Databricks linked service is created to process the Databricks Notebook containing Scala code that pushes ADLS Gen2 Files to Snowflake target tables.
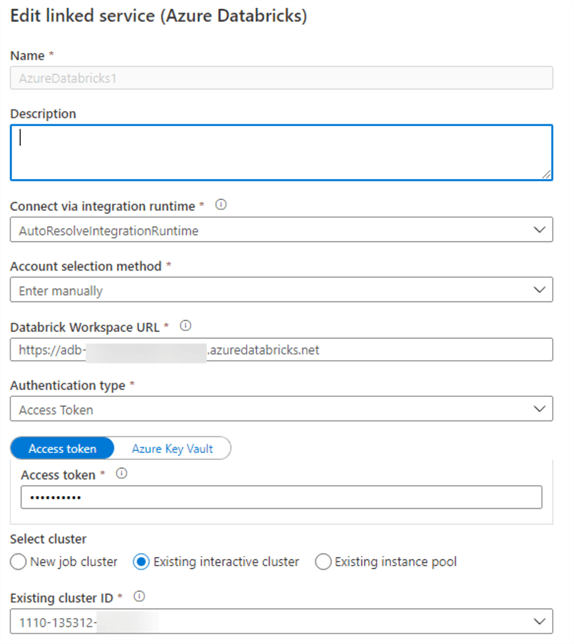
Once the linked services are created, the following datasets will need to also be created which will be used in the pipelines.
Datasets

The ADLS2 Dataset also contains the parameterized folder path and structure that is driven by the control tables and dynamic incoming files.

The following parameters will need to be set which are driven by the Snowflake control tables.

The AdventureWorks dataset will need to be created.

The dynamic parameterized Snowflake DB dataset will need to be created.
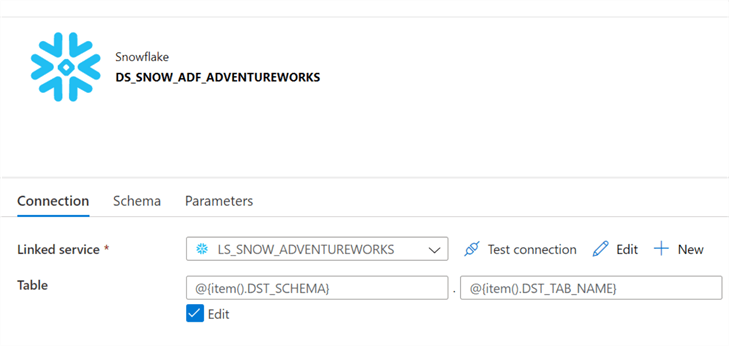
The ADF DB containing the control tables in Snowflake will need to be created as a dataset.

The ADF_DB Control table in Snowflake contains the following schema and can be further updated and edited as desired.
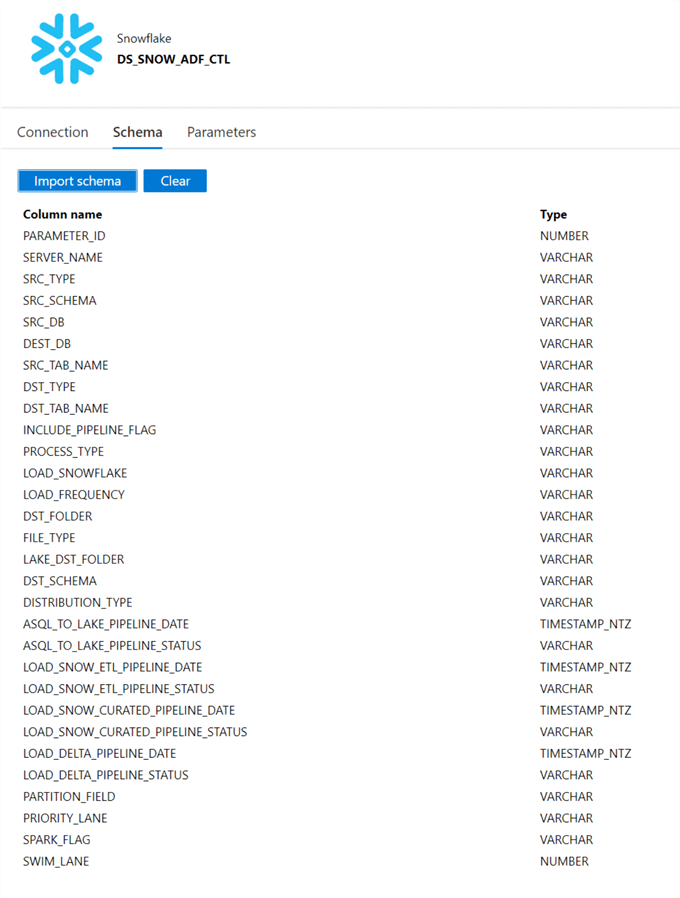
Snowflake Control Database and Tables
Below is a sample SELECT * query that is run on the control tables to present an idea of what these control tables might look like.
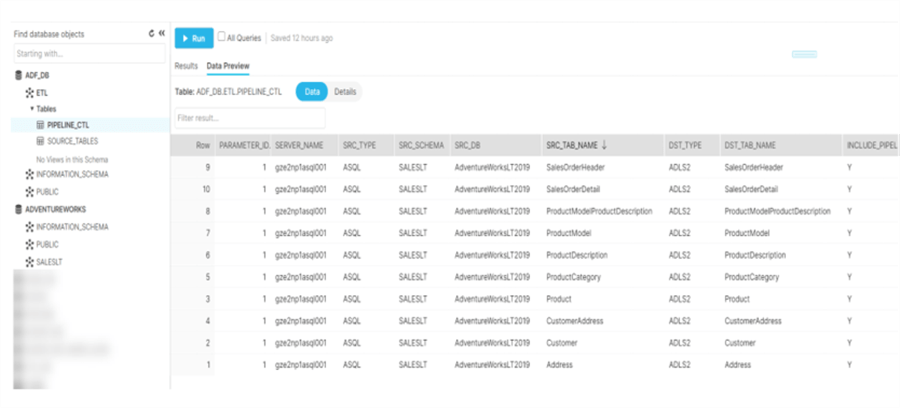
Additionally, below is the script used to create the control and audit tables in Snowflake.
- Database: ADF_DB
- Schema: ETL
- Table: PIPELINE_CTL
create or replace TABLE PIPELINE_CTL (
PARAMETER_ID NUMBER(38,0) NOT NULL autoincrement,
SERVER_NAME VARCHAR(500),
SRC_TYPE VARCHAR(500),
SRC_SCHEMA VARCHAR(500),
SRC_DB VARCHAR(500),
SRC_TAB_NAME VARCHAR(500),
DST_TYPE VARCHAR(500),
DST_TAB_NAME VARCHAR(500),
INCLUDE_PIPELINE_FLAG VARCHAR(500),
PROCESS_TYPE VARCHAR(500),
LOAD_SNOWFLAKE VARCHAR(500),
LOAD_FREQUENCY VARCHAR(500),
DST_FOLDER VARCHAR(500),
FILE_TYPE VARCHAR(500),
LAKE_DST_FOLDER VARCHAR(500),
DST_SCHEMA VARCHAR(500),
DISTRIBUTION_TYPE VARCHAR(500),
ASQL_TO_LAKE_PIPELINE_DATE TIMESTAMP_NTZ(9),
ASQL_TO_LAKE_PIPELINE_STATUS VARCHAR(500),
LOAD_SNOW_ETL_PIPELINE_DATE TIMESTAMP_NTZ(9),
LOAD_SNOW_ETL_PIPELINE_STATUS VARCHAR(500),
LOAD_SNOW_CURATED_PIPELINE_DATE TIMESTAMP_NTZ(9),
LOAD_SNOW_CURATED_PIPELINE_STATUS VARCHAR(500),
LOAD_DELTA_PIPELINE_DATE TIMESTAMP_NTZ(9),
LOAD_DELTA_PIPELINE_STATUS VARCHAR(500),
PARTITION_FIELD VARCHAR(500),
PRIORITY_LANE VARCHAR(500),
SPARK_FLAG VARCHAR(500),
SWIM_LANE int,
primary key (PARAMETER_ID)
);
create or replace TABLE AUDIT_TAB (
PIPELINE_NAME VARCHAR(100),
DB_NAME VARCHAR(20),
SCH_NAME VARCHAR(20),
TABLE_NAME VARCHAR(50),
SOURCE_COUNT NUMBER(38,0),
ADLS_COUNT NUMBER(38,0),
SNOWFLAKE_COUNT NUMBER(38,0),
LOAD_TIME TIMESTAMP_NTZ(9) DEFAULT CURRENT_TIMESTAMP()
);
Pipelines
Step 1: Design & Execute Azure SQL Database to Azure Data Lake Storage Gen2
The movement of data from Azure SQL DB to ADLS2 is documented in this section. As a reference, this process has been further documented in the following article titled Azure Data Factory Pipeline to fully Load all SQL Server Objects to ADLS Gen2.
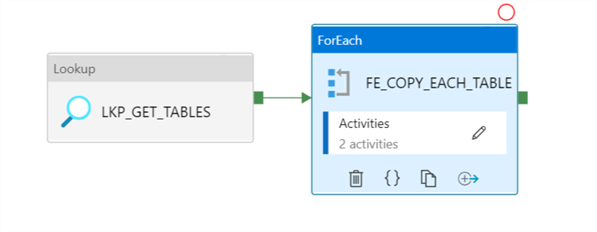
Once the dataset and linked services as created, the following pipeline will look up the list of tables defined in the control table and pass them to a for each loop which will loop over the list of source tables (up 50 batch count in parallel at a time).
Ensure that the lookup and outer foreach loop activity are configured as follows:



The inner activity of the for each loop will then copy the data as parquet format into ADLS2 and will need to be configured as follows:
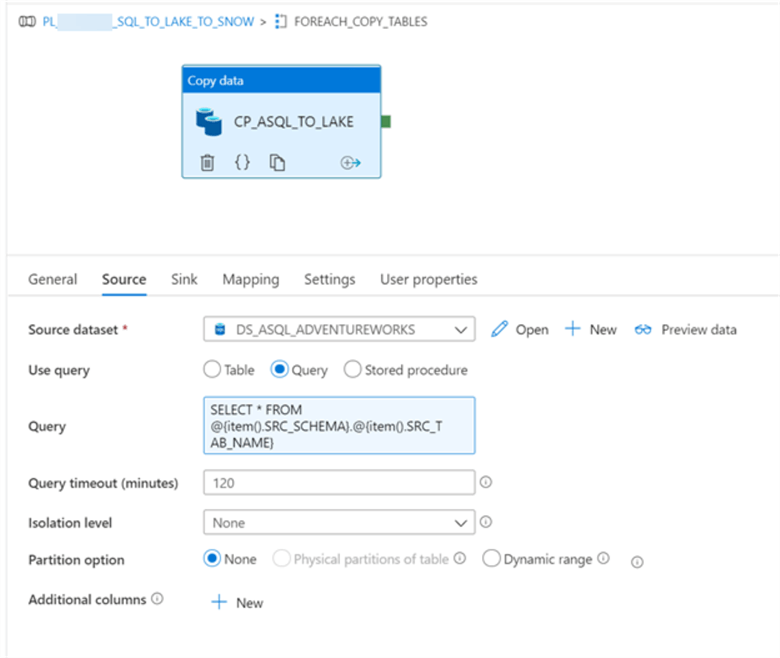

Once the pipeline executed successfully, we can see that all tables were successfully loaded to ADLS2 as parquet format.
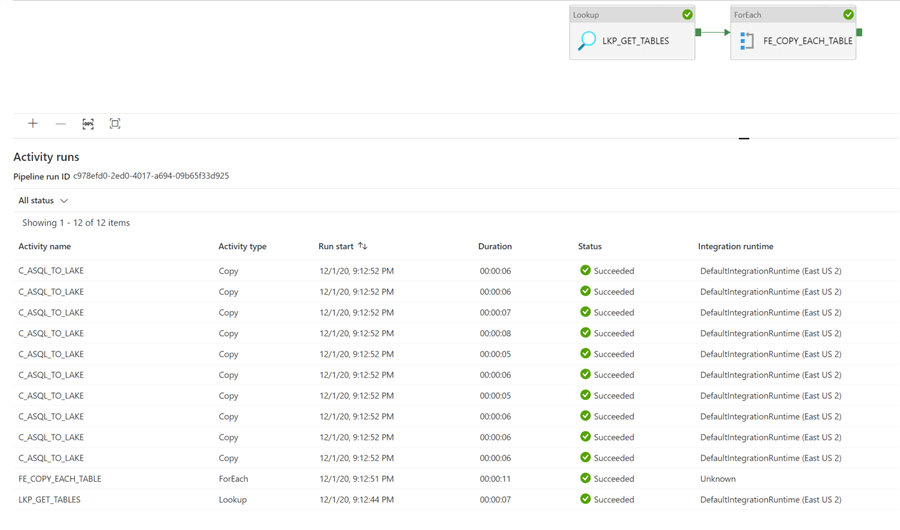
The folder structures are as expected in ADLS2.

Step 2: Design Azure Data Lake Storage Gen2 to Snowflake
Once the files have been landed into ADLS2 as snappy compressed format, there are a few available options for loading the parquet files into Snowflake.
For the Lake to Snowflake ingestion process, the following options have been evaluated in this article:

Option 1: ADLS2 to Snowflake Using Azure Databricks
This option has been tested to ensure parameters can be passed from Data Factory to a parameterized Databricks Notebook and to ensure connectivity and integration between the two services.

Note that the notebook path references the Databricks notebook containing the code.

Within Databricks, the notebook would contain the following Scala code, which accepts the Parameters from the ADF copy activity dynamically and then passes it to a data frame which reads the parquet file based on the dynamic parameters and then writes it to the Snowflake table.
import org.apache.spark.sql.{SaveMode, SparkSession}
spark.conf.set(
"fs.azure.account.key.adl001.dfs.core.windows.net",
"ENTER-ACCOUNT-KEY-HERE"
)
val DST_TAB_NAME = dbutils.widgets.get("DST_TAB_NAME")
val DST_SCHEMA = dbutils.widgets.get("DST_SCHEMA")
val FOLDER_PATH = dbutils.widgets.get("FOLDER_PATH")
var options = Map(
"sfUrl" -> "px.east-us-2.azure.snowflakecomputing.com",
"sfUser" -> "USERNAME",
"sfPassword" -> "PW",
"sfDatabase" -> "ADVENTUREWORKS",
"sfSchema" -> DST_SCHEMA,
"truncate_table" -> "ON",
"usestagingtable" -> "OFF",
"sfWarehouse" -> "COMPUTE_WH"
)
val df = spark.read.parquet("abfss://poc@gze2np1adl001.dfs.core.windows.net/"+FOLDER_PATH+DST_TAB_NAME)
df.write
.format("snowflake")
.options(options)
.option("dbtable", DST_TAB_NAME)
.mode(SaveMode.Overwrite)
.save()

Option 2: ADLS2 to Snowflake Using ADF Copy Activity
This option will use all Data Factory native tooling using the regular Copy Activity.

Additionally, this option will require Azure Blob Storage service to be created and configured and it requires SAS Uri authentication only for the Blob Linked service connection.



Note that in the settings section, staging will need to be enabled and linked to a service.

Option 3: ADLS2 to Snowflake Using Mapping Dataflows
This option will use all Data Factory native tooling along with spark compute within Mapping Data Flows.


Within the mapping dataflows activity there is source connection to the ADLS2 account and a destination that references the target Snowflake account.


Note that within the destination settings, we have specified a ‘Recreate table’ action.

There are other valuable features within the Mapping section to skip duplicates.
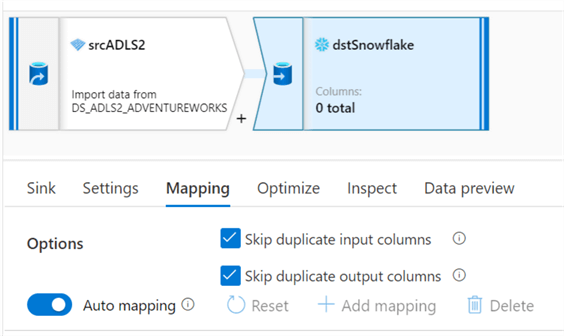
Additionally, there are options for Optimizing partitioning.

Comparing the Various ADLS2 to Snowflake Options
Below are a few noted comparisons of the executed pipelines for all three activities.
| Parameterized Databricks Notebook | Data Factory Mapping Data Flows | Data Factory Copy Activity | |
|---|---|---|---|
| Data type mapping Issues | None noted from AdventureWorks sample tables | Binary Datatypes are causing errors | Binary Datatypes are causing errors |
| Dynamic Auto-Create Table Capability | Yes (Currently, the Auto-create table process is maxing out data types in Snowflake) | Yes (Currently, the Auto-create table process is maxing out data types in Snowflake) | No (Currently, there is no out of box capability to dynamically auto-create tables) |
| Dynamic Auto-Truncate Capability | Yes | Yes | Yes |
| Pipeline Activity Audit Capturing Capability | Yes | Yes | Yes |
| Intermediate Blob Staging Needed | No | No | Yes |
| SAS URI Authentication Needed | No | No | Yes |
| Cluster Warm Up Time or Running State Needed | Yes (Approximately 5 minutes for Databricks cluster to warm up; Capability to specify Core count, compute type and Time To Live) | Yes (Approximately 5 minutes for Mapping Data Flows cluster to warm up; Capability to specify Core count, compute type and Time To Live) | No |
| Capability to specify Compute & Core Count | Yes | Yes | N/A (This activity does not utilize Spark compute) |
| Capability to manage Schema Drift / Evolution | Yes | Yes | N/A |
| Capability to Optimize Partitions | Yes | Yes | N/A |
| Capability to Append Libraries (jar,egg,wheel) | Yes | Yes | N/A (This activity does not utilize Spark compute, hence no Append Library capability |
| Capability to Run Parallel activities | Yes | Yes | Yes |
Swim Lanes
ADF currently has the capability of running 50 tables at a time in parallel and if there is a need to run large number of tables in parallel, an attribute has been added to the control table called “SWIM_LANE” which will assign a unique number to a set of tables which can all be run in one set of activity by filtering on the swim_lane column.
The following code will update the table to create the swim_lane column.
update ADF_DB.ETL.PIPELINE_CTL PL1 set swim_lane = 2 from (select src_tab_name, row_number() over (order by src_tab_name ) as rn from ADF_DB.ETL.PIPELINE_CTL) b where PL1.src_tab_name = b.src_tab_name and b.rn > 5
Data validation
It is essential to perform a basic sanity check via validation of the number of rows that were copied from source Azure SQL database server to ADLS Gen2 and from there to final destination of snowflake target set of tables.
This level of detailed information is captured in a control table on the snowflake table AUDIT_TAB and accepts parameters from the Databricks notebook which is dynamically passed from the lookup of the control table.

create or replace TABLE AUDIT_TAB ( PIPELINE_NAME VARCHAR(100), SRC_DB_NAME VARCHAR(20), DEST_DB_NAME VARCHAR(20), SCH_NAME VARCHAR(20), TABLE_NAME VARCHAR(50), SOURCE_COUNT NUMBER(38,0), ADLS_COUNT NUMBER(38,0), SNOWFLAKE_COUNT NUMBER(38,0), LOAD_TIME TIMESTAMP_NTZ(9) DEFAULT CURRENT_TIMESTAMP() );
Next Steps
- Read more about the Snowflake connector for Spark Notebooks from Databricks.
- Read more about the Snowflake connector for Spark Notebooks from Microsoft.
- Read more about Pushing Spark Query Processing to Snowflake.
- Read more about Configuring Snowflake for Spark in Databricks.
- Read more about the Internal Workings of Spark-Snowflake Connector.

Ron C. L’Esteve is a Data and AI Leader and professional Author residing in Chicago, IL, USA. He is well-known for his impactful books and article publications on Azure Data & AI Architecture, Engineering, and Leadership. Ron holds a Master of Business Administration (M.B.A.) and Master of Science in Corporate Finance (M.S.F.) from Loyola University Chicago. Ron possesses deep technical skills and experience in designing, implementing, leading, and delivering modern Azure Data & AI projects for numerous clients around the world. He is a Motorola Certified Six Sigma Green Belt, a Microsoft Global Challenger, and also holds numerous additional Microsoft, Snowflake, and Databricks professional certifications in Big Data Engineering, Artificial Intelligence, Apache Spark and Data Platform Architecture.
- MSSQLTips Awards: Champion (100+ tips) – 2023 | Author of the Year – 2020-2021 | Rookie of the Year – 2019



Hello,
Thank you for your information. But I need few more settings to know for –
1. LKP_GET_TABLES
2. C_ASQL_TO_LAKE
I need it to complete my activity.