Problem
While working with Azure Data Lake Gen2 and Apache Spark, I began to learn about both the limitations of Apache Spark along with the many data lake implementation challenges. I also learned that an ACID compliant feature set is crucial within a lake and that a Delta Lake offers many solutions to these existing issues. What is a Delta Lake and why do we need an ACID compliant lake? What are the benefits of Delta Lake and what is a good way of getting started with Delta Lake?
Solution
Delta Lake is an open source storage layer that guarantees data atomicity, consistency, isolation, and durability in the lake. In short, a Delta Lake is ACID compliant. In addition to providing ACID transactions, scalable metadata handling and more, Delta Lake runs on an existing Data Lake and is compatible with Apache Spark APIs. There are a few methods of getting started with Delta Lake. Databricks offers notebooks along with compatible Apache Spark APIs to create and manage Delta Lakes. Alternatively, Azure Data Factory’s Mapping Data Flows, which uses scaled-out Apache Spark clusters, can be used to perform ACID compliant CRUD operations through GUI designed ETL pipelines. This article will demonstrate how to get started with Delta Lake using Azure Data Factory’s new Delta Lake connector through examples of how to create, insert, update, and delete in a Delta Lake.
Why an ACID Delta Lake
There are many advantages to introducing Delta Lake into a Modern Cloud Data architecture. Traditionally, Data Lakes and Apache Spark are not ACID compliant. Delta Lake introduces this ACID compliance to solve many the following ACID compliance issues.
Atomicity: Write either All Data or Nothing. Apache Spark save modes do not utilize any locking and are not atomic. With this, a failed job may leave an incomplete file and may corrupt data. Additionally, a failing job may remove the old file and corrupt the new file. While this seems concerning, Spark does have in built data frame writer APIs that are not atomic but behaves so for append operations. This however does come with performance overhead for use with cloud storage.
Consistency: Data is always in a valid state. If the Spark API writer deletes an old file and creates a new one and the operation is not transactional, then there will always be a period of time when the file does not exist between the deletion of the old file and creation of the new. In that scenario, if the overwrite operation fails, this will result in data loss of the old file. Additionally, the new file may not be created. This is a typical spark overwrite operation issue related to Consistency.
Isolation: Multiple transactions occur independently without interference. This means that when writing to a dataset, other concurrent reads or writes on the same dataset should not be impacted by the write operation. Typical transactional databases offer multiple isolation levels. While Spark has task and job level commits, since it lacks atomicity, it does not have isolation types.
Durability: Committed Data is never lost. When Spark does not correctly implement a commit, then it overwrites all the great durability features offered by cloud storage options and either corrupts and/or loses the data. This violates data Durability.
Now that we have an understanding of the current data lake and spark challenges along with benefits of an ACID compliant Delta Lake, let’s get started with the Demo.
Pre-Requisites
For this Demo, be sure to successfully create the following pre-requisites.
1) Create a Data Factory V2: Data Factory will be used to perform the ELT orchestrations. Additionally, ADF’s Mapping Data Flows Delta Lake connector will be used to create and manage the Delta Lake. For more detail on creating a Data Factory V2, see Quickstart: Create a data factory by using the Azure Data Factory UI.
2) Create a Data Lake Storage Gen2: ADLSgen2 will be the Data Lake storage on top of which the Delta Lake will be created.
3) Create Data Lake Storage Gen2 Container and Zones: Once your Data Lake Gen2 is created, also create the appropriate containers and Zones. For more information on designing ADLS Gen2 Zones, see: Building your Data Lake on Azure Data Lake Storage gen2. This demo will use the Raw Zone to store a sample source parquet file. Additionally, the Staging Zone will be used for Delta Updates, Inserts, Deletes and additional transformations. Though the Curated Zone will not be used in this demo, it is important to mention that this zone may contain the final E-T-L, advanced analytics, or data science models that are further transformed and curated from the Staging Zone.
4) Upload Data to Raw Zone: Finally, you’ll need some data for this demo. By searching for ‘sample parquet files’, you’ll obtain access to a number of online GitHub Repos or sample downloadable data. The following GitHub Repo data was used for this demo.

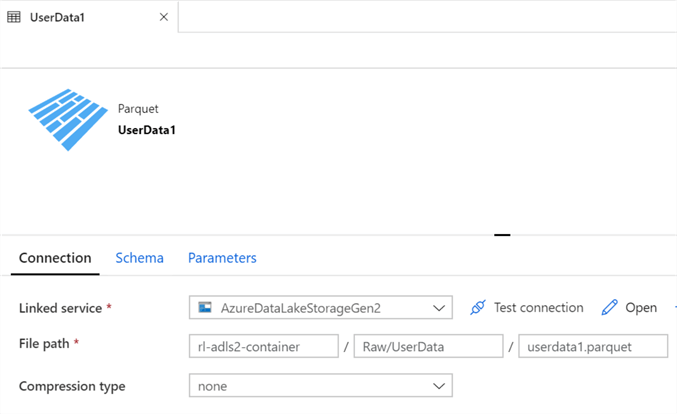
5) Create a Data Factory Parquet Dataset pointing to the Raw Zone: The final pre-requisite would be to create a parquet format dataset in the newly created instance of ADF V2 pointing to the sample parquet file stored in the Raw Zone.
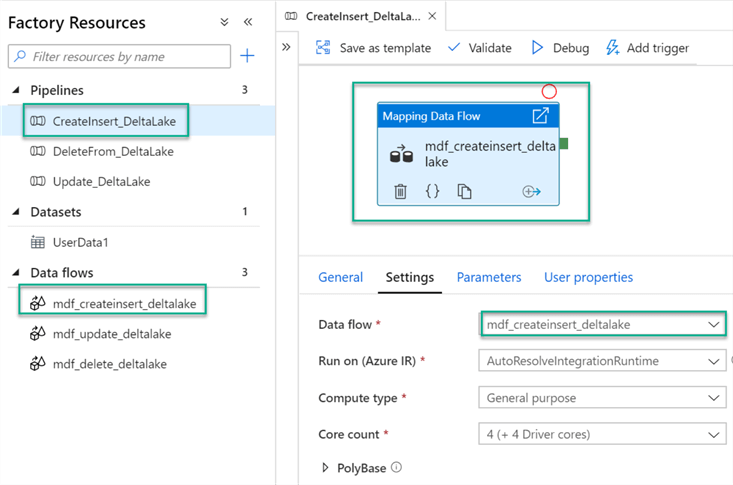
Create and Insert into Delta Lake
Now that all pre-requisites are in place, we are ready to create the initial delta tables and insert data from our Raw Zone into the delta tables.
Let’s begin by creating a new Data Factory pipeline and adding a new ‘Mapping Data Flow’ to it. Also remember to name the Pipeline and Data Flows sensible names, much like the sample below.
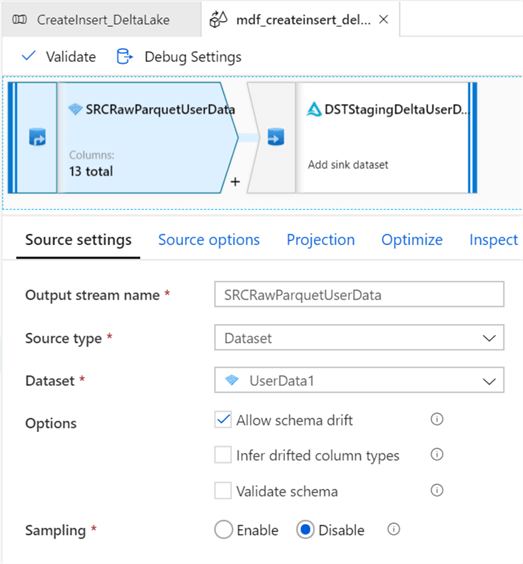
Within the Data Flow, add a source and sink with the following configurations. Schema Drift may be enabled as needed for the specific use case.
For more detail on Schema Drift, see Schema drift in mapping data flow.
Sampling offers a method to limit the number of rows from the source, mainly used for testing and debugging purposes.
Since Delta Lake leverages Spark’s distributed processing power, it is capable of partitioning data appropriately, however, for purposes of demoing the capability of manually setting partitioning, I’ve configured 20 Hash partitions on the ID column. Click here, read more about the various options for Partition Types.
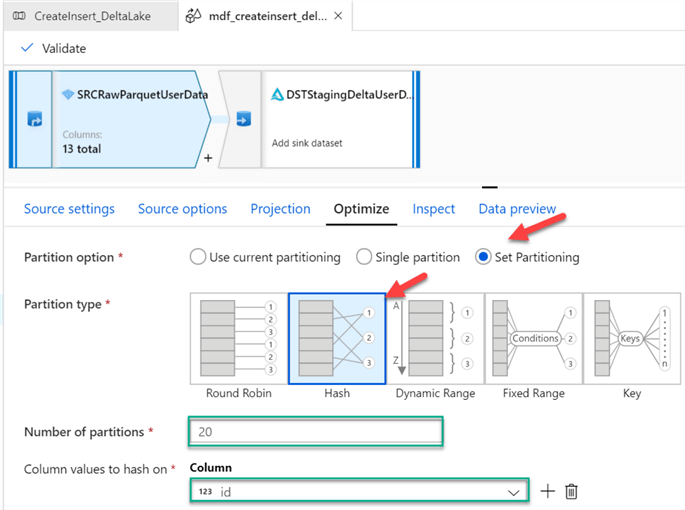
After, adding the destination activity, ensure that the sink type is set to Delta. For more information on delta in ADF, see Delta format in Azure Data Factory. Note that Delta is available as both a source and sink in Mapping Data Flows. Also, you will be required to select the Linked Service once the sink type of Delta is selected.
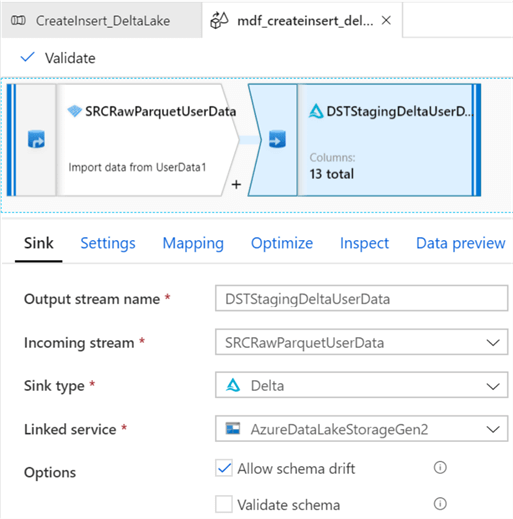
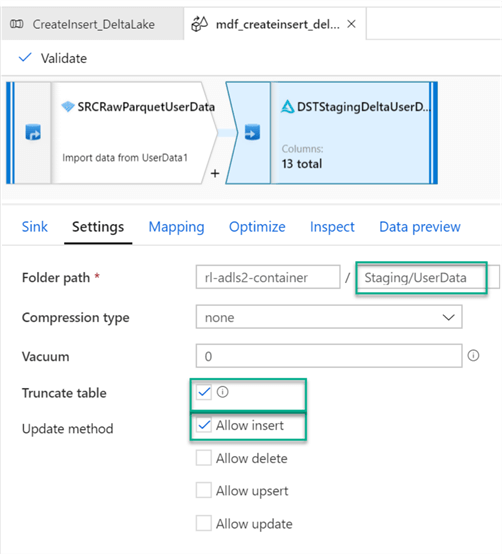
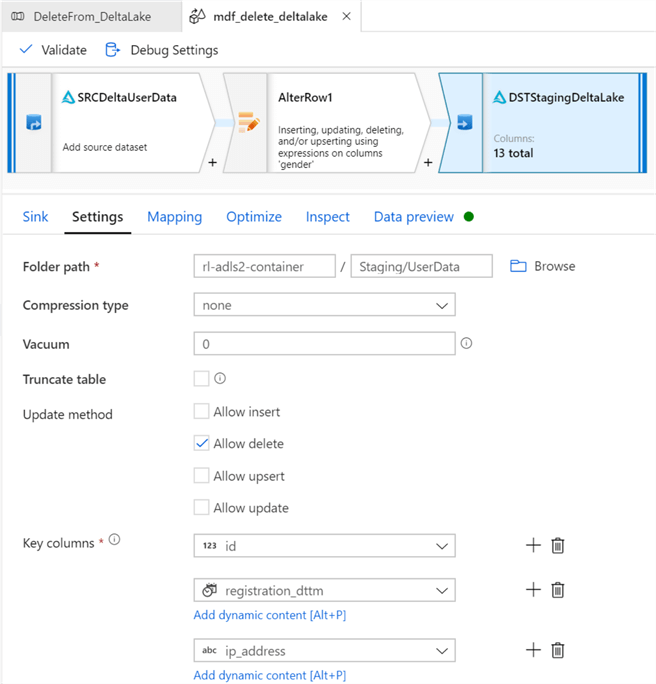
Under the Settings tab, ensure that the Staging folder is selected and select Insert for the Update Method. Also, select Truncate table if there is a need to truncate the Delta Table before loading it.
For more information on Vacuum Command, see: Vacuum a Delta table (Delta Lake on Databricks). Essentially, Vacuum will remove files that are no longer referenced by delta tables and are older than the retention threshold in hours. The default is 30 days if the value is left at 0 or empty.
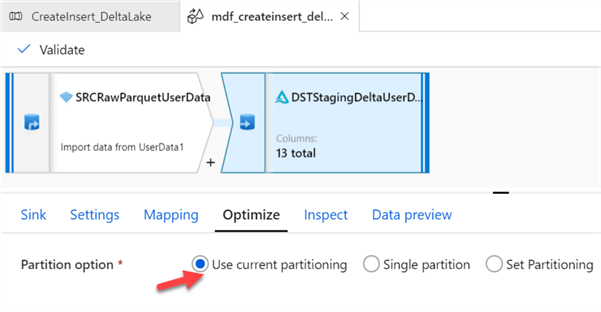
Finally, within the Optimize tab, simply use the current partitioning since the source partitioning with flow downstream to the sink.
As expected, once the pipeline is triggered and completed running, we can see that there are 13 new columns created across 20 different partitions.
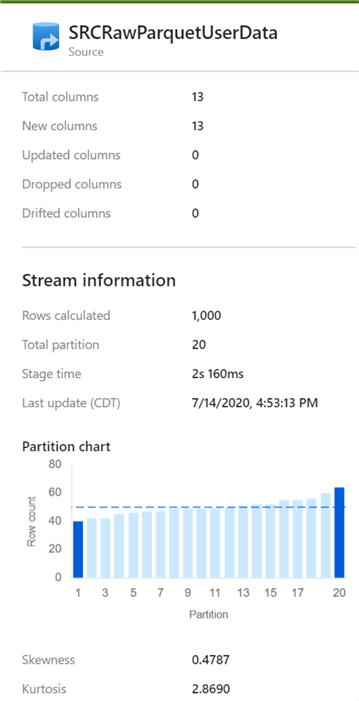
While looking at the ADLS2 staging folder, we see that a delta_log folder along with 20 snappy compressed parquet files have been created.
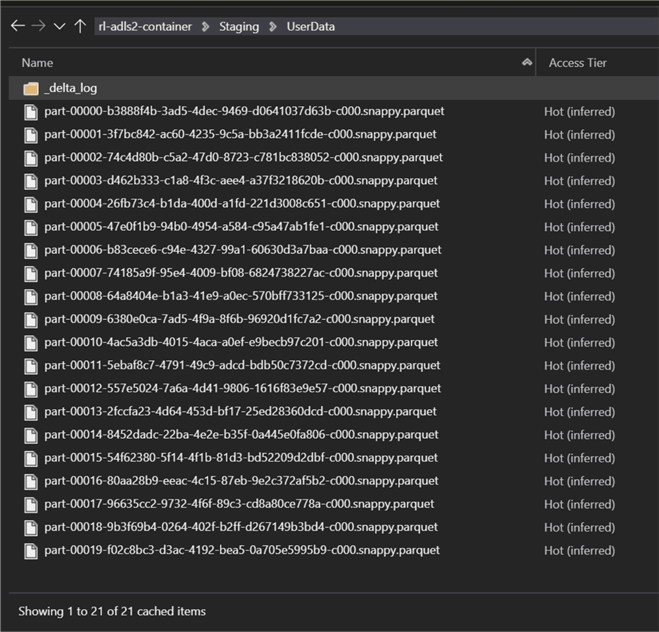
Open the delta_log folder to view the two log files. For more information on understanding the delta logs, read: Diving Into Delta Lake: Unpacking The Transaction Log.
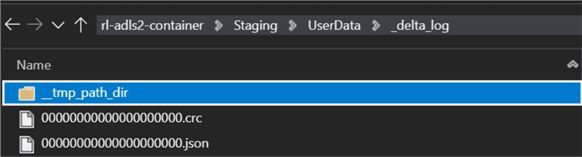
After checking the new data in the Staging Delta Lake, we can see there are new records inserted.
Update Delta Lake
So far, we have covered Inserts into the Delta Lake. Next, let’s take a look at how Data Factory can handle Updates to our delta tables.
Similar to inserts, create a new ADF pipeline with a mapping data flow for Updates.
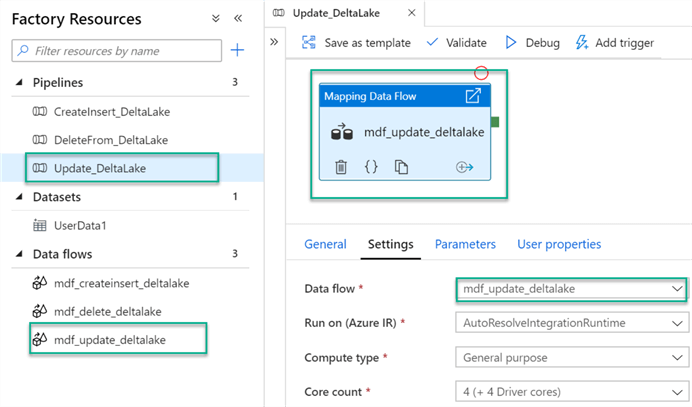
For this Update demo, let’s update the first and last name of the user and convert it to lower case. To do this, we add a Derived Columns and Alter Row transform activity to the Update Mapping Data Flow canvas.
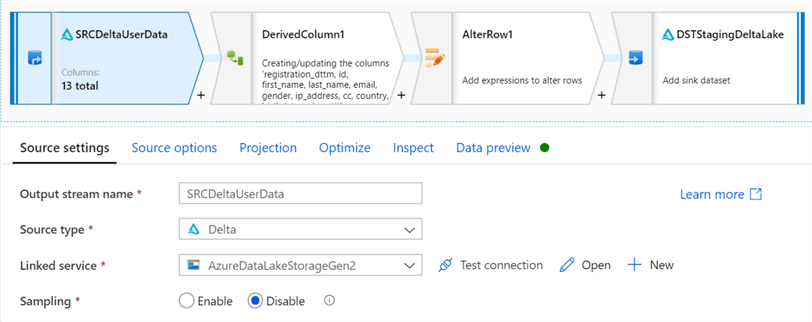
The source data is still our Staging Delta Lake that was also configured for the Inserts. For more detail on Time Travel, see: Introducing Delta Time Travel for Large Scale Data Lakes.
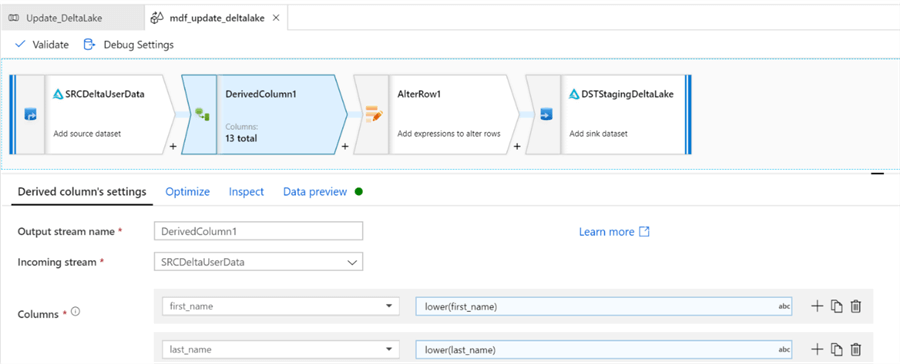
The derived columns convert first and last name to lower case using the following expressions. Mapping Data Flows is capable of handling extremely complex transformations in this stage.
For the alter row settings, we need to specify an Update if condition of true() to update all rows that meet the criteria.
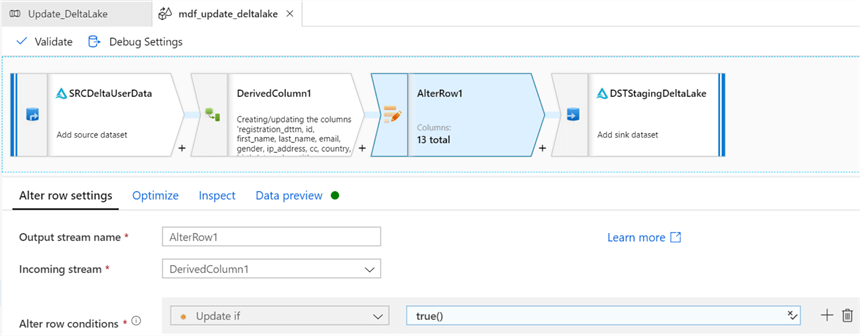
Verify the sink configurations.
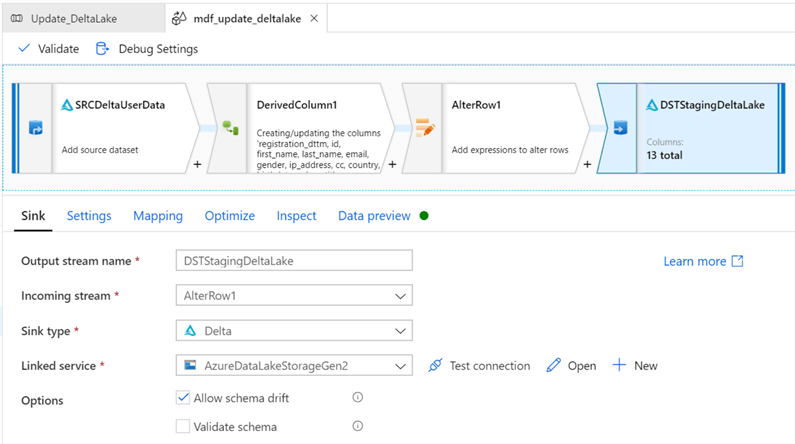
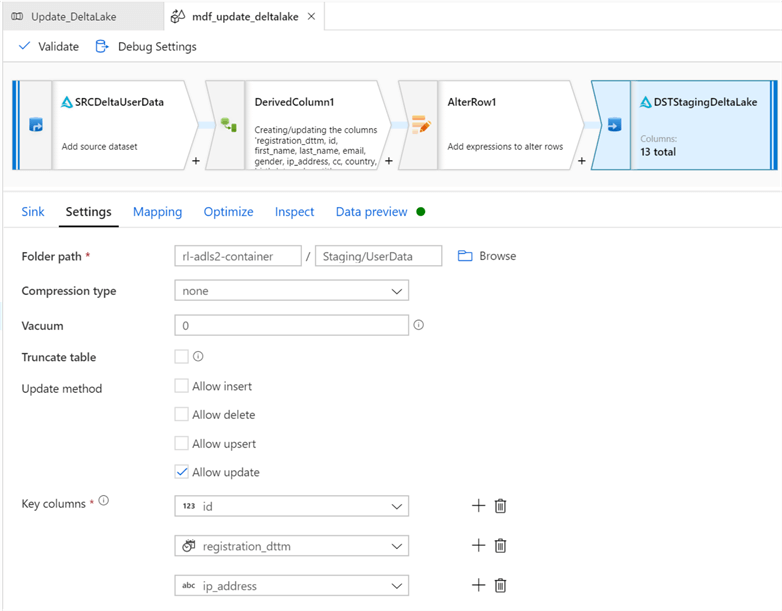
Ensure that the sink is still pointing to the Staging Delta Lake data. Also, select Allow Update as the update method. To show that multiple key columns can be simultaneously selected, there are 3 columns selected.
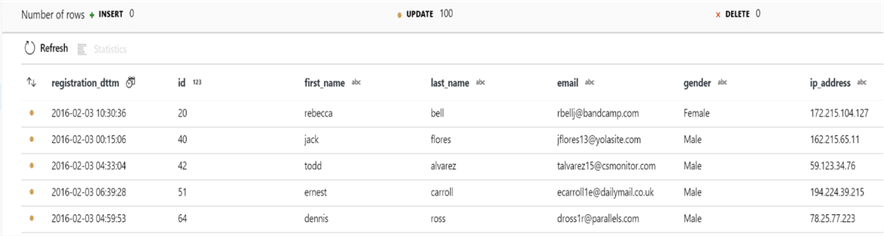
After the pipeline is saved and triggered, we can see that the results reflect the first and last names have been updated to lower case values.
Delete from Delta Lake
To recap, we have covered Inserts and Updates till now. Next, let’s look at an example of how Mapping Data Flows handles deletes in Delta Lake.
Similar to the Inserts and Updates, create a new Data Factory and Mapping Data Flow.
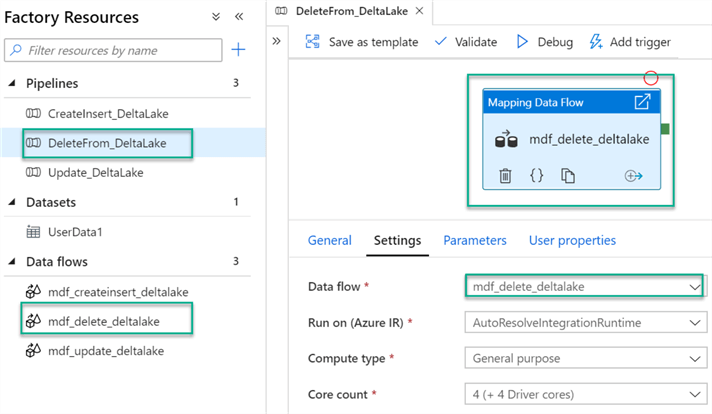
Configure the Delta source settings.
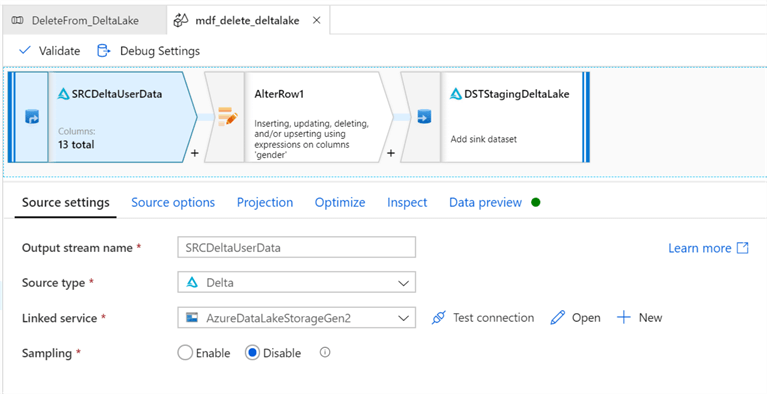
Since we are still working with the same Staging Delta Lake, these source settings will be configured similar to Inserts and Updates.
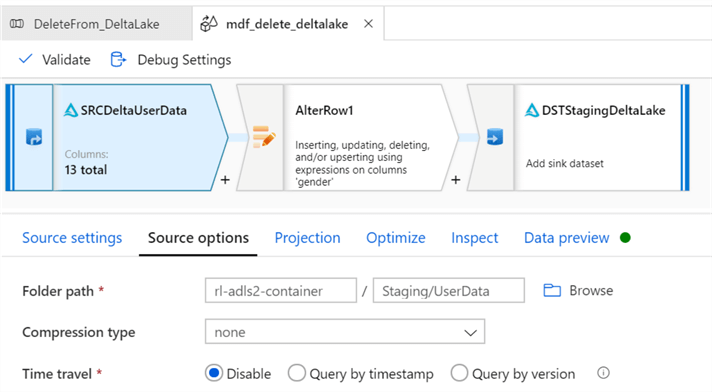
For this example, let’s delete all records were gender = male. To do this, we need to configure the alter row conditions to Delete if gender == ‘Male’.
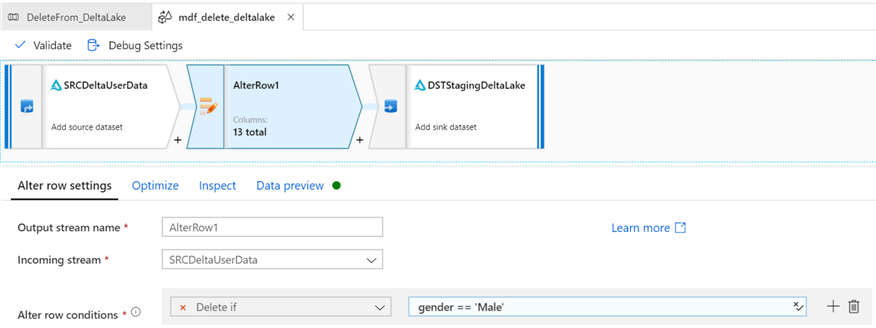
Finally, configure the sink delta settings.
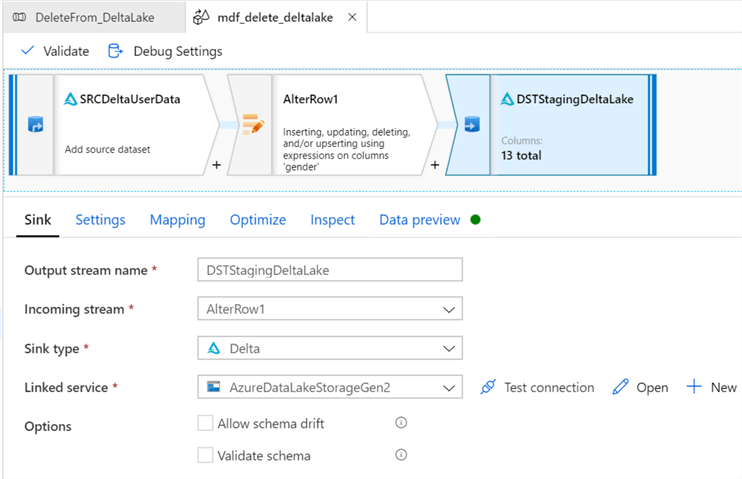
Select the Staging Delta Lake for the sink, select ‘Allow Delete’ and select the desired key columns.
After publishing and triggering this pipeline, notice how all records where gender = Male have been deleted.

Explore Delta Logs
Lastly, let’s go ahead and take a look at the Delta Logs to briefly understand how the logs have been created and populated. The main commit info files are generated and stored in the Insert, Update, and Delete JSON commit files. Additionally, CRC files are created. CRC is a popular technique for checking data integrity as it has excellent error detection abilities, uses little resources and is easily used.
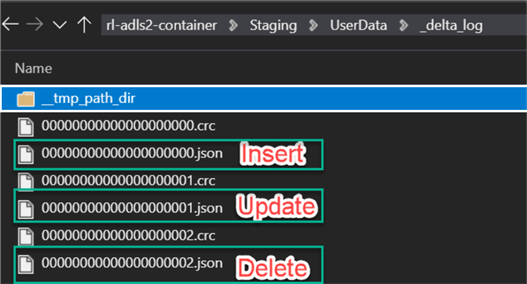
Insert
As we can see from opening the Insert JSON commit file, it contains commit info for the insert operations.
{"commitInfo":{"timestamp":1594782281467,"operation":"WRITE","operationParameters":{"mode":"Append","partitionBy":"[]"},"isolationLevel":"WriteSerializable","isBlindAppend":true}}

Update
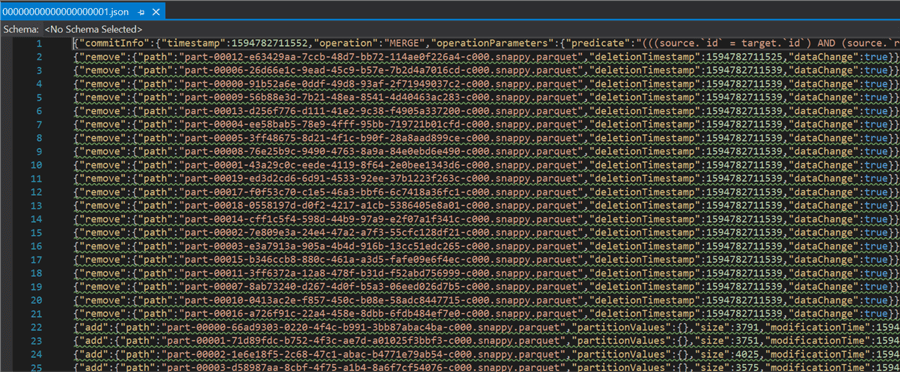
Similarly, when we open the Update JSON commit file, it contains commit info for the update operations.
{"commitInfo":{"timestamp":1594782711552,"operation":"MERGE","operationParameters":{"predicate":"(((source.`id` = target.`id`) AND (source.`registration_dttm` = target.`registration_dttm`)) AND (source.`ip_address` = target.`ip_address`))","updatePredicate":"((NOT ((source.`ra2b434a305b34f2f96cd5b4b4149455e` & 2) = 0)) OR (NOT ((source.`ra2b434a305b34f2f96cd5b4b4149455e` & 8) = 0)))","deletePredicate":"(NOT ((source.`ra2b434a305b34f2f96cd5b4b4149455e` & 4) = 0))"},"readVersion":0,"isolationLevel":"WriteSerializable","isBlindAppend":false}}
Delete
Lastly, when we open the Delete JSON commit file, it contains commit info for the Delete operations.
"commitInfo":{"timestamp":1594783812366,"operation":"MERGE","operationParameters":{"predicate":"(((source.`id` = target.`id`) AND (source.`registration_dttm` = target.`registration_dttm`)) AND (source.`ip_address` = target.`ip_address`))","updatePredicate":"((NOT ((source.`ra079d97a688347b581710234d2cc4b63` & 2) = 0)) OR (NOT ((source.`ra079d97a688347b581710234d2cc4b63` & 8) = 0)))","deletePredicate":"(NOT ((source.`ra079d97a688347b581710234d2cc4b63` & 4) = 0))"},"readVersion":1,"isolationLevel":"WriteSerializable","isBlindAppend":false}}
Next Steps
- For more detail related to Delta Lake, read the following Databricks documentation.
- For more information on understanding the Delta Lake logs, read Diving Into Delta Lake: Unpacking The Transaction Log.
- For more information on the Delta connector in Azure Data Factory, see Delta format in Azure Data Factory.
- Explore Delta Engine as an efficient way to process data in data lakes including data stored in open source Delta Lake.

Ron C. L’Esteve is a Data and AI Leader and professional Author residing in Chicago, IL, USA. He is well-known for his impactful books and article publications on Azure Data & AI Architecture, Engineering, and Leadership. Ron holds a Master of Business Administration (M.B.A.) and Master of Science in Corporate Finance (M.S.F.) from Loyola University Chicago. Ron possesses deep technical skills and experience in designing, implementing, leading, and delivering modern Azure Data & AI projects for numerous clients around the world. He is a Motorola Certified Six Sigma Green Belt, a Microsoft Global Challenger, and also holds numerous additional Microsoft, Snowflake, and Databricks professional certifications in Big Data Engineering, Artificial Intelligence, Apache Spark and Data Platform Architecture.
- MSSQLTips Awards: Champion (100+ tips) – 2023 | Author of the Year – 2020-2021 | Rookie of the Year – 2019


Hi Ron,
Great demo ! Thanks. Is there a way to add a runtime column ?
Rgds
Hi Ron,
I tried the Upsert , at every execution all the records are reinserted , do you have an work arround ?
Hello,
Can we time travel back to where you didn’t delete all the males?
Regards,
Hebi
Hello,
To verify the results, I used Azure Data Factory’s Mapping Data Flows ‘Data Preview’ tab in the Delta Lake sink ‘DSTStagingDeltaLake’. Also, ‘debug mode’ will need to be enabled to view results in Data Preview.
Thank You
Ron L
“After the pipeline is saved and triggered, we can see that the results reflect the first and last names have been updated to lower case values” – Could you please tell me which azure app/services or how you are checking the final results. I am confused.