Problem
Navigating through the complex offerings within Azure SQL Data Warehouse can become a daunting task while designing tables and managing workloads. Questions around distributed tables and when to use round robin, hash, and replicated tables might frequently arise. Additionally, Azure SQL Data Warehouse enthusiasts might be interested in understanding more about partitions and general workload management to build more robust solutions with Azure SQL Data Warehouse.
Solution
This article aims to describe some of the data design and data workload management features of Azure SQL Data Warehouse. I’ll go over practical examples of when and how to use hash versus round robin distributed tables, how to partition swap, how to build replicated tables, and lastly how to manage workloads in Azure SQL Data Warehouse.
Creating an Azure SQL Datawarehouse
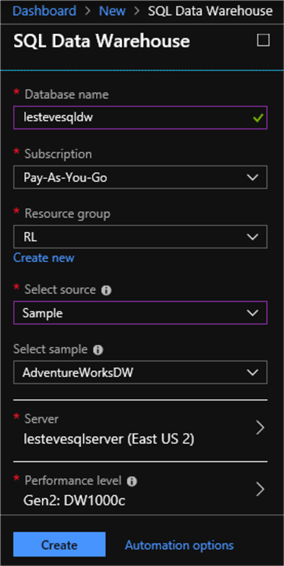
I will begin by creating a new Azure SQL DW by navigating to the Azure Portal and create a new Azure SQL DW database resource.

Next, I will enter my database name, resource group, and various other pertinent details. I will also make sure to select the AdventureWorksDW sample data source that I can query and work with in the following steps.
Designing Distributed Tables
The two types of main data distributions that we can use to create tables in Azure SQL Datawarehouse are hash and Round Robin distributed tables.
Round-Robin Distribution
Round Robin is the default distribution type for a table in a SQL Data Warehouse and the data for a round-robin distributed table is distributed evenly across all the distributions. As data gets loaded, each row is simply sent to the next distribution to balance the data across distributions. Usually common dimension tables or staging tables or tables that doesn’t distribute data evenly are good candidates for round-robin distributed tables.
Let’s view an example of a round robin distributed table. I will start by creating a round-robin distributed table:
IF OBJECT_ID('dbo.OrdersRR', 'U') IS NOT NULL
DROP TABLE dbo.OrdersRR;
GO
CREATE TABLE OrdersRR (
OrderID int IDENTITY(1, 1) NOT NULL,
OrderDate datetime NOT NULL,
OrderDescription char(15) DEFAULT ' NewOrdersRR'
) WITH ( CLUSTERED INDEX (OrderID), DISTRIBUTION = ROUND_ROBIN );
Next, I will write some code to enter rows of data into the newly created table:
SET NOCOUNT ON DECLARE @i INT SET @i = 1 DECLARE @date DATETIME SET @date = dateadd(mi, @i, '2018-01-29') WHILE (@i <= 60) BEGIN INSERT INTO [OrdersRR] (OrderDate) SELECT @date SET @i = @i + 1; END
Now that I have data in my Round Robin Distributed Table, I can use the following query which makes use of the SQL DW DMVs to show how data was distributed across the distributions using the round robin distribution method.
SELECT
o.name AS tableName,
pnp.pdw_node_id,
pnp.distribution_id,
pnp.rows
FROM
sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS NTables ON pnp.object_id = NTables.object_id
AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS TMap ON NTables.name = TMap.physical_name
AND substring(TMap.physical_name, 40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
WHERE
o.name in ('orders')
ORDER BY
distribution_idIn the results, I can see that the data was distributed somewhat evenly across the 60 distributions.

Hash Distribution
Data for the hash distributed table gets distributed across multiple distributions and eventually gets processed by multiple compute nodes in parallel across all the compute nodes. Fact tables or large tables are good candidates for hash distributed tables. You select one of the columns from the table to use as the distribution key column when creating a hash distributed table and then SQL Data Warehouse automatically distributes the rows across all 60 distributions based on distribution key column value.
Let’s explore this distribution type by creating a Hash Distributed Table with the following SQL Code:
CREATE TABLE OrdersH ( OrderID int IDENTITY(1, 1) NOT NULL, OrderDate datetime NOT NULL, OrderDescription char(15) DEFAULT 'NewOrdersH' ) WITH ( CLUSTERED INDEX (OrderID), DISTRIBUTION = HASH(OrderDate) );
Again, I will write some code to enter rows of data into the newly created table:
SET NOCOUNT ON DECLARE @i INT SET @i = 1 DECLARE @date DATETIME SET @date = dateadd(mi, @i, '2017-02-04') WHILE (@i <= 60) BEGIN INSERT INTO [Orders2] (OrderDate) SELECT @date SET @i = @i + 1; END
Now that I have data in my Hash Distributed Table, I can use the following query which makes use of the SQL DW DMVs to show how data was distributed across the distributions using the hash distribution method.
SELECT
o.name AS tableName,
pnp.pdw_node_id,
pnp.distribution_id,
pnp.rows
FROM
sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS NTables ON pnp.object_id = NTables.object_id
AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS TMap ON NTables.name = TMap.physical_name
AND substring(TMap.physical_name, 40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
WHERE
o.name in ('OrdersH')The query results show that all the rows went into the same distribution because the same date was used for each row and the SQL Data Warehouse hash function is deterministic.

Replicate Distribution
Replicated tables eliminate the need to transfer data across compute nodes by replicating a full copy of the data of the specified table to each compute node. The best candidates for replicated tables are tables with sizes less than 2 GB compressed and small dimension tables. In this exercise, you will convert an existing round-robin table to a replicated table.
Round-robin tables can be converted to replicated tables, so any hash distributed tables will first need to be converted to a round robin distributed table to more evenly distribute the data across distributions to show data movement.
So once this step is complete, I will run the following SQL Code:
CREATE TABLE [dbo].[DimSalesTerritory_RR] WITH ( CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = ROUND_ROBIN ) AS SELECT * FROM [dbo].[DimSalesTerritory] OPTION ( LABEL = 'CTAS : DimSalesTerritory_RR' ) CREATE TABLE [dbo].[DimDate_RR] WITH ( CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = ROUND_ROBIN ) AS SELECT * FROM [dbo].[DimDate] OPTION (LABEL = 'CTAS : DimDate_RR')
Sure enough, I now have my Round Robin Distributed tables in addition to my Hash tables.

Now I am ready to begin creating my replicated table by running the following SQL Query:
CREATE TABLE [dbo].[DimSalesTerritory_REPLICATED] WITH ( CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = REPLICATE ) AS SELECT * FROM [dbo].[DimSalesTerritory_RR] OPTION (LABEL = 'CTAS : DimSalesTerritory_REPLICATED') CREATE TABLE [dbo].[DimDate_REPLICATED] WITH ( CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = REPLICATE ) AS SELECT * FROM [dbo].[DimDate_RR] OPTION (LABEL = 'CTAS : DimDate_REPLICATED')
Now that my replicated table is created, I will run some comparisons to reveal the move operations.
I’ll start by running a query against my round robin table:
SELECT [TotalSalesAmount] = SUM(SalesAmount) FROM dbo.FactInternetSales s INNER JOIN dbo.DimDate_RR d ON d.DateKey = s.OrderDateKey INNER JOIN dbo.DimSalesTerritory_RR t ON t.SalesTerritoryKey = s.SalesTerritoryKey WHERE d.FiscalYear = 2005 AND t.SalesTerritoryGroup = 'North America' OPTION (LABEL = 'STATEMENT:RRTableQuery');
Next, I will run the same query against my replicated table:
SELECT [TotalSalesAmount] = SUM(SalesAmount) FROM dbo.FactInternetSales s INNER JOIN dbo.DimDate_REPLICATED d ON d.DateKey = s.OrderDateKey INNER JOIN dbo.DimSalesTerritory_REPLICATED t ON t.SalesTerritoryKey = s.SalesTerritoryKey WHERE d.FiscalYear = 2005 AND t.SalesTerritoryGroup = 'North America' OPTION (LABEL = 'STATEMENT:ReplicatedTableQuery1');
Finally, I will compare the 2 queries by running this query, which uses the sys.dm_pdw_exec_requests DMV containing information about all requests currently or recently active in SQL DW, and the sys.dm_pdw_request_steps DMV, which contains information about all the steps that make up a given request or query.
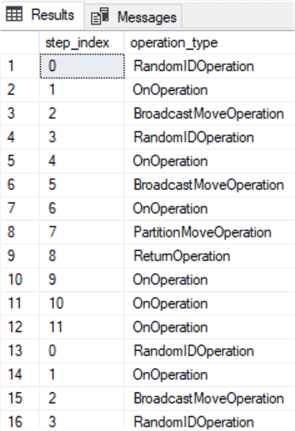
SELECT step_index, operation_type FROM sys.dm_pdw_exec_requests er JOIN sys.dm_pdw_request_steps rs ON er.request_id = rs.request_id WHERE er.[label] = 'STATEMENT:RRTableQuery';
As I can see from the results, there are multiple move operations (indicating data movement) as specified by the operation type ‘BroadcastMoveOperation’, since DimDate_RR and DimSalesTerritory_RR use round-robin distribution.
I’ll run the same query against my Replicated table next:
SELECT step_index, operation_type FROM sys.dm_pdw_exec_requests er JOIN sys.dm_pdw_request_steps rs ON er.request_id = rs.request_id WHERE er.[label] = 'STATEMENT:ReplicatedTableQuery1';
The results reveal no BroadcastMoveOperations, indicating that no more data movement.

Implementing Partitions
Partitions can have benefits to data maintenance and query performance. It can speed up the loading and archiving of data and query performance. Additionally, it enables the query optimizer to only access relevant partitions.
To demonstrate an example of partition switching, I will start by creating an Orders table partitioned by OrderDate:
IF OBJECT_ID('dbo.OrdersPartition', 'U') IS NOT NULL
DROP TABLE dbo.OrdersPartition;
GO
CREATE TABLE OrdersPartition (
OrderID int IDENTITY(1, 1) NOT NULL,
OrderDate datetime NOT NULL,
OrderDescription char(15) DEFAULT 'NewOrder'
) WITH (
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN,
PARTITION (
OrderDate RANGE RIGHT FOR
VALUES
(
'2017-02-05T00:00:00.000', '2017-02-12T00:00:00.000',
'2017-02-19T00:00:00.000', '2017-02-26T00:00:00.000',
'2017-03-05T00:00:00.000', '2017-03-12T00:00:00.000',
'2017-03-19T00:00:00.000'
)
)
);
GONext, I will enter records into the partition table:
SET NOCOUNT ON DECLARE @i INT SET @i = 1 DECLARE @date DATETIME SET @date = dateadd(mi,@i,'2017-02-05') WHILE (@i <= 10) BEGIN INSERT INTO [OrdersPartition] (OrderDate) SELECT @date INSERT INTO [OrdersPartition] (OrderDate) SELECT dateadd(week,1,@date) INSERT INTO [OrdersPartition] (OrderDate) SELECT dateadd(week,2,@date) INSERT INTO [OrdersPartition] (OrderDate) SELECT dateadd(week,3,@date) INSERT INTO [OrdersPartition] (OrderDate) SELECT dateadd(week,4,@date) INSERT INTO [OrdersPartition] (OrderDate) SELECT dateadd(week,5,@date) SET @i = @i+1; END
The following query will show the number of rows in each of the partitions that were created.
SELECT
o.name AS Table_name,
pnp.partition_number AS Partition_number,
sum(pnp.rows) AS Row_count
FROM
sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS NTables ON pnp.object_id = NTables.object_id
AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS TMap ON NTables.name = TMap.physical_name
AND substring(TMap.physical_name, 40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
WHERE
o.name in ('OrdersPartition')
GROUP BY
partition_number,
o.name,
pnp.data_compression_desc;
Next, I will create a table called Orders_Staging which will be used to switch data out of a partition in the production OrdersPartition table.
IF OBJECT_ID('dbo.Orders_Staging','U') IS NOT NULL
DROP TABLE dbo.Orders_Staging;
GO
CREATE TABLE dbo.Orders_Staging
(OrderID int IDENTITY(1,1) NOT NULL
,OrderDate datetime NOT NULL
,OrderDescription char(15) DEFAULT 'NewOrder'
)
GOWhen I run the following query, I’ll see that there is one partition with no data in it.
SELECT
o.name AS Table_name,
pnp.partition_number AS Partition_number,
sum(pnp.rows) AS Row_count
FROM
sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS NTables ON pnp.object_id = NTables.object_id
AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS TMap ON NTables.name = TMap.physical_name
AND substring(TMap.physical_name, 40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
WHERE
o.name in ('Orders_Staging')
GROUP BY
partition_number,
o.name,
pnp.data_compression_desc;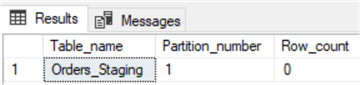
The following query will switch out the data out of partition 3 of the OrdersPartition table into the default partition of the Orders_Staging table.
ALTER TABLE dbo.OrdersPartition SWITCH PARTITION 3 to dbo.Orders_Staging
Once the query completes, I the following query will give me the partition information for both tables.
SELECT
o.name AS Table_name,
pnp.partition_number AS Partition_number,
sum(pnp.rows) AS Row_count
FROM
sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS NTables ON pnp.object_id = NTables.object_id
AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS TMap ON NTables.name = TMap.physical_name
AND substring(TMap.physical_name, 40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
WHERE
o.name in ('OrdersPartition')
GROUP BY
partition_number,
o.name,
pnp.data_compression_desc;
SELECT
o.name AS Table_name,
pnp.partition_number AS Partition_number,
sum(pnp.rows) AS Row_count
FROM
sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS NTables ON pnp.object_id = NTables.object_id
AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS TMap ON NTables.name = TMap.physical_name
AND substring(TMap.physical_name, 40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
WHERE
o.name in ('Orders_Staging')
GROUP BY
partition_number,
o.name,
pnp.data_compression_desc;
The results indicate that 10 rows in partition 3 in the OrdersPatition table have moved to the default partition in the Orders_Staging table.

Managing Workloads
Next, I will go over a DMV that helps analyze query prioritization for SQL DW workloads.
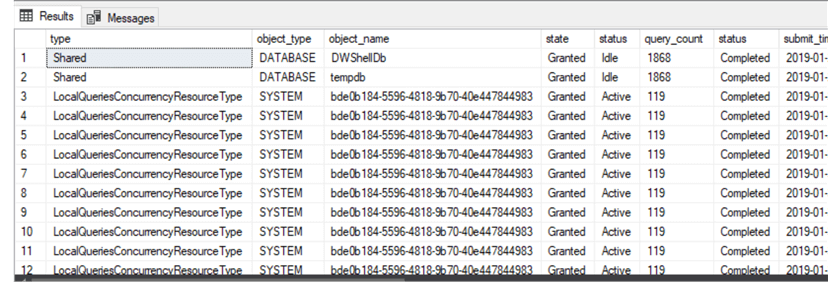
The query results show critical information, such as the actual T-SQL statement, the status of the query, the query count, and its start time and end time. It also shows, type resource class type was used as well as which resources current or recently executed queries were waiting for.
SELECT w.[type], w.[object_type], w.[object_name], w.[state], es.[status], es.query_count, er.[status], er.submit_time, er.start_time, er.end_time, er.total_elapsed_time, er.[label], er.resource_class, er.command FROM sys.dm_pdw_exec_requests er JOIN sys.dm_pdw_exec_sessions es ON er.session_id = es.session_id JOIN sys.dm_pdw_waits w ON es.session_id = w.session_id
LocalQueriesConcurrencyResourceType wait type signifies that the query is sitting outside of the concurrency slot framework. UserConcurrencyResourceType wait type means that queries are inside the concurrency slot and are awaiting execution within the workload group.
Next Steps
- Read Best practices for Azure SQL Data Warehouse to help achieve optimal performance while working with Azure SQL Datawarehouse.
- Microsoft’s Cheat sheet for Azure SQL Data Warehouse provides helpful tips and best practices for building your Azure SQL Data Warehouse solutions.
- For detailed explanation of what SQL Data Warehouse is and what it is not, check out Azure SQL Data Warehouse Workload Patterns and Anti-Patterns.

Ron C. L’Esteve is a Data and AI Leader and professional Author residing in Chicago, IL, USA. He is well-known for his impactful books and article publications on Azure Data & AI Architecture, Engineering, and Leadership. Ron holds a Master of Business Administration (M.B.A.) and Master of Science in Corporate Finance (M.S.F.) from Loyola University Chicago. Ron possesses deep technical skills and experience in designing, implementing, leading, and delivering modern Azure Data & AI projects for numerous clients around the world. He is a Motorola Certified Six Sigma Green Belt, a Microsoft Global Challenger, and also holds numerous additional Microsoft, Snowflake, and Databricks professional certifications in Big Data Engineering, Artificial Intelligence, Apache Spark and Data Platform Architecture.
- MSSQLTips Awards: Champion (100+ tips) – 2023 | Author of the Year – 2020-2021 | Rookie of the Year – 2019


