Problem
In our educational games, we want our architecture to either return random values or values based on a user’s previous input. When a user starts one or our applications, they make a choice about the challenge level and the more challenging of a level they select, the lower the probability that they’ll get a random value, but a value related to their input. The value related to their input is more challenging, while a random value may not be challenging. In some scenarios, we may want 60% of the challenge to be difficult, or 80% to be difficult, or sometimes 30%, depending on the challenge level they select. Using logic on the back-end from what the user selects when starting one of our applications, how can we structure either using random values or values based on user input to match different challenge levels?
Solution
In this tip, we’ll look at one way to structure different probabilities happening in situations where we may want outcomes every Nth percent of a time. The game scenario might be a difficulty level of 65% of the time we have a challenging question, while 35% of the time we get an easy question. We may use this technique for load testing environments – every Nth percent of the time, we load test with certain values that require further validation, while the remaining we don’t.
For the sake of examples, we’ll use randomly generated numbers, but for some scenarios (such as load testing), our “random” values may actually be within a range of options – such as testing ETL processes with unclean data mixed with clean data, where 80% of the time we’re testing unclean data. To help us conceptualize this, think of a chess move on a chess board of available options – a random move still must fit within some parameters of available options. In the examples below, our random numbers are only generated from either 0 to 9 or 1 to 10, so even with random numbers, we generally place limits.
The modulo operator functions like a division problem when the divisor or less than or equal to the dividend in that it returns the remainder of the operation. If we divide four by two, we know that we’ll get a return of two without any remainders (0) and if we increase the dividend to 5 and execute the same operation, we’ll get two with a remainder of 1. Since numbers may be divisible by other numbers, we may use the modulo operator in situations where we want the probability of an event to occur every % of time. Some simple examples of the modulo operator returned are below this.
---- Examples
SELECT (8 % 4) AS AnswerOne
, (8 % 2) AS AnswerTwo
, (8 % 8) AS AnswerThree
, (9 % 3) AS AnswerFour
, '' AS Blank
, (2 % 4) AS AnswerFive
, (3 % 8) AS AnswerSix
, (5 % 10) AS AnswerSeven
, (6 % 17) AS AnswerSeven
---- Remainders:
SELECT (8 % 3) AS RemAnswerOne
, (8 % 5) AS RemAnswerTwo
, (8 % 7) AS RemAnswerThree
, (9 % 2) AS RemAnswerFour


Notice the difference of the divisor being greater than the dividend versus the divisor being less than or equal to the dividend. In this tip, we’ll only be using situations where the quotient never has a remainder. The first, second, third and fourth examples show this result of a zero remainder, whereas the last four examples in the above sample code (RemAnswers) return remainders. We’ll also notice that the dividend eight is divisible without a remainder by both eight, four and two and the order would matter in an if statement.
When thinking about this operator, we may to structure our if statements with the highest possible divisor to the dividend first – depending on the probability level we want. For an example, 8 is divisible by both two, four and eight with no remainder, so if two is the first if statement our logic hits, it will return that level, skipping the possibility of four and eight. Two examples of this in practice with an if structure – the first example written incorrectly with the second example written correctly:
DECLARE @numOne INT = 8
IF ((@numOne % 2) = 0) BEGIN SELECT '2' AS ReturnSelection END
ELSE IF ((@numOne % 4) = 0) BEGIN SELECT '4' AS ReturnSelection END
ELSE IF ((@numOne % 8) = 0) BEGIN SELECT '8' AS ReturnSelection END
ELSE BEGIN PRINT 'None' END
IF ((@numOne % 8) = 0) BEGIN SELECT '8' AS ReturnSelection END
ELSE IF ((@numOne % 4) = 0) BEGIN SELECT '4' AS ReturnSelection END
ELSE IF ((@numOne % 2) = 0) BEGIN SELECT '2' AS ReturnSelection END
ELSE BEGIN PRINT 'None' END
DECLARE @numTwo INT = 3
IF ((@numTwo % 5) = 0) BEGIN SELECT '5' AS ReturnSelection END
ELSE IF ((@numTwo % 4) = 0) BEGIN SELECT '4' AS ReturnSelection END
ELSE IF ((@numTwo % 3) = 0) BEGIN SELECT '3' AS ReturnSelection END
ELSE IF ((@numTwo % 2) = 0) BEGIN SELECT '2' AS ReturnSelection END
ELSE BEGIN PRINT 'None' END
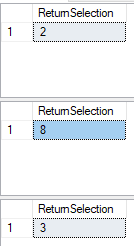
In the above examples, the number is set (8 and 3), but if the numbers were being randomly generated between a range, like 0 to 9, the probability of each block would be different. Just using 2 as an example, in the second block of code from above this, the probability of our code hitting 2 if a random number is generated between 0 and 9 is only 10% of the time based on the above order. The reason is that the number 0 will hit the 5 block, the numbers 9, 7, 5, 3, and 1 are all odd, the numbers 4 and 8 will hit the 4 block, and the number 6 will hit the 3 block. This means that the probability of us getting 2 is only 10% of the time.
This means that our modulo must be structured in a manner that represents what probability we’re seeking – in some cases, we may want lower divisors at the top, or higher divisors at the top. While in later examples, I use the RAND() operator as an example, we could use our own random number generator to create a numeric floor or ceiling for tailoring our modulos. In addition, to these considerations, we could also consider using an if number equals statement if we want our probabilities to be equal to each other, such as 20% of the time option A, B, C, D or E.
In the below two code samples, we run two demos (though the output will differ since these involve randomly generated numbers) involving different probability outcomes. In both examples, we use the RAND() operator to generate random numbers; in the second example, we set the minimum value at 1 for the random number by adding 1 (which increases the ceiling to 10), as we want that to be the lowest possibility. In the first block, we want the probability of level 1 being returned to be 70% of the time with levels 2, 3, and 4 having probabilities of 10% each. Since this block of code uses the possibility of 0 as a random number, we handle it independently. The first block doesn’t need the modulo operator, though we could use it if we wanted. In the second example, we use the modulo operator since we’re looking for a probability of 60% for levels 3 and 4, while we want a probability of 20% for level 5 and 20% for level 2.
-- Mode: 70% probability level 1
CREATE TABLE tbDemoSave(
Number INT,
Mode VARCHAR(10)
)
DECLARE @start INT = 1
WHILE @start < 10000
BEGIN
DECLARE @int INT = (RAND()*10)
IF (@int = 0) BEGIN INSERT INTO tbDemoSave VALUES (@int,'Level 1') END
ELSE IF (@int = 7) BEGIN INSERT INTO tbDemoSave VALUES (@int,'Level 4') END
ELSE IF (@int = 6) BEGIN INSERT INTO tbDemoSave VALUES (@int,'Level 3') END
ELSE IF (@int = 5) BEGIN INSERT INTO tbDemoSave VALUES (@int,'Level 2') END
ELSE BEGIN INSERT INTO tbDemoSave VALUES (@int,'Level 1') END
SET @start = @start + 1
END
SELECT
Number
, COUNT(Number) CountNumber
FROM tbDemoSave
GROUP BY Number
ORDER BY Number DESC
SELECT
Mode
, COUNT(Mode) CountMode
FROM tbDemoSave
GROUP BY Mode
ORDER BY Mode DESC
DROP TABLE tbDemoSave
---- Mode: 60% probability of either Level 3 or 4
CREATE TABLE tbDemoSave(
Number INT,
Mode VARCHAR(10)
)
DECLARE @start INT = 1
WHILE @start < 10000
BEGIN
DECLARE @int INT = (RAND()*10)
SET @int = @int + 1
IF ((@int % 5) = 0) BEGIN INSERT INTO tbDemoSave VALUES (@int,'Level 5') END
--- Handles 9, 6, and 3
ELSE IF ((@int % 3) = 0) BEGIN INSERT INTO tbDemoSave VALUES (@int,'Level 4') END
--- Handles 8, 4 and 2
ELSE IF ((@int % 2) = 0) BEGIN INSERT INTO tbDemoSave VALUES (@int,'Level 3') END
ELSE BEGIN INSERT INTO tbDemoSave VALUES (@int,'Level 2') END
SET @start = @start + 1
END
SELECT
Number
, COUNT(Number) CountNumber
FROM tbDemoSave
GROUP BY Number
ORDER BY Number DESC
SELECT
Mode
, COUNT(Mode) CountMode
FROM tbDemoSave
GROUP BY Mode
ORDER BY Mode DESC
DROP TABLE tbDemoSave


Depending on how many possibilities we can have along with what probability we want each time our code is executed, we will structure the modulo to cover the scenarios we require. The number of scenarios we need to generate (3? 10? 100?), also give us other ways to handle this. With lower possibilities, a simple if number equals statement may be more effective. We can combine simple if number equals statement with modulos, if the design calls for that scenario. For an example, if we had 10 different scenarios, we could simply run an if statement using 0 through 9 from a random number generator, with each if handling the scenario (if 0 was super easy and 9 was incredibly difficult). The modulo offers a route to structure probability on a more granular level with random number generation, depending on the needs.
Next Steps
- In most cases, if we have equal probabilities, such as 5 different scenarios, we can use a simple if number equals statement with a random number. Modulos assist when we want some probabilities to be higher than others without extra code or IF statements, such as N% of the time we want an event combination (like 60% of the time we want events A and B or events A, C and D).
- When solving for the problem of the probability of an event occurring, keep in mind that executing the modulo or if statement on the application level may be faster than allowing the back-end to do the work. This will depend on how the application and back-end are designed, as the back-end may be faster (and we may want to retain metadata on the feature for troubleshooting). While we see how we can do so in the above code and see the output by saving the data, we may find in testing that this isn’t the best place for executing this code.

Tim consults for FinTek Development and teaches the course Automating ETL on Udemy. He’s worked with technology since high school, helping his school win its first TCEA award and continues to work in automation, data architecture, back-end development, and smart contract architecture. Tim enjoys testing new technologies early in the diffusion of innovation curve and was an early adopter of NoSQL and smart contract development. He has a blog at http://www.fintekdev.com/ and helps contribute to local technical and financial events in Texas.


