Problem
I came across Graph processing in SQL Server which to me is an advanced version of using Common Table Expressions (CTE). SQL Server offers graph database capabilities to model many-to-many relationships. The graph relationships are integrated into T-SQL and receive the benefits of using SQL Server as the foundations database management system. In simple words, a graph database is the combination of NODES and EDGES. NODES represent an entity, EDGES represent a relationship between two nodes. Both nodes and edges may have properties associated with them. In this tip we are going to see a hierarchical structure of a family tree. The family tree will be based on the chart below. We will use SQL Server graph functionality to store and retrieve the data.
Solution
Here is a family tree that we will use for this tip.

William was born in 1850 and is the father of the family. The above chart is self-explanatory with names of William’s sons and the year of birth. Let’s process the above chart with Graph processing with SQL Server.
First, we are going to create the base data for William’s family. Then create a NODE table which will create nodes for each record. Create an EDGE table which will be used to match the NODEs of William’s family. The EDGE table will contain the actual output. We will use MATCH SQL command to virtually create the descendent tables as NODES and EDGES to fetch records per our needs.
We can use the below SQL commands to create the base data for William’s family. I created a fresh database too.
DROP DATABASE IF EXISTS FamilyDB;
GO
CREATE DATABASE FamilyDB;
GO
USE FamilyDB;
DROP TABLE IF EXISTS MyFamily;
CREATE TABLE MyFamily (
FmlyNum NUMERIC(8) not null,
Name VARCHAR(40) NOT NULL,
FmlyLink NUMERIC(8),
YOB INT,
INUM INT)
The above statements will create the base table “MyFamily”.
Let’s insert the records. The top most 1st level is William who was born in 1850 and hence William is kept in the top most node and the FmlyLink column is kept as NULL. Other records have a FmlyLink code for their father. Each record is linked between the FmlyNum and FmlyLink column.
INSERT INTO MyFamily values
(10000, 'William', NULL, 1850, 1),
(140000,'ALLEN', 10000, 1877, 1),
(60000, 'ROBINSON',140000, 1902, 1),
(70000, 'DAVIS', 140000, 1903, 1),
(80000, 'ADAM', 140000, 1904, 1),
(90000, 'SCOTT', 140000, 1905, 1),
(100000,'NELSON', 140000, 1906, 1),
(20000, 'GONZALEZ',10000, 1876, 1),
(30000, 'LEWIS', 20000, 1901, 1),
(31000, 'GRANT', 30000, 1926, 1),
(40000, 'WALKER', 10000, 1875, 2),
(120000,'YOUNG', 40000, 1900, 2),
(50000, 'HARRIS', 120000, 1925, 2),
(130000,'MITCHELL',120000, 1926, 2),
(110000,'CAMPBELL',130000, 1951, 2),
(150000,'BLACK', 130000, 1952, 2),
(160000,'WHITE', 150000, 1977, 2),
(170000,'JAMES', 160000, 2002, 2);
By running the above INSERT statements, the base data of William’s family is ready.
<span class="auto-style1">SELECT</span><span style="background-color: #ffffff"> * FROM MyFamily</span>

Node Table
DROP TABLE IF EXISTS MyFmlyNode;
CREATE TABLE MyFmlyNode(
FNO Int Identity(1,1),
FmlyNum NUMERIC(8) NOT NULL,
Name VARCHAR(40),
FmlyLink NUMERIC(8),
INUM INT
) AS NODE;
INSERT INTO MyFmlyNode(FmlyNum, NAME, FmlyLink, INUM)
SELECT FmlyNum, NAME, FmlyLink, INUM
FROM MyFamily
SELECT * FROM MyFmlyNode

We have created a NODE table and inserted the records with $NODE_ID as the key column.
Let’s see how {"type":"node","schema":"dbo","table":"MyFmlyNode","id":0} can be explained:
- The first column is the $node_id, this column is automatically created with the user defined columns that is created with the “AS NODE” keyword in the CREATE statement. In our case we have FNO, FmlyNum, Name and FmlyLink are user created columns. The NODE table is an entity in a graph schema. The values in the $node_id column are automatically generated and are a combination of object_id of that node table and an internally generated bigint value. We can also create a unique constraint or index on the $node_id column.
Edge Table
An EDGE table maintains the relationship between two NODES. In the below statement we will extract the matching $node_id’s from the NODE table and insert the value in the EDGE table, so that unique graph ids are created to maintain a relationship.
DROP TABLE IF EXISTS MyFmlyEdge;
CREATE TABLE MyFmlyEdge(
FmlyNum numeric(8)
) AS EDGE
INSERT INTO MyFmlyEdge
SELECT e.$node_id, m.$node_id ,e.fno
FROM dbo.MyFmlyNode e
INNER JOIN dbo.MyFmlyNode m ON e.FmlyNum = m.FmlyLink;
SELECT * FROM MyFmlyEdge
Let’s discuss the SELECT query part of the above INSERT statement. If you notice the INSERT statement into the Edge table, the two NODEs from the MyFmlyNode table are extracted based on the key column e.FmlyNum = m.FmlyLink. Now the query returns the matching $node_id data from Node tables. The extracted $node_id’s are inserted into the EDGE table. By INSERTING the matching NODE’s into the EDGE table, the link/connection is established between the Node and Edge tables.
Below is the output of the SELECT statement for entire William’s family.

I would like to also touch base on that the above join query can also be performed by using INSERT statements into the EDGE table by using a WHERE clause from the NODE table. Here are a few sample INSERT statements for understanding how this can be done.
INSERT INTO MyFmlyEdge
VALUES ((SELECT $node_id FROM MyFmlyNode WHERE FNO = 1),
(SELECT $node_id FROM MyFmlyNode WHERE FNO = 2),
111);
INSERT INTO MyFmlyEdge
VALUES ((SELECT $node_id FROM MyFmlyNode WHERE FNO = 2),
(SELECT $node_id FROM MyFmlyNode WHERE FNO = 3),
111);
INSERT INTO MyFmlyEdge
VALUES ((SELECT $node_id FROM MyFmlyNode WHERE FNO = 3),
(SELECT $node_id FROM MyFmlyNode WHERE FNO = 4),
111);
After running the above INSERT statements, the below query will show us the output from the EDGE table.
SELECT * FROM MyFmlyEdge

Now the EDGE table MyFmlyEdge is loaded with matched records for William’s Family.
I am going to cleanup these records we just inserted, so our results are correct for the family tree that we started with.
DELETE FROM MyFmlyEdge
WHERE FmlyNum = 111
Query data based on the chart
Based on William’s family chart above, let’s query the table and see how we can get data.
MATCH (SQL Graph)
A match query can be used to query any SQL Graph, we can query the NODE and EDGE using the MATCH statement. Nodes can be traversed an arbitrary number of times in the same query. In our example, we will use the MATCH statement to traverse between NODES and EDGES. MATCH can be used to traverse TOP DOWN or BOTTOM UP as per the requirements.
Second NODE query
Return data for William and his sons.
SELECT MyFmlyNode1.name, MyFmlyNode2.name
FROM MyFmlyNode MyFmlyNode1, MyFmlyEdge, MyFmlyNode MyFmlyNode2
WHERE MATCH(MyFmlyNode1-(MyFmlyEdge)->MyFmlyNode2)
AND MyFmlyNode1.name = 'William';
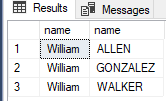
If you notice William is the first node and the second nodes are ALLEN, GONZALEZ and WALKER who are William’s sons. MATCH is used to traverse the NODES from top to bottom. To connect the two NODES we use this -> that shows we are going left to right.
Note that the relationship could go either way as shown below.
SELECT MyFmlyNode1.name, MyFmlyNode2.name
FROM MyFmlyNode MyFmlyNode1, MyFmlyEdge, MyFmlyNode MyFmlyNode2
WHERE MATCH(MyFmlyNode1-(MyFmlyEdge)->MyFmlyNode2)
AND MyFmlyNode1.name = 'William';
SELECT MyFmlyNode1.name, MyFmlyNode2.name
FROM MyFmlyNode MyFmlyNode1, MyFmlyEdge, MyFmlyNode MyFmlyNode2
WHERE MATCH(MyFmlyNode1<-(MyFmlyEdge)-MyFmlyNode2)
AND MyFmlyNode2.name = 'William';
The first query shows William first and then his sons and the second query shows the sons first and then William.

Third NODE Query
This will return data for William, his sons and any son that has sons.
SELECT MyFmlyNode1.name,MyFmlyNode2.name,MyFmlyNode3.name
FROM MyFmlyNode MyFmlyNode1, MyFmlyEdge, MyFmlyNode MyFmlyNode2, MyFmlyEdge MyFmlyEdge2, MyFmlyNode MyFmlyNode3
WHERE MATCH(MyFmlyNode1-(MyFmlyEdge)->MyFmlyNode2-(MyFmlyEdge2)->MyFmlyNode3)
AND MyFmlyNode1.name = 'William';
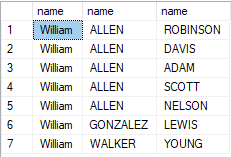
- If you notice William is the first node
- The second nodes are ALLEN, GONZALEZ and WALKER who are William’s sons.
- The third nodes are
- ROBINSON, DAVIS, ADAM, SCOTT, NELSON who are son’s of ALLEN.
- LEWIS is the son of GONZALEZ.
- YOUNG is the son of WALKER
Return Data for All Lineages
To return data for all connections from the oldest to the most recent generation we can use a query like below.
with Fmly
AS
(
SELECT r1.NAME AS TopNode,r2.NAME AS ChildNode,CAST(CONCAT(r1.NAME,'-<',r2.NAME) AS varchar(250)) AS Output,r1.$node_id AS parentid, r2.$node_id as bottomnode,1 as Tree
FROM MyFmlyNode r1
JOIN MyFmlyEdge e ON e.$from_id = r1.$node_id
JOIN MyFmlyNode r2 ON r2.$node_id = e.$to_id AND r1.NAME IN( 'WILLIAM')
UNION ALL
SELECT c.ChildNode,r.NAME,CAST(CONCAT(c.Output,'-<',r.NAME) AS varchar(250)),c.bottomnode,r.$node_id,Tree + 1
FROM Fmly c
JOIN MyFmlyEdge e ON e.$from_id = c.bottomnode
JOIN MyFmlyNode r ON r.$node_id = e.$to_id
)
SELECT output FROM Fmly
This shows all of the connections from left to right.

Conclusion
We have seen how the MATCH clause can be used to fetch data from EDGE tables. I hope the tip will be useful for the SQL Server developer community.
Next Steps
- Check out this tip on the SQL Server MERGE command

Jayendra is a Project Leader for a IT Service company. Jayendra has over 15 years of IT project experience in software development, software support, production support and product support. He has specialized in Microsoft SQL Server, Microsoft Access, the Microsoft Business Intelligence suite earning a Microsoft certification. Jayendra has expertise in IT Project Management as well. Jayendra’s personal interests are in the stock market.