Problem
We’d like to keep history in our data warehouse for several dimensions. We use SQL Server Integration Services (SSIS) to implement the ETL (Extract Transform and Load). We tried the built-in Slowly Changing Dimension wizard, but the performance seems poor. How can we implement the desired functionality with regular SSIS components?
Solution
Introduction to Slowly Changing Dimensions
A slowly changing dimension (SCD) keeps track of the history of its individual members. There are several methods proposed by Ralph Kimball in his book The Datawarehouse Toolkit:
- Type 1 – Overwrite the fields when the value changes. No history is kept.
- Type 2 – Create a new line with the new values for the fields. Extra columns indicate when in time a row was valid.
- Type 3 – Keep the old value of a column in a separate column.
- There are more types of SCDs, but they are mostly a hybrid combination of the above.
In this tip, we’ll focus on the type 2 situation. Let’s illustrate with an example. We have a simple table storing customer data.
The SK_Customer column is a column with an identity property which will generate a new value for every row. We’d like to keep history for the Location attribute. When the location changes from Antwerp to Brussels, we don’t update the row, but we insert a new record:

Using the ValidFrom and ValidTo fields, we indicate when a record was valid in time. A new surrogate key is generated, but the business key – CustomerName – remains the same. When a fact table is loaded, a lookup will be done on the customer table. Depending on the timestamp of the fact record, one of the two rows will be returned. For example:

All facts are for the same customer. When you would ask the total sales amount for CustomerA, the result is 31. The total sales per location is 12.75 for Antwerp and 18.25 for Brussels, even though the data is for the same customer. Using SCD Type 2, we can analyze our data with historical attributes.
Implementation Methods
There are several methods for loading a Slowly Changing Dimension of type 2 in a data warehouse. You could opt for a pure T-SQL approach, either with multiple T-SQL statements or by using the MERGE statement. The latter is explained in the tip Using the SQL Server MERGE Statement to Process Type 2 Slowly Changing Dimensions.
With SSIS, you can use the built-in Slowly Changing Dimension wizard, which can handle multiple scenarios. This wizard is described in the tips Loading Historical Data into a SQL Server Data Warehouse and Handle Slowly Changing Dimensions in SQL Server Integration Services. The downside of this wizard is performance: it uses the OLE DB Command for every update, which can result in poor performance for larger data sets. If you make changes to the data flow to solve these issues, you can’t run the wizard again as you would lose all changes.
The last option – aside from using 3rd party components – is building the SCD Type 2 logic yourself in the data flow, which we’ll describe in the next section.
Implementation in SSIS
The solution proposed in this tip works for any version of SSIS. We’ll reprise the example of the customer dimension, but an extra field has been added: the email attribute. We don’t keep history of the email addresses, so any new value will overwrite all other values.
First, we read the data from a source, most likely a staging environment. When using a relational source, you can use the OLE DB Source component with a SQL query to read the data. Only select columns you actually need for your dimension. The ValidFrom field is calculated here as well. Since you typically load data from the previous day, ValidFrom is set to the date of yesterday. If you don’t have a relational source, you can add this column using a Derived Column transformation.
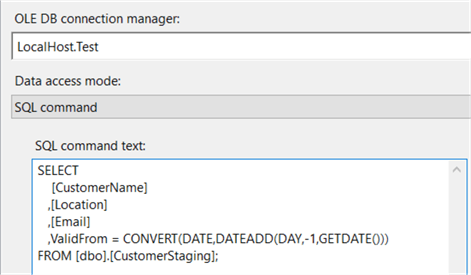
In the next step, we’re doing a lookup against the dimension. Here we’ll verify if the incoming rows are either an insert or an update. If no match is found, the row is a new dimension member and it needs to be inserted. If a match is found, the dimension member already exists and we’ll need to check for SCD Type 2 changes. Unless you have a very large dimension, you can use the full cache:
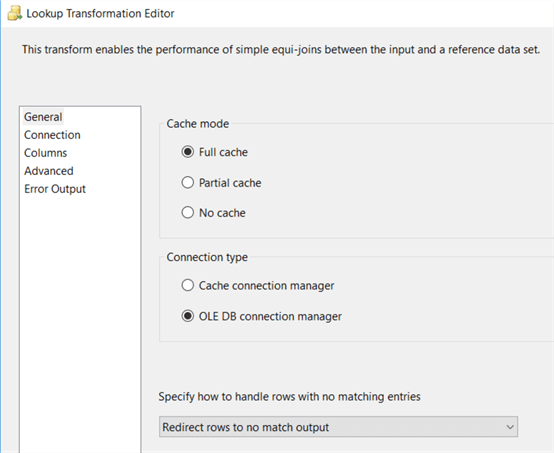
Configure the lookup transformation to send non-matching rows to the no match output. In SSIS 2005 this option doesn’t exist yet, so you can either use the error output, or set the transformation to ignore failures and split out inserts and updates using a conditional split.
In the Connection pane, the following SQL query fetches the surrogate key, the business key (CustomerName) and the SCD Type 2 columns. For each member, only the most recent row is retrieved, by filtering on the ValidTo field.
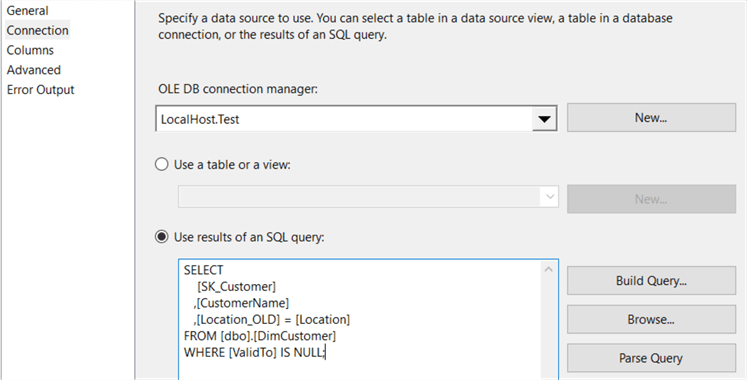
The Location field is renamed to Location_OLD for clarity. In the Columns pane, match on the business key and select all other columns.
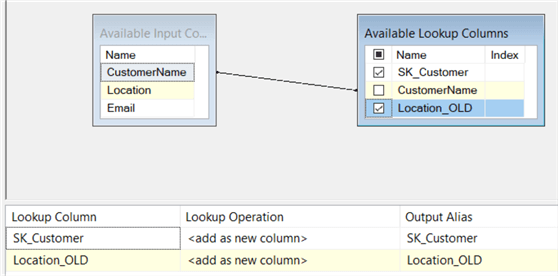
Now we can add an OLE DB Destination on the canvas. This destination will write all new rows to the dimension. Connect the Lookup No Match Output of the lookup transformation to the destination.

On the mapping pane, map the columns of the data flow with the columns of the dimension table.

The SK_Customer column is left unmapped, as it’s an IDENTITY column and its values are generated by the database engine. The ValidTo column is also left blank. New rows have no value for this column.
In part 2 of this tip we’ll continue our configuration of the data flow, where we’ll check if a row is a type 2 update or not.
Next Steps
- If you want to know more about implementing slowly changing dimensions in SSIS, you can check out the following tips:
- You can find more SSIS development tips in this overview.

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025



datasets are not available ?
I am very happy to share this article on my LinkedIn
Hi Dom,
it seems indeed the create table statement is not included for the customer dimension.
It’s a simple table though: one int column with an identity, two string columns and two date columns.
Regards,
Koen
Hi, really good article. I’m in the process of building a similar process, I’m slightly confused by the customer dimension. No reference to how this is created or where it is coming from?