Problem
SQL Server columnstore indexes are helpful when it comes to retrieving large volumes of data. However, there are instances where columns are added to the table after the columnstore index was created. This means the new columns are missing in the columnstore index. Also, there can be cases where new tables are added and a columnstore index was not created. In this tip we will look at how we can identify these cases and create scripts to create the index.
Solution
A columnstore index is an index that was designed mainly for improving the query performance for workloads with very large amounts of data (e.g. reading data warehouse fact tables and processing OLAP cubes). This type of index stores the index data in a column-based format rather than row based as is the case with traditional indexes.
Columnstore indexes provide a very high level of compression, up to 10x, due to the fact that the data across columns is usually very similar and will compress quite well. The second reason to use columnstore indexes is to improve performance of queries.
Columnstore indexes were introduced with SQL Server 2012 as non-clustered columnstore indexes. Also, in the SQL Server 2012 version, data cannot be modified after the columnstore index was created. With later versions of SQL Server we now have more options when using columnstore indexes.
Typically, all the columns are added to the columnstore index. However, there can be cases where columns are added to the table after the columnstore index is created. Also, there are cases where some tables are added later and a columnstore does not exist.
In this tip, we will show how to add columns to a non-clustered columnstore index.
Missing Columns in a SQL Server Columnstore Index
Let’s look at this SQL Server table as an example.

In the above table, only five columns are included in the columnstore index and there are many other columns that could be included in the non-clustered columnstore index.
The following query will generate scripts to create indexes. Depending on the filters you use at the end of the query, it will generate the create index statements for those tables.
SELECT DISTINCT 'CREATE NONCLUSTERED COLUMNSTORE INDEX [' + i.NAME + '] ON dbo.' + tbl.NAME + ' (' + IndexColumns.IndexColumnList + ') WITH (DROP_EXISTING = ON) '
FROM sys.tables AS tbl
INNER JOIN sys.indexes AS i
ON (
i.index_id > 0
AND i.is_hypothetical = 0
)
AND (i.object_id = tbl.object_id)
INNER JOIN sys.index_columns AS ic
ON (
ic.column_id > 0
AND (
ic.key_ordinal > 0
OR ic.partition_ordinal = 0
OR ic.is_included_column != 0
)
)
AND (
ic.index_id = CAST(i.index_id AS INT)
AND ic.object_id = i.object_id
)
INNER JOIN (
SELECT object_id,
(
STUFF((
SELECT ',' + NAME
FROM sys.columns
WHERE object_id = C.object_id
FOR XML PATH(''),
TYPE
).value('.', 'NVARCHAR(MAX)'), 1, 1, '')
) AS IndexColumnList
FROM sys.columns AS C
GROUP BY C.object_id
) AS IndexColumns
ON IndexColumns.object_id = ic.object_id
WHERE
tbl.NAME LIKE 'fact%'
AND tbl.NAME NOT LIKE '%OLD%'
AND tbl.NAME NOT LIKE '%BACK%'
AND i.type_desc LIKE '%NONCLUSTERED COLUMNSTORE%'
In the above query, tables that start with “fact” with non-clustered columnstore indexes are selected. The tables are identified by the table prefix “fact”. You might have different ways of identifying the tables. Also, in any environment you may have tables with OLD, BACK, etc. in the name, so those are filtered out as well.
The WITH (DROP_EXISTING = ON) option is added to the index, so the index does not need to be dropped separately.
When I ran the above script, it generated the following create index script:
CREATE NONCLUSTERED COLUMNSTORE INDEX [NonClusteredColumnStoreIndex-20181003-234642] ON dbo.FactCallCenter (
FactCallCenterID,
DateKey,
WageType,
Shift,
LevelOneOperators,
LevelTwoOperators,
TotalOperators,
Calls,
AutomaticResponses,
Orders,
IssuesRaised,
AverageTimePerIssue,
ServiceGrade,
DATE
)
WITH (DROP_EXISTING = ON)
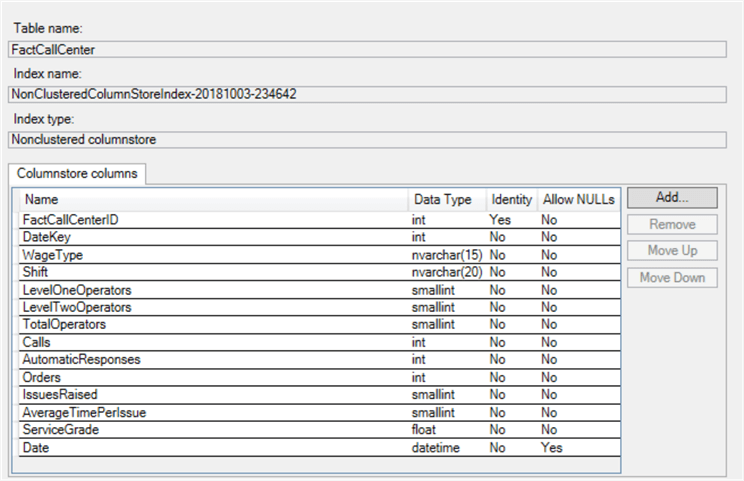
After executing the create index script, the remaining columns were added to the non-clustered columnstore index. Unlike in a standard row-based index, the column order does not matter for columnstore indexes.
Next Steps
- Test this out on your test servers to see if this generates the needed scripts for your environment.
- Learn more about SQL Server Columnstore Indexes

Dinesh Asanka holds a Bachelor of Science in Electrical Engineering, an MBA in Information Technology, a Master of Science in Artificial Intelligence, and an MPhil in Data Warehousing from the University of Moratuwa. With more than 30 years of industry experience, he has successfully bridged the gap between theoretical knowledge and practical application in the fields of data management and analytics. Currently serving as a Senior Lecturer at the University of Kelaniya, he teaches subjects including Data Science, Big Data Analytics, and Database Administration. His research interests focus on Educational Analytics, Health Analytics, Data Science, and Artificial Intelligence-driven solutions for decision-making and learning enhancement. In addition to his academic and research contributions, Dinesh is also an active columnist and presenter who regularly contributes to professional forums, conferences, workshops, and public discussions related to technology, analytics, and digital transformation.
- MSSQLTips Awards: Rookie of the Year Contender – 2018



Thank you for share this article But if index has filter and index type is nonclustered columstore index this query could not help .would you know where this field is store ?