By: Aaron Bertrand | Comments (1) | Related: > SQL Server 2019
Problem
In
a recent tip, I provided some details about a whole slew of new features that
were announced for the first CTP of SQL Server 2019. There's definitely more
to come, but today I wanted to dig a little deeper into a specific feature, the
new aggregate function APPROX_COUNT_DISTINCT, and
show how I tested it out in my home lab. In
this video, Joe Sack explains what differences you should expect to see in the
execution plan, but I was curious what I would observe at scale.
Solution
My goal was to test the impact on both query duration and memory footprint for
queries using the new function, which extrapolates statistics to come up with rough
estimates, compared to the more accurate COUNT(DISTINCT())
approach, which forces a read of every single value. I wanted to see how each approach
would fare using both
batch mode over row store (another new enhancement) and without.
I also wanted to compare against integers and also against strings of varying lengths
and various fullness (since things like memory grants for variable-width columns
are based on the assumption they will average being half "full"). And
finally, I wanted to judge the accuracy of the approximation with various ratios
of distinct values. So, for a table with 10,000,000 rows, I wanted to have columns
with 100 distinct values, 1,000 distinct values, and so on, up to the subset of
columns that would support all 10,000,000 values being unique. Building a table
to support this was a job in and of itself.
Here is the script I came up with:
DROP TABLE IF EXISTS dbo.FactTable;
GO SET NOCOUNT ON; DECLARE @x8 char(8) = REPLICATE('@',8),
@x16 char(16) = REPLICATE('!',16),
@x32 char(32) = REPLICATE('$',32),
@x64 char(64) = REPLICATE('&',64),
@x128 char(128) = REPLICATE('^',128),
@x256 char(256) = REPLICATE('#',256); ;WITH src(n) AS
(
SELECT 1 UNION ALL SELECT n + 1 FROM src WHERE n < 100
)
SELECT -- integers
rn, i1, i2, i3, i4, i5, -- varchar minimally populated
vm0 = CONVERT(varchar(8), rn),
vm1 = CONVERT(varchar(8), i1),
vm2 = CONVERT(varchar(8), i2),
vm3 = CONVERT(varchar(8), i3),
vm4 = CONVERT(varchar(8), i4),
vm5 = CONVERT(varchar(8), i5), -- varchar half populated
vh1 = CONVERT(varchar(16), RIGHT(@x8 + RTRIM(i1),8)),
vh2 = CONVERT(varchar(32), RIGHT(@x16 + RTRIM(i2),16)),
vh3 = CONVERT(varchar(64), RIGHT(@x32 + RTRIM(i3),32)),
vh4 = CONVERT(varchar(128), RIGHT(@x64 + RTRIM(i4),64)),
vh5 = CONVERT(varchar(256), RIGHT(@x128 + RTRIM(i5),128)), -- varchar fully populated
vf0 = CONVERT(varchar(8), RIGHT(@x8 + RTRIM(rn),8)),
vf1 = CONVERT(varchar(16), RIGHT(@x16 + RTRIM(i1),16)),
vf2 = CONVERT(varchar(32), RIGHT(@x32 + RTRIM(i2),32)),
vf3 = CONVERT(varchar(64), RIGHT(@x64 + RTRIM(i3),64)),
vf4 = CONVERT(varchar(128), RIGHT(@x128 + RTRIM(i4),128)),
vf5 = CONVERT(varchar(256), RIGHT(@x256 + RTRIM(i5),256)) INTO dbo.FactTable
FROM
(
SELECT
rn,
i1 = rn / 10,
i2 = rn / 100,
i3 = rn / 1000,
i4 = rn / 10000,
i5 = n
FROM
(
SELECT s.n,rn = ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) – 1
FROM src AS s
CROSS JOIN src AS s2
CROSS JOIN src AS s3
CROSS JOIN (SELECT TOP (10) n FROM src) AS s4
) AS x
) AS y;
GO CREATE UNIQUE CLUSTERED INDEX cix ON dbo.FactTable(rn);
Have patience, because this took over two minutes on my machine, but it produced a table with 10,000,000 rows that we could now measure queries against. A few sample rows (well, what I could fit on screen, anyway):
SELECT TOP (10) * FROM dbo.FactTable ORDER BY NEWID();
I developed a quick script that loops through each of the columns in the table, and inserts counts and timings into a temp table:
DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS;
GO DECLARE @rn int;
SELECT @rn = rn FROM dbo.FactTable;
GO DROP TABLE IF EXISTS #s;
GO CREATE TABLE #s(col sysname, cd_rows int, approx_rows int);
GO SET NOCOUNT ON;
GO DELETE #s; DECLARE @sql nvarchar(max) = N'', @base nvarchar(max) = N' EXEC sys.sp_executesql N''INSERT #s(col, cd_rows, approx_rows) SELECT ''''$n'''',
COUNT(DISTINCT($n)), NULL FROM dbo.FactTable
OPTION (USE HINT(''''DISALLOW_BATCH_MODE''''));''; EXEC sys.sp_executesql N''INSERT #s(col, cd_rows, approx_rows) SELECT ''''$n'''',
COUNT(DISTINCT($n)), NULL FROM dbo.FactTable;''; EXEC sys.sp_executesql N''INSERT #s(col, cd_rows, approx_rows) SELECT ''''$n'''', NULL,
APPROX_COUNT_DISTINCT($n) FROM dbo.FactTable
OPTION (USE HINT(''''DISALLOW_BATCH_MODE''''));''; EXEC sys.sp_executesql N''INSERT #s(col, cd_rows, approx_rows) SELECT ''''$n'''', NULL,
APPROX_COUNT_DISTINCT($n) FROM dbo.FactTable;'';'; SELECT @sql += REPLACE(@base, N'$n', name)
FROM sys.columns
WHERE object_id = OBJECT_ID(N'dbo.FactTable')
AND name <> N'rn'; EXEC sys.sp_executesql @sql;
GO 5
Again, have patience here, since this takes some longer than the initial population (about 5 minutes per batch).
Once we have the most recent measures in the temp table, we can look at those as well as timings captured for us automatically in the DMV sys.dm_exec_query_stats:
;WITH x AS
(
SELECT
s.col,
[# of unique values] = MAX(s.cd_rows),
[new guess] = MAX(s.approx_rows),
[# off] = MAX(s.approx_rows)-MAX(s.cd_rows),
[% off] = CASE WHEN MAX(s.approx_rows) < MAX(s.cd_rows) THEN -1 ELSE 1 END
* CONVERT(decimal(6,3), MAX(s.approx_rows*1.0)/MAX(s.cd_rows*1.0)),
avg_time_actual = CONVERT(decimal(20,2), MAX(stat.avg_time_actual)),
avg_time_guess = CONVERT(decimal(20,2), MAX(stat.avg_time_guess)),
avg_time_actual_batch = CONVERT(decimal(20,2), MAX(stat.avg_time_actual_batch)),
avg_time_guess_batch = CONVERT(decimal(20,2), MAX(stat.avg_time_guess_batch)),
avg_memory_actual = CONVERT(decimal(20,1), MAX(stat.avg_memory_actual)),
avg_memory_guess = CONVERT(decimal(20,1), MAX(stat.avg_memory_guess)),
avg_memory_actual_batch = CONVERT(decimal(20,1), MAX(stat.avg_memory_actual_batch)),
avg_memory_guess_batch = CONVERT(decimal(20,1), MAX(stat.avg_memory_guess_batch))
FROM #s AS s
LEFT OUTER JOIN
(
SELECT text,
avg_time_actual = CASE t WHEN 'actual' THEN avg_time END,
avg_memory_actual = CASE t WHEN 'actual' THEN avg_memory END,
avg_time_guess = CASE t WHEN 'guess' THEN avg_time END,
avg_memory_guess = CASE t WHEN 'guess' THEN avg_memory END,
avg_time_actual_batch = CASE t WHEN 'actual_batch' THEN avg_time END,
avg_memory_actual_batch = CASE t WHEN 'actual_batch' THEN avg_memory END,
avg_time_guess_batch = CASE t WHEN 'guess_batch' THEN avg_time END,
avg_memory_guess_batch = CASE t WHEN 'guess_batch' THEN avg_memory END
FROM
(
SELECT t.text,
t = CASE WHEN t.text LIKE N'%COUNT(DISTINCT(%DISALLOW%' THEN 'actual'
WHEN t.text LIKE N'%COUNT(DISTINCT(%' THEN 'actual_batch'
WHEN t.text LIKE N'%APPROX_COUNT%dbo.FactTable%DISALLOW%' THEN 'guess'
WHEN t.text LIKE N'%APPROX_COUNT%dbo.FactTable%' THEN 'guess_batch'
END,
avg_time = s.total_elapsed_time*1.0/s.execution_count,
avg_memory = s.total_grant_kb*1.0/s.execution_count
FROM sys.dm_exec_query_stats AS s
CROSS APPLY sys.dm_exec_sql_text(s.plan_handle) AS t
WHERE t.text LIKE N'%COUNT(DISTINCT(%dbo.FactTable%'
OR t.text LIKE N'%APPROX_COUNT%dbo.FactTable%'
) AS y
) AS stat
ON stat.text LIKE N'%(' + s.col + N')%'
GROUP BY col
)
SELECT * INTO #t FROM x;
I dumped this output into a temporary table and from there generated this data in a spreadsheet format that was easier to look at and analyze. Note: the time is output in microseconds and the memory is output in KB. Also, I mentioned about running this in both batch and non-batch mode to see the differences.
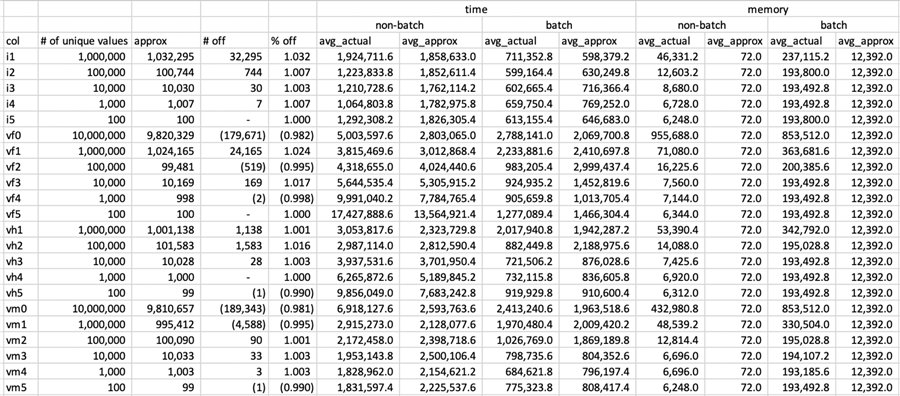
The three things I want to point out in the data:
- The accuracy of the approximate counts. In all cases, the results from the approximate count calculations fell within roughly 1% of the actuals. While this data set is relatively uniform, this is quite impressive, given that Microsoft asserts accuracy within 2% most of the time.
- Duration. The amount of time spent on the approximate count calculations was not always better than the actuals – in fact in a few cases, the time spent was more than double.
- Memory Footprint. In non-batch mode, the memory required by the approximate count calculations was almost nothing, compared to a substantial amount in some cases (almost 1 GB for the fully-populated varchar with 10,000,000 distinct values). For batch mode, memory usage was up across the board, but the relative delta was much more favorable toward the approximate calculations.
Summary
The big payoff from this feature is the substantially reduced memory footprint.
In the testing I've performed, I didn't really get any of these queries
to run any faster. But any system would have been able to handle the same query
from a much larger number of people without any noticeable degradation. Often query
improvements are deemed "better" only when they run faster, but sometimes
it can be equally important when they allow for more scalability. In this regard,
APPROX_COUNT_DISTINCT does not disappoint.
Next Steps
Read on for related tips and other resources:
- Count of rows with the SQL Server COUNT Function
- What's New in the First Public CTP of SQL Server 2019
- Demonstrating APPROX_COUNT_DISTINCT
- Approximate Count Distinct enters Public Preview in Azure SQL Database
- SQL Server COUNT() Function Performance Comparison
- Problem using DISTINCT in case insensitive SQL Server databases






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
