Problem
SQL Server has long supported Unicode characters in the form of nchar, nvarchar, and ntext data types, which have been restricted to UTF-16. You could get UTF-8 data into nchar and nvarchar columns, but this was often tedious, even after UTF-8 support through BCP and BULK INSERT was added in SQL Server 2014 SP2. And the end result was to pay for Unicode storage and memory requirements, because you still had to store all of the data as Unicode, even when some or all of it was ASCII.
In SQL Server 2019, there are new UTF-8 collations, that allow you to save storage space, while still enjoying the benefits of compatibility and storing your UTF-8 data natively. Similar (but not identical) to Unicode compression, you only pay for the additional storage space for the characters that actually require that space. But what is the actual storage impact, and how does this affect memory grants and query performance?
Solution
There are numerous implications of various collations, codepages, and UTF formats. I feel like an expert could write a 20-part article series and still not be done. In fact Solomon Rutzky has written about these topics quite a bit– most recently an article about UTF-8 support in SQL Server 2019 – which suggests that you probably should not use this feature (yet), and that your focus for using UTF-8 collation for your columns should be primarily about compatibility, not about storage space or performance.
Because I know people will still use it in spite of Solomon’s advice, I want to focus solely on a specific UTF-8 collation, and how the space and memory requirements differ compared to UTF-16 data stored in traditional Unicode columns. I’ll compare with and without compression, and with various percentages of a column value (and the percentage of rows in the table) with non-ASCII data.
First, let’s take a look at a table that has columns with three different collations, and see what it looks like when we insert data into them. I took a screenshot of this query, because I know that some of these Unicode characters won’t translate well by the time they reach your device:

There are three columns, the first uses the standard Latin1_General collation, the second has Latin1_General with supplementary characters (SC), and then a third column using a new Latin1_General UTF-8 collation. I inserted a Greek character, an Asian character, and an emoji (the Canadian flag, of course!), both by themselves and then with some additional ASCII characters. Here are the results of LEN() and DATALENGTH() for each of the values:
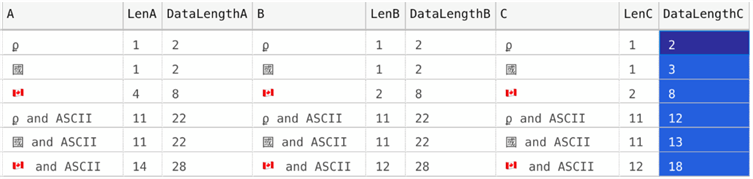
Clearly, you can see that the lengths are largely the same, with the exception of how the emoji requires four bytes in the first collation. However, the actual storage is almost always the same or lower when using the UTF-8 collation (again, with one exception, this time the Asian character required one extra byte). I’ll save you the suspense: with both row and page compression, and a similar #temp table, all of the results were the same.
Also, a comment in the code sample above indicates that you still need an N prefix on string literals, even though the destination type is varchar. The reason is that SQL Server will try to interpret the value of the string first, and if the N is not there, part of the Unicode data gets lost.
Try this:
DECLARE @t TABLE (t varchar(10) COLLATE Latin1_General_100_CI_AI_SC_UTF8);
INSERT @t(t) VALUES('<span style="font-family: 'MS Gothic';">h</span>'),(N'<span style="font-family: 'MS Gothic';">h</span>');
SELECT t FROM @t;
</span>Results:
t
----
?
h
In playing with this I also discovered another phenomenon, probably completely unrelated to collation, but interesting nonetheless. When using varbinary representations of Unicode strings (like the pile of poo emoji, 0x3DD8A9DC), they can be interpreted differently depending on what else is in the statement. In this example, I’m executing three different batches: (1) inserting the varbinary value directly; (2) inserting the value directly and, in a separate statement, inserting the value after converting to nvarchar; and, (3) inserting the value and the converted value in the same statement:
DECLARE @t TABLE (t varchar(10) COLLATE Latin1_General_100_CI_AI_SC_UTF8);
INSERT @t(t) VALUES(0x3DD8A9DC);
SELECT t FROM @t;
GO -- 1
DECLARE @t TABLE (t varchar(10) COLLATE Latin1_General_100_CI_AI_SC_UTF8);
INSERT @t(t) VALUES(0x3DD8A9DC);
INSERT @t(t) VALUES(CONVERT(nvarchar(10),0x3DD8A9DC));
SELECT t FROM @t;
GO -- 2
DECLARE @t TABLE (t varchar(10) COLLATE Latin1_General_100_CI_AI_SC_UTF8);
INSERT @t(t) VALUES(0x3DD8A9DC),(CONVERT(nvarchar(10),0x3DD8A9DC));
SELECT t FROM @t;
GO -- 3
The results had me puzzled:
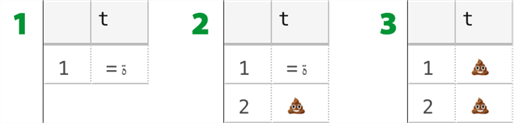
In the case where the inserts were performed with different statements, both were interpreted correctly. But when using VALUES() to insert two rows together, both somehow converted to nvarchar. A behavior involving VALUES() and probably nothing to do with collation, but I’ll have to look at that in a future tip. In the meantime, watch out for this if you are ever changing scripts from one form to the other.
Back to the original investigation; what if we try this out at a larger scale? I wrote a script that generates CREATE TABLE statements for a bunch of tables with various settings for collation, compression, and how much non-ASCII data would actually be stored. Specifically, this creates 81 tables, with combinations of:
- Compression (row, page, and none);
- Collation (Latin1_General_100_CI_AI, Latin1_General_100_CI_AI_SC, and Latin1_General_100_CI_AI_SC_UTF8</strong>);
- Percentage of rows containing UTF-8 data (0%, 50%, 100%); and,
- Number of characters in each row that is UTF-8 data (0 characters, 25 characters, and 50 characters):
CREATE TABLE #cmp(cmp varchar(4));
INSERT #cmp VALUES('ROW'),('PAGE'),('NONE');
CREATE TABLE #coll(coll varchar(8));
INSERT #coll VALUES(''),('_SC'),('_SC_UTF8');
CREATE TABLE #row(rowconf varchar(9));
INSERT #row VALUES('0 % UTF8'),('50 % UTF8'),('100% UTF8');
CREATE TABLE #char(charconf varchar(7));
INSERT #char VALUES('0 UTF8'),('25 UTF8'),('50 UTF8');
SELECT N'CREATE TABLE dbo.' + QUOTENAME(N'UTF8Test' + coll.coll + N'_'
+ cmp.cmp + N'_' + rowconf + N'_' + charconf) + N'
(
id int IDENTITY(1,1) NOT NULL,
the_column ' + CASE coll.coll WHEN '_SC_UTF8' THEN N'' ELSE N'n' END + N'varchar(512)' END
+ N' COLLATE Latin1_General_100_CI_AI' + coll.coll + N',
CONSTRAINT ' + QUOTENAME(N'pk_UTF8Test_' + coll.coll + N'_' + cmp.cmp
+ N'_' + rowconf + N'_' + charconf) + N' PRIMARY KEY CLUSTERED(id)
WITH (DATA_COMPRESSION = ' + cmp.cmp + N')
This script produces 81 rows of output, with table definitions like the following (they are not pretty scripts, of course):
CREATE TABLE dbo.[UTF8Test_ROW_0 % UTF8_0 UTF8]
(
id int IDENTITY(1,1) NOT NULL,
the_column nvarchar(200) COLLATE Latin1_General_100_CI_AI,
CONSTRAINT [pk_UTF8Test__ROW_0 % UTF8_0 UTF8] PRIMARY KEY CLUSTERED(id)
WITH (DATA_COMPRESSION = ROW)
_SC_ROW_0 % UTF8_0 UTF8]
(
id int IDENTITY(1,1) NOT NULL,
the_column nvarchar(200) COLLATE Latin1_General_100_CI_AI<strong>_SC</strong>,
CONSTRAINT [pk_UTF8Test__SC_ROW_0 % UTF8_0 UTF8] PRIMARY KEY CLUSTERED(id)
WITH (DATA_COMPRESSION = ROW)
_SC_UTF8_ROW_0 % UTF8_0 UTF8]
(
id int IDENTITY(1,1) NOT NULL,
the_column varchar(200) COLLATE Latin1_General_100_CI_AI<strong>_SC_UTF8</strong>,
CONSTRAINT [pk_UTF8Test__SC_UTF8_ROW_0 % UTF8_0 UTF8] PRIMARY KEY CLUSTERED(id)
WITH (DATA_COMPRESSION = ROW)
… 78 more tables …
Copy, paste, execute, and now you have 81 tables that you can generate INSERT statements to populate in a similar way. There is more logic involved here, and the script is even uglier as a result – we want to insert 10,000 rows into each table, but those rows are a mix of values partially or wholly populated (or not) with Unicode data. I have a Canada flag in here and added a comment to the location in case it doesn’t display properly in your browser:
DECLARE @sql nvarchar(max) = N'SET NOCOUNT ON;';
SELECT @sql += N'
WITH n AS (SELECT n = 1 UNION ALL SELECT n+1 FROM n WHERE n < 10000)
INSERT dbo.' + QUOTENAME(N'UTF8Test' + coll.coll + N'_' + cmp.cmp
+ N'_' + rowconf + N'_' + charconf) + N'(the_column) SELECT b FROM (SELECT
b = REPLICATE(N''<span style="font-family: 'Apple Color Emoji';">🇨🇦</span>'',' + LEFT(charconf.charconf,2) + N')
<strong><span style="color: #70ad47;">-----------------^ Canada flag is here</span></strong>
+ REPLICATE(N''.'',' + RTRIM(50-LEFT(charconf.charconf,2)) + N')) AS a
CROSS APPLY (SELECT TOP (' + CONVERT(varchar(11),CONVERT(int,10000
* LEFT(rowconf.rowconf,3)/100.0)) + N') n FROM n) AS b OPTION (MAXRECURSION 10000);
WITH n AS (SELECT n = 1 UNION ALL SELECT n+1 FROM n WHERE n < 10000)
INSERT dbo.' + QUOTENAME(N'UTF8Test' + coll.coll + N'_' + cmp.cmp
+ N'_' + rowconf + N'_' + charconf) + N'(the_column) SELECT b FROM (SELECT
b = REPLICATE(N''.'',50)) AS a
CROSS APPLY (SELECT TOP (' + CONVERT(varchar(11),10000-CONVERT(int,10000
* LEFT(rowconf.rowconf,3)/100.0)) + N') n FROM n) AS b OPTION (MAXRECURSION 10000);'
FROM #cmp AS cmp, #coll AS coll, #row AS rowconf, #char AS charconf;
PRINT @sql;
--EXEC sys.sp_executesql @sql;
The print won’t show you all of the script (unless you have SSMS 18.2 or use other measures like in this tip), instead it will be pairs of insert statements; the first in each pair representing the rows that contain UTF-8 data, and the second representing the rows that don’t:
WITH n AS (SELECT n = 1 UNION ALL SELECT n+1 FROM n WHERE n < 10000)
INSERT dbo.[UTF8Test_ROW_0 % UTF8_0 UTF8](the_column) SELECT b FROM (SELECT
b = REPLICATE(N'<span style="font-family: 'Apple Color Emoji';">🇨🇦</span>',0 )
<strong><span style="color: #70ad47;">----------------^ Canada flag is here</span></strong>
+ REPLICATE(N'.',50)) AS a
CROSS APPLY (SELECT TOP <strong>(0)</strong> n FROM n) AS b OPTION (MAXRECURSION 10000);
WITH n AS (SELECT n = 1 UNION ALL SELECT n+1 FROM n WHERE n < 10000)
INSERT dbo.[UTF8Test_ROW_0 % UTF8_0 UTF8](the_column) SELECT b FROM (SELECT
b = REPLICATE(N'.',50)) AS a
CROSS APPLY (SELECT TOP <strong>(10000)</strong> n FROM n) AS b OPTION (MAXRECURSION 10000);
In the first example, we want 0% of the rows to contain UTF-8 data, and 0 of the characters inside any row to contain UTF-8 data. This is why we insert no rows containing the Canada flags, and 10,000 rows of 50 periods. (I acknowledge that 50 periods will compress unfairly well, but more representative data is harder to automate, and GUIDs would be too far the other way.)
If we take an arbitrary example from later in the script, we can see how the rows are distributed differently – half the rows contain UTF-8 data, and those that do contain 25 Unicode characters and 25 periods:
WITH n AS (SELECT n = 1 UNION ALL SELECT n+1 FROM n WHERE n < 10000)
INSERT dbo.[UTF8Test_ROW_50 % UTF8_25 UTF8](the_column) SELECT b FROM (SELECT
b = REPLICATE(N'<span style="font-family: 'Apple Color Emoji';">🇨🇦</span>',25)
<strong><span style="color: #70ad47;"> ----------------^ Canada flag is here</span></strong>
+ REPLICATE(N'.',25)) AS a
CROSS APPLY (SELECT TOP <strong>(5000)</strong> n FROM n) AS b OPTION (MAXRECURSION 10000);
WITH n AS (SELECT n = 1 UNION ALL SELECT n+1 FROM n WHERE n < 10000)
INSERT dbo.[UTF8Test_ROW_50 % UTF8_25 UTF8](the_column) SELECT b FROM (SELECT
b = REPLICATE(N'.',50)) AS a
CROSS APPLY (SELECT TOP <strong>(5000)</strong> n FROM n) AS b OPTION (MAXRECURSION 10000);
If you are confident I’m not going to blow up your disk, change this:
PRINT @sql;
--EXEC sys.sp_executesql @sql;
To this:
--PRINT @sql;
EXEC sys.sp_executesql @sql;
Then execute it. On my system this took anywhere from 20 – 40 seconds, and the data and log files were 400 MB and 140 MB respectively (starting from a fairly standard AdventureWorks sample database).
Now, we are ready to spot check and analyze! First, let’s make sure all the tables have the right number of rows:
SELECT t.name, p.rows
FROM sys.tables AS t
INNER JOIN sys.partitions AS p
ON t.object_id = p.object_id
WHERE t.name LIKE N'UTF8%';
-- 81 rows, all with 10,000 rows
Then we can spot check any table where we expect there to be some variance:
SELECT TOP (2) * FROM dbo.[UTF8Test_ROW_50 % UTF8_50 UTF8] ORDER BY id;
SELECT TOP (2) * FROM dbo.[UTF8Test_ROW_50 % UTF8_50 UTF8] ORDER BY id DESC;
SELECT TOP (2) * FROM dbo.[UTF8Test_SC_UTF8_ROW_50 % UTF8_25 UTF8] ORDER BY id;
SELECT TOP (2) * FROM dbo.[UTF8Test_SC_UTF8_ROW_50 % UTF8_25 UTF8] ORDER BY id DESC;
Sure enough, we see what we expect to see (and this isn’t satisfying anything about collation, it is just proving that my script did what I thought it would do):

Now, what about storage space? I like to look at the page allocations DMV, sys.dm_db_database_page_allocations, especially for relative comparisons. I pulled this simple query from my templates:
SELECT t.name,PageCount = COUNT(p.allocated_page_page_id)
FROM sys.tables AS t CROSS APPLY
sys.dm_db_database_page_allocations(DB_ID(), t.object_id, 1, NULL, 'LIMITED') AS p
WHERE t.name LIKE N'UTF8%'
GROUP BY t.name
ORDER BY PageCount DESC;
And here were the results:
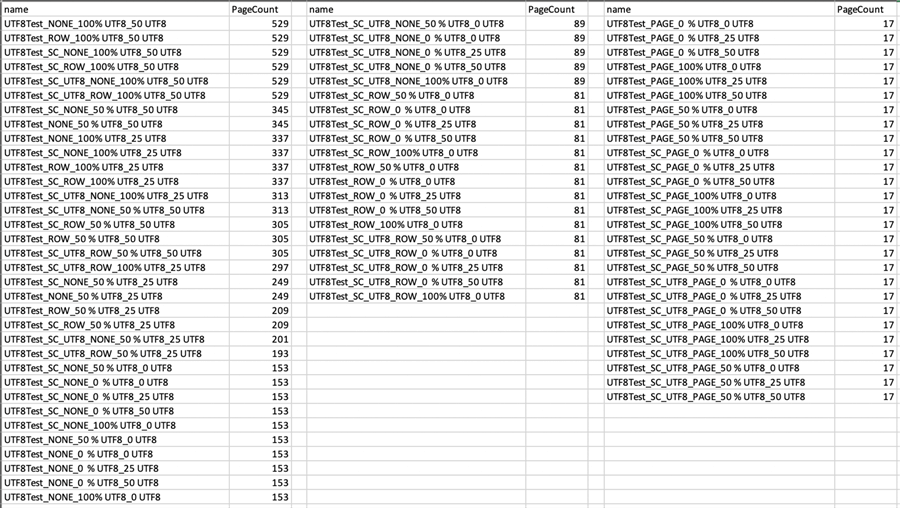
I moved the output into Excel and separated it into three columns, almost arbitrarily. The column on the left is every table that required more than 100 pages, and on the right is every table that used page compression. The middle column is everything with 81 or 89 pages. Now, I might have stacked the deck in favor of compression, since all the values on any given page are likely to be the same. Which means that the page counts involved with compression are likely much lower than they would be with more real-world data. But what this does show is that, given the same data, page compression is an absolute equalizer. The rest is a mixed bag, with no real observable trends, except for illustrating that when more of the data is Unicode, the page counts are higher, regardless of collation (and, for the most part, whether compression is row or none).
How about performance? The thing I’m typically concerned about in cases like this – in addition to the number of pages that would have to be read in a scan, for example – is the memory grant that would be allocated, particularly for queries with sorts. Duration is always something to be interested in, too, but I always feel like free memory is more scarce than patience. I wrote a script to generate a query to run against each table, 10 times:
DECLARE @sql nvarchar(max) = N'DBCC FREEPROCCACHE;
GO
SELECT @sql += N'
SELECT TOP 1 c FROM (SELECT TOP 9999 the_column FROM dbo.'
+ QUOTENAME(name) + ' ORDER BY 1) x(c);
GO 10'
FROM x;
PRINT @sql;
In this case I used the PRINT output (copy and paste into a new window) instead of sys.sp_executesql because the latter can’t accept commands like GO 10. After running the queries, I went to sys.dm_exec_query_stats to check on memory grants and query duration. I could have analyzed the 82 queries independently, but I decided to simply group them by collation and compression. The query I ran:
WITH x AS
(
SELECT coll = CASE WHEN t.name LIKE '%SC_UTF8%' THEN 'UTF8'
WHEN t.name LIKE '%_SC%' THEN 'SC' ELSE '' END,
comp = CASE WHEN t.name LIKE N'%_PAGE_%' THEN 'Page'
WHEN t.name LIKE N'%_ROW_%' THEN 'Row' ELSE 'None' END,
max_used_grant_kb,max_ideal_grant_kb,max_elapsed_time
FROM sys.dm_exec_query_stats AS s
CROSS APPLY sys.dm_exec_sql_text(s.plan_handle) AS st
INNER JOIN sys.tables AS t
ON st.[text] LIKE N'SELECT TOP%' + t.name + N'%'
WHERE t.name LIKE N'UTF8%'
)
SELECT coll, comp,
max_used_grant = AVG(max_used_grant_kb*1.0),
ideal_grant = AVG(max_ideal_grant_kb*1.0),
max_time = AVG(max_elapsed_time*1.0)
FROM x GROUP BY coll,comp
ORDER BY coll, comp;
This resulted in two interesting charts. The first one shows that the memory grants for UTF-8 data were slightly smaller:

The second chart, unfortunately, shows that the average duration of the UTF-8 queries was 50% higher or more:

Summary
The new UTF-8 collations can provide benefits in storage space, but if page compression is used, the benefit is no better than older collations. And while memory grants might be slightly lower, potentially allowing for more concurrency, the runtime of those queries was significantly longer. After this small bit of investigation, I wouldn’t say that there is an obvious situation where I would rush to switch to UTF-8 collations.
Now, again, some of this is surely influenced to a degree by my simplistic and well-compressed sample data, so I’m not going to pretend that this has any universal relevance to all data and workloads. It does, however, show some ways you could perform testing with your own data and in your specific environment.
In another experiment, I plan to try out clustered columnstore indexes, to see how traditional nvarchar and UTF-16 there might compare against the new UTF-8 collations. After writing the current article, I suspect that writing the next one will lead to me becoming a bigger fan of columnstore, though not any fonder of UTF-8 collations.
Next Steps
Read on for related tips and other resources:
- Introducing UTF-8 support in SQL Server 2019 preview
- Import UTF-8 Unicode Special Characters with SQL Server Integration Services
- SQL Server differences of char, nchar, varchar and nvarchar data types
- Native UTF-8 Support in SQL Server 2019: Savior or False Prophet?
- Unicode Support in SQL Server

Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He also blogs at sqlblog.org.
- MSSQLTips Awards: Author of the Year – 2016, 2023 | Leadership (200+ tips) – 2022
Super-useful, thanks!
One small nit to pick, is that UTF-8 *is* also Unicode. Although Microsoft originally added to the confusion by having Notepad (IIRC) give the option of saving text files in ANSI or Unicode or UTF-8, presenting the choice as Unicode vs. UTF-8 is misleading. MS seems to have cleaned up their act in Notepad, and a better way of contrasting this choice would be UTF-16 vs. UTF-8 (where UTF is short for *Unicode* Transformation Format in both cases).
I’m in no way minimising how useful your article is. Thank you for taking the time in creating this article!