Problem
In a previous tip we looked at some tips to help improve T-SQL performance and in this tip we continue with some additional tips.
Solution
In this tip we will show some concepts and tips to help you write better T-SQL code. By having the basics, you can learn about any specific topic in more detail later. In Part 1, we learned how the SQL engine works and some database design tips to improve application performance. In this part we will see some common code examples that can be improved by following some simple guidelines.
This tip is not intended to be a T-SQL tutorial, but I would like to share with you some tips that are not so obvious when you first start writing T-SQL code.
Avoid Using SELECT *
When sending data to client applications, avoid sending all information available in the object (or objects), there are various reasons for this. By explicitly defining columns, resource consumption is reduced (also less information from disk must be retrieved). Application security is improved by only sending the required information. A common wait type ASYNC_NETWORK_IO can be also reduced.
Filter data at the database tier (WHERE Clause)
Additionally, to the previous tip, you can reduce data sent to the client even more and improve application performance by filtering required data on the database side. I have seen some cases where developers load all the data from the table to the client application and then perform filtering, this also presents security issues, because all data is exposed and accessible for a malicious user.
Sort data on the presentation tier (ORDER BY Clause)
Whenever possible, send the data to the application unsorted, let the front-end layer take care of the sorting, but why?
Sorting on the database layer is a resource intensive operation, and can negatively impact performance on your database instance, and since most modern client machines have enough memory let applications take care of the sorting on the front-end.

COUNT(*) includes NULL
When you use COUNT(*), NULLs are part of the count. If you use COUNT(<field>), NULLs are excluded. So based on this, when NULLs exist in your data COUNT(field) <= COUNT(*).
Let’s look at a simple example against the AdventureWorks database:
SELECT
COUNT(*) as SalesPersons,
COUNT(TerritoryID) as PersonsWithTerritory
FROM [Sales].[SalesPerson];
Since TerritoryID contains NULLs, you can see after executing the query the counts are different:

Aggregation functions over non-existent data
Always validate outputs when you use aggregation functions on your queries, since if no data exists, NULL is returned.
Take this query as an example (executed against the AdventureWorks database):
SELECT
SUM(TotalDue) as TotalOrdersDue,
AVG(TotalDue) as AverageOrdersDue,
MIN(TotalDue) as MinOrdersDue,
MAX(TotalDue) as MaxOrdersDue
FROM [Sales].[SalesOrderHeader]
WHERE DueDate > GETUTCDATE();
Since there are NULL values, the aggregation functions return NULL:

Be aware of deprecated features
If you are using a new version of SQL Server, be aware of deprecated features, especially if you are planning to migrate an old application.
SQL Server provides a DMO to check for deprecated features on the version you are running, just run the following T-SQL:
SELECT *
FROM sys.dm_os_performance_counters
WHERE object_name = 'SQLServer:Deprecated Features';
You will obtain an output like this:
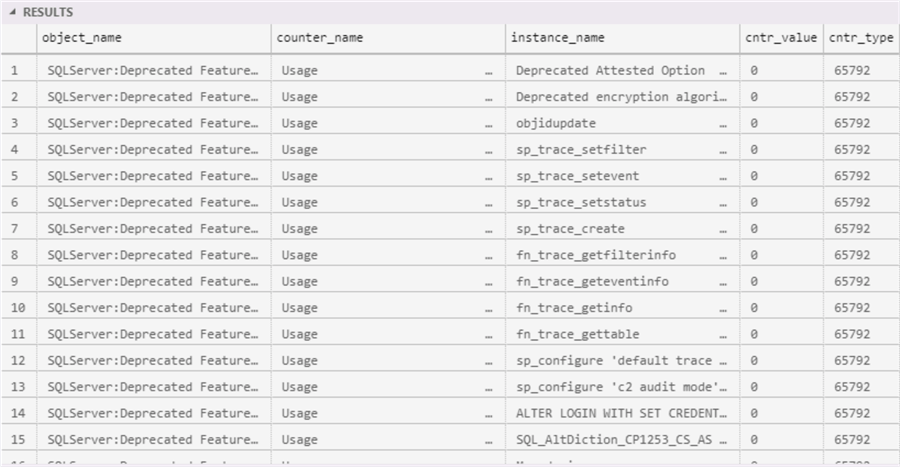
Database collation
This consideration is important for you if you develop T-SQL code to be deployed in different client environments, where you don’t have control of the configuration of the client instance. When working with multiple databases, you can have some case sensitive runtime errors if you are not careful when naming your objects.
Let’s see an example. I have created an example database called TestCollation1 using the master collation (Case Insensitive):
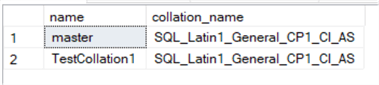
If we execute the following query against a test table, everything is ok:
USE TestCollation1;
GO
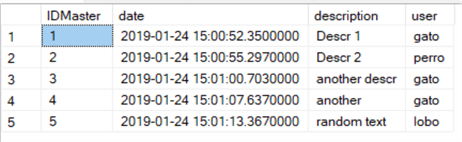
SELECT md.*
FROM MasterData MD;
These are the results (everything is ok so far):
If we now change the collation of the database to Case Sensitive and execute the same query:
USE [master];
GO
ALTER DATABASE [TestCollation1] COLLATE SQL_Latin1_General_CP1250_CS_AS;
GO
USE TestCollation1;
GO
SELECT md.*
FROM MasterData MD;
We will obtain the following error:

This is because the MD value we use as the table alias and md to retrieve the fields are now different.
To fix this issue, you must use the same case on both places:
SELECT MD.*
FROM MasterData MD;
With this simple change, now you obtain the correct data:

This simple consideration can be the difference between having a runtime error for an implementation on a new client (and losing their trust) and having T-SQL code that can be executed anywhere.
Index basics: Table Scan vs Index Scan vs Index Seek
Indexes are special structures associated with tables or views that store information in a B-tree for quick data retrieval. They improve query performance, but require additional disk storage and IO, so limit your index creation.
A good index is when values have a high selectivity (or cardinality)
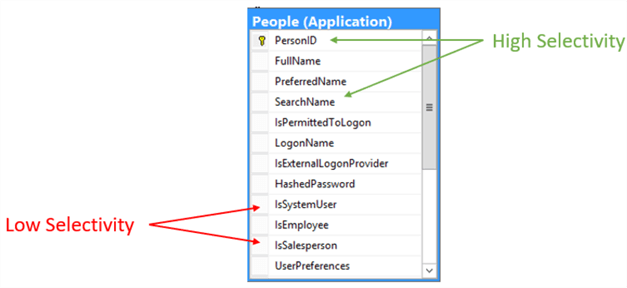
There are a lot of index types, but the most common are these:
- Clustered index: Stores the information ordered by a specific column (normally the primary key), there can be just one per object. They have faster performance on numeric and sequential values.
- Non-clustered index: A separate structure that stores a pointer to a row location on the original object, by a specific column. Performance depends on size, number of columns and datatypes.
- Heap: Table without a clustered index, only allows full table scans to locate records.
Based on the indexes created on the object, we have 3 basic forms to retrieve data:
- Table Scan: All the rows must be scanned to retrieve the required information.
- Index Scan: An index is used to retrieve the data, but it must be scanned to retrieve the required information.
- Index Seek: An index is used to retrieve the data, and the required data can be located by just navigating the B-tree, normally this method provides the fastest data access.
We will see an example retrieving the same information by using the three methods, we will continue use the AdventureWorks test database and a table Sales.SalesOrderDetail:
Table Scan
We will do a SELECT INTO to create a copy of the table without indexes.
SELECT *
INTO Sales.SalesOrderDetail2
FROM Sales.SalesOrderDetail;
Now if we search an order and then check the execution plan, we will see a table scan is performed:
SELECT CarrierTrackingNumber
FROM Sales.SalesOrderDetail2
WHERE CarrierTrackingNumber = N'6431-4D57-83';

If we look at the operator details from the plan, we can see that 121,317 rows where read to obtain only 2 rows.
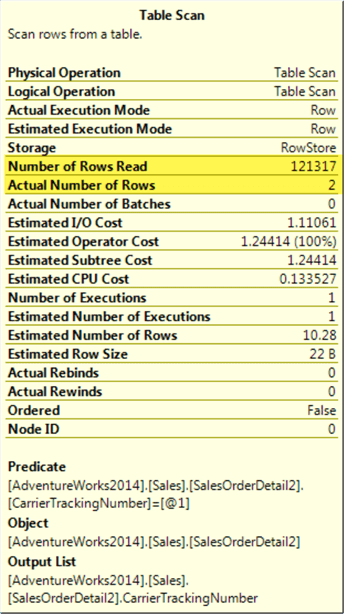
Index Scan
We will return to the original table, that contains a clustered index and perform the same SELECT. Now an index scan is performed over the clustered index:
SELECT CarrierTrackingNumber
FROM Sales.SalesOrderDetail
WHERE CarrierTrackingNumber = N'6431-4D57-83';
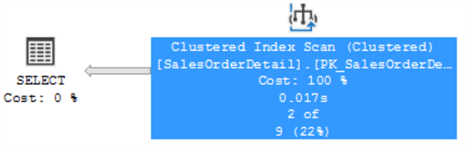
If we check the operator details, again 121,317 were scanned and 2 rows were obtained, but this time using the index. This time the query performs slightly better.
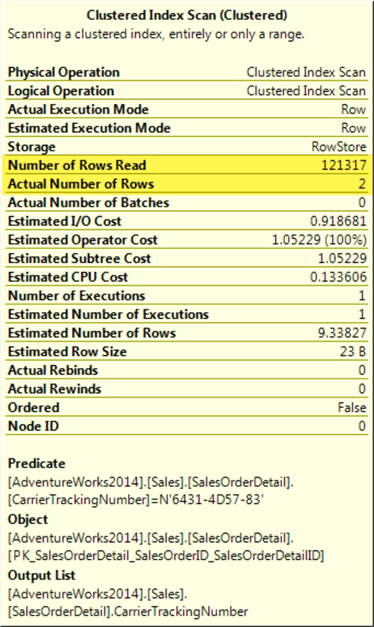
Index Seek
This time we will create a non-clustered index to support our query and perform the SELECT again. Now an index seek is performed:
CREATE NONCLUSTERED INDEX IX_CarrierTrackingNumber
ON Sales.SalesOrderDetail (CarrierTrackingNumber);
SELECT CarrierTrackingNumber
FROM Sales.SalesOrderDetail
WHERE CarrierTrackingNumber = N'6431-4D57-83';
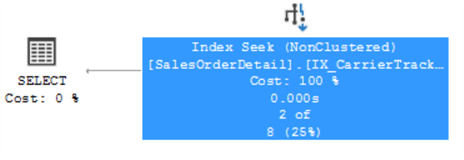
Checking the operator details, we can see the query performance is a lot better, also just 2 rows are directly located and retrieved:

Now that we have created an index to support our query, what happens if we search for non-existent data? Will an index seek be performed again? Let’s take a look at this example, we search for a string that does not exists in our data:
SELECT CarrierTrackingNumber
FROM Sales.SalesOrderDetail
WHERE CarrierTrackingNumber = N'I DO NOT EXISTS';
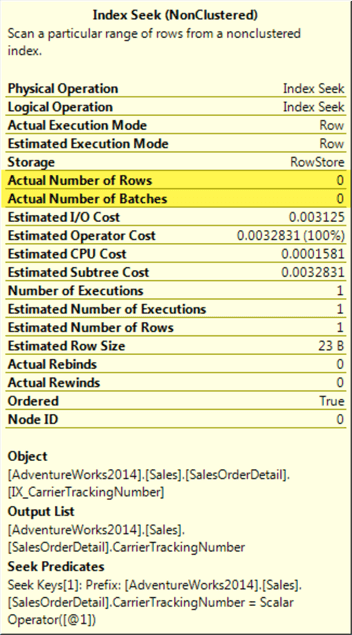
Checking the execution plan we can see that see that an index seek is used:
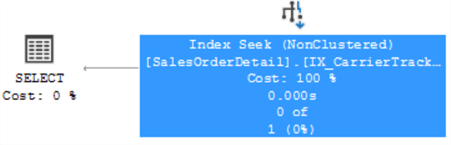
In the operator details, also we can see that no rows were read.
Summary
So far in this series we have discussed database design and T-SQL considerations to keep in mind when creating code, but what if you have to fix existing code or troubleshoot databases handed over to you? In Part 3 we will see some T-SQL cases to fix the most common performance issues.
Next Steps
- Check out Part 1 where we discuss some database design considerations.
- In Part 3 we will cover more code examples and tips to improve performance.
- Check out additional performance tuning tips.

Eduardo Pivaral is an MCSA, SQL Server Database Administrator and Developer with over 15 years of experience working in large environments.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2020 | Author of the Year Contender – 2019 | Rookie of the Year – 2018


