Problem
In previous articles, Part 1 and Part 2, we looked at various ways to help improve performance when working with T-SQL. In this tip, we look at some other concepts that could be helpful to make sure your T-SQL performs well.
Solution
In this tip, we will show you some basic concepts and tips to help you write better code, and having the basics, you can learn about any specific topic in more detail later.
In Part 1, we learned how the SQL engine works and some database design tips to improve application performance. In Part 2, we looked at some common code examples that can be improved by following some simple guidelines. In this tip, we will see some basic T-SQL performance issues and how to solve them.
Basic T-SQL Performance Tips
This is not an extensive list of all the performance issues you can encounter and how to fix them, but this is a base you can use for the most common code performance issues and ways to solve them.
Make Sure SQL Server Queries Use the Indexes
To make sure queries run fast, we need to take advantage of indexes and make sure the indexes are SARGable which stands for: search + argument + able, for query processing. It indicates when a search argument (in the WHERE clause) is able to properly use an index, but what is a proper used index? This is when the SQL engine can rely on the argument to be consistent to perform an index seek when a proper value is passed to the query. This is usually achieved when you do not perform calculations on columns to be search but instead just use the parameter value.
Let’s see an example using the AdventureWorks test database, with the [Person].[Address] table.
First, we create a non-clustered index to support the query:
CREATE NONCLUSTERED INDEX [IX_Address_City] ON [Person].[Address] ([City])
INCLUDE ( [AddressLine1], [AddressLine2] );
Then we perform a simple search of addresses for all cities starting with M:
SELECT AddressID, AddressLine1, AddressLine2, City
FROM Person.Address
WHERE left(City, 1) = 'M';
We can see in the execution plan below that even when we have an index over city, an index scan is performed. In this case, this is because we used a function over the City column in the search predicate which requires all rows to be evaluated.
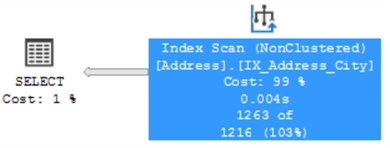

We can rewrite the same query to be SARGable, by performing the transformation of the value on the parameter as follows:
SELECT AddressID, AddressLine1, AddressLine2, City
FROM Person.Address
WHERE City LIKE 'M%';
Now an index seek is performed and we will get the same results.
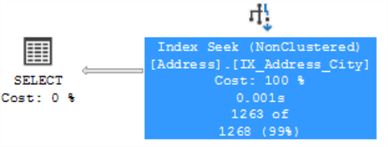

Just keep in mind that for this to work, in the case of substrings, the LIKE operator can only use index seeks when the you don’t put a wildcard at the beginning of the string like the example below. In the case you want to search for any city with the letter M in it, this is not SARGable anymore, since there is no guaranteed order for where to find the data:
SELECT AddressID, AddressLine1, AddressLine2, City
FROM Person.Address
WHERE City LIKE '%M%';
You can see that without a guarantee order for the index to use, an index scan is performed:

SQL Server Covering Indexes
As we have seen in the previous tip, non-clustered indexes store a pointer to the original data (either the heap or the clustered index – note a table without a clustered index is referred to as a heap). In a normal scenario, indexed data is provided by the non-clustered index, and then all the remaining data is pulled from the heap or the cluster, this implies extra IO reads to retrieve all the required data (we can see this with a key lookup operator in the execution plan, we will see an example below).
A covering index is when the index is capable of providing all the data by itself, without accessing the pointer to the heap or the cluster. This can be achieved by using indexed columns or using included columns. Included columns are not indexed, they just are part of the index data. Also keep in mind that included columns require extra storage, so use them with caution.
Let’s see how this works. Again, we will use AdventureWorks test database and we will search for a product in the Production.Product table:
First, we create our base non-clustered index to support the query over the ProductNumber field:
-- Index creation for product number
CREATE UNIQUE NONCLUSTERED INDEX [AK_Product_ProductNumber]
ON [Production].[Product] ([ProductNumber]);
Then, we perform a simple SELECT, just returning the ProductNumber field. Since just the indexed field is returned, we can see that an index seek is performed:
-- First query execution, an index seek is performed
SELECT ProductNumber
FROM Production.Product
WHERE ProductNumber = N'BC-R205';

If we add another column to the query, for example, Name, now a key lookup will be performed. This is because the index is used to locate the record, and then the extra information must be retrieved from the heap or cluster.
-- For query execution, an index seek is performed with a key lookup
SELECT ProductNumber, Name
FROM Production.Product
WHERE ProductNumber = N'BC-R205';

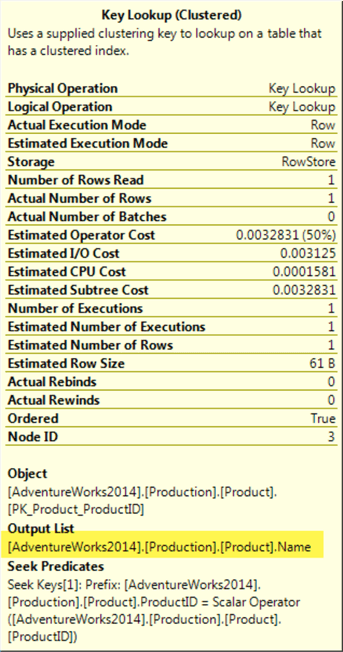
To fix this, we have to add an included column to the index. As we stated earlier included columns are not indexed, they just help the index to "cover" all the required information:
-- we drop the index and recreate with "Name" field as an included column
DROP INDEX [AK_Product_ProductNumber]
ON [Production].[Product];
CREATE UNIQUE NONCLUSTERED INDEX [AK_Product_ProductNumber]
ON [Production].[Product] ([ProductNumber])
INCLUDE ([Name]);
Now we execute the query again, we can see that an index seek is performed this time:
-- For query execution, an index seek is performed with a key lookup
SELECT ProductNumber, Name
FROM Production.Product
WHERE ProductNumber = N'BC-R205';


SQL Server Implicit Conversions
Continuing with the topic of the search arguments, we must be also careful using the correct data types when filtering data. By choosing the wrong datatype, even when they are properly coded, performance can be degraded by not properly using the indexes.
We will see an example of this and how bad the performance is affected. We will use the AdventureWorks test database and a table called [Sales].[SalesOrderDetail]:
First, we create a non-clustered index to support our example:
CREATE NONCLUSTERED INDEX [IX_UnitPrice] ON [Sales].[SalesOrderDetail] (UnitPrice)
INCLUDE (SalesOrderDetailID);
Then, we perform a simple SELECT, using a parameter of Money datatype (the same type as the column we are searching):
DECLARE @demo_var MONEY
-- Assigning value to the parameter
SET @demo_var = 3578.27;
-- filtering with the variable we declared earlier
SELECT SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE UnitPrice = @demo_var;
Checking the execution plan, we can see an index seek is performed (everything is OK so far):


What if we change the data type of the parameter to SQL_variant and let everything else remain the same? Let’s check it:
DECLARE @demo_var2 SQL_VARIANT
-- Assigning value to the parameter
SET @demo_var2 = 3578.27;
-- filtering with the variable we declared earlier
SELECT SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE UnitPrice = @demo_var2;
If we check the execution plan now, even when the index is properly created, an index scan and a filter is performed:


After seeing the warning on the SELECT operator, we can see that this plan was chosen because the SQL engine cannot "trust" the provided parameter will be a valid one, so a correct cardinality estimate cannot be provided, instead the information must be filtered row by row.
SQL Server Parameter Sniffing
This is an extensive topic with a lot of opinions, the focus of this tip is just to explain what it is and some of the tools you have available to "fix" it, or at least minimize the impact. This issue occurs when you have a high-density variation on any given column (density is the number of duplicated values a column can have, is used to calculate selectivity and enhance cardinality estimates).
For example, if you have a table with millions of rows and one of the columns store colors for your products, assuming most of the records are black, white and gray (let us assume 98% of the records), when you query this information, an execution plan is built based on the number of records to be returned, but, let’s say the 2% of the remaining records are the other colors (yellow, red, etc..), if we use the same plan as before, it will be optimized for a lot of records and not for just a few rows. This is basically what parameter sniffing means, so let us show you an example.
I have created a table with more than 5 million rows, as follows:
SELECT count(id) as records, [color]
FROM [dbo].[TestColors]
GROUP BY [color]

You can see that colors Black, Gray and White have more than 1 million records, and Red just has one record.
Next, if we filter the table by the White color, we will have a plan like this:
SELECT count(id) as records
FROM [dbo].[TestColors]
WHERE color = N'White'

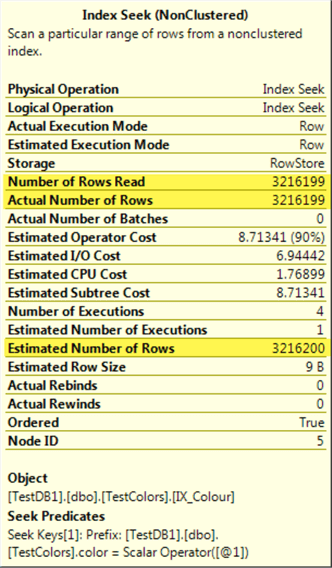
We can see that the estimated number of rows (3,216,200) which is very close to the actual number of rows (3,216,199).
SQL Server will store this plan in memory and try to use it again the next time the query is run.
Let’s see what happens if we run the same query for the Red color. Let’s take a look:
SELECT count(id) as records
FROM [dbo].[TestColors]
WHERE color = N'Red'
We obtain the same plan (optimized for millions of rows):


You can see that the plan estimated the same number of rows as before, but we are only obtaining one row.
Depending on your specific queries, this might be a performance issue, so you have to analyze if this is a problem to be fixed or you can just ignore it.
There are various ways to fix it.
SQL Server OPTION RECOMPILE
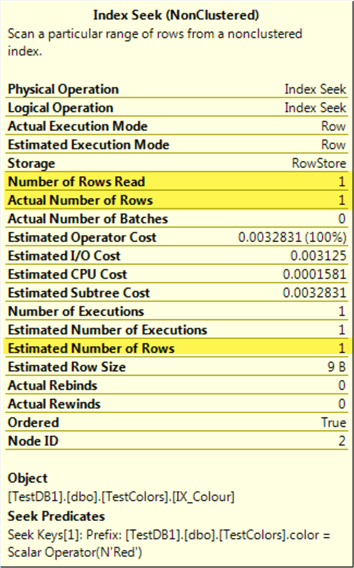
The first one is using the RECOMPILE hint on the query. The drawback of this method is that the query will be compiled every time you execute it, which you should avoid it if you are running the query constantly.
SELECT count(id) as records
FROM [dbo].[TestColors]
WHERE color = N'Red'
OPTION(RECOMPILE);
We can see that the plan has changed, and is optimized for just one row this time:

SQL Server OPTION OPTIMIZE FOR UNKNOWN
Another fix is to use the OPTIMIZE FOR UNKNOWN hint. This hint adds an extra step to the compiler to check the statistical data instead of the cached ones.
The drawback of this method is that the plan might not be optimal for all cases, so maybe you just want to use this hint in very specific queries.
SELECT count(id) as records
FROM [dbo].[TestColors]
WHERE color = N'White'
OPTION(OPTIMIZE FOR UNKNOWN);
For each different parameter, we will obtain each plan we saw before.
Database Scoped Configuration PARAMETER_SNIFFING
If you have SQL Server 2016 or higher, you can use a database scoped configuration PARAMETER_SNIFFING, the default value for this option is ON.
ALTER DATABASE SCOPED CONFIGURATION SET PARAMETER_SNIFFING = OFF; -- Default is ON
GO
This option disables parameter sniffing for the given database, so the estimated rows will be an average for any column we filter, as we can see if we execute the same queries again:
SELECT count(id) as records
FROM [dbo].[TestColors]
WHERE color = N'Red'

SELECT count(id) as records
FROM [dbo].[TestColors]
WHERE color = N'White'
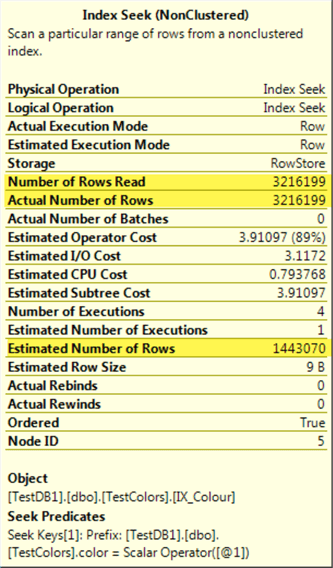
You can see that for both cases the estimated number of rows is the same, that is the average number of rows for all cases:

The execution plan displayed will depend on what parameter you have executed first, so results can vary for the same test.
There is also a trace flag option that does the same as the database scoped configuration, but I personally do not recommend it since it affects the entire SQL Server instance.
Now you have a starting point to make good-performing code, and you can always read further on any topic you want.
Next Steps
- Check Part 1 where we discuss some database design considerations.
- Check Part 2 to some T-SQL considerations when writing code.
- Check other performance tuning tips here.

Eduardo Pivaral is an MCSA, SQL Server Database Administrator and Developer with over 15 years of experience working in large environments.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2020 | Author of the Year Contender – 2019 | Rookie of the Year – 2018


