Problem
In a previous tip, I talked about a new function in SQL Server 2019, sys.dm_db_page_info. In that tip, I also talked about another (though undocumented) function, sys.dm_db_database_page_allocations. After some interesting behavior with the latter function, I thought I would give a little warning about its usage in larger systems.
Solution
I have a throwaway database in our dev environment ("OCopy") that I have been using for a variety of tests and demos. An interesting aspect of this database is that it has a table that is over 1 TB in size, and this is fun, because it tends to surface scale-related issues that I might not see otherwise.
As part of one of my recent tests, I wanted to count the 8k data pages in that large table before and after certain operations, like applying page compression or rebuilding indexes.
I tested this sequence on smaller tables first, to make sure my syntax was right, before I unleashed it on the mammoth. While overly simplified, I did something like this:
CREATE TABLE dbo.smalltable(id int, CONSTRAINT pk_st PRIMARY KEY(id));
<br />INSERT dbo.smalltable(id) SELECT object_id FROM sys.all_objects; -- 2,334 rows<br /><br />SELECT COUNT(*) FROM sys.dm_db_database_page_allocations<br /> (DB_ID(), OBJECT_ID(N'dbo.smalltable'),1,1,'limited');<br /><br />ALTER TABLE dbo.smalltable REBUILD WITH (ONLINE = ON, DATA_COMPRESSION = PAGE);<br /><br />SELECT COUNT(*) FROM sys.dm_db_database_page_allocations<br /> (DB_ID(), OBJECT_ID(N'dbo.smallatble'),1,1,'limited');
This took close to 30 minutes. Astute readers – or those who try the code above before reading on – will notice the typo in one of my arguments: smallatble. The function is rather forgiving; it assumes that when you pass NULL for the object, whether you intended to or not, you want the sum of page allocations for the entire database. But what I expected was just a larger number in the second output; I did not expect counting ~134 million rows from this dynamic management function to take 30 minutes.
I ran it again, this time capturing an execution plan and monitoring waits. The waits were relatively uninteresting; the relevant ones were as follows, and most were stable except for PAGEIOLATCH_SH:
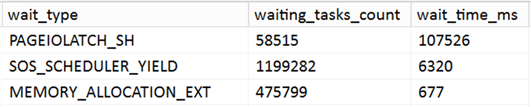
This seems reasonable, since the function has to read every single page, even in limited mode. And watching sys.dm_os_buffer_descriptors, you can see more and more pages pulled into the buffer pool. But the numbers don’t make sense to me. At a point when there ~90,000 pages in the buffer pool, the session had already performed 4,542,291,613 logical reads. Yes, you read that right: four and a half billion logical reads, which seems quite disproportionate to me.
The plan didn’t yield much useful information:
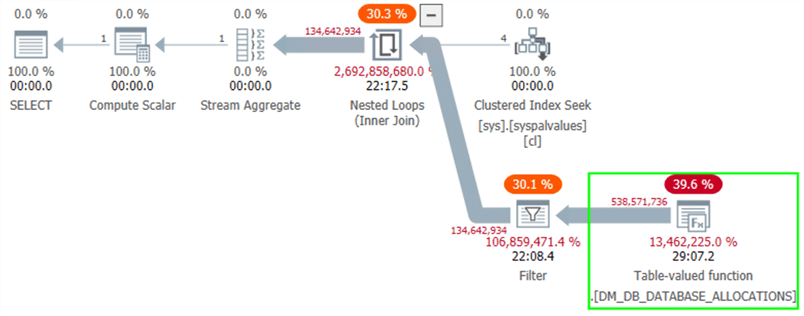
Except that if you switch to estimated costs and display for I/O only, we can see the fantastically low estimate as well as where SQL Server thought it would perform all of the I/O work:
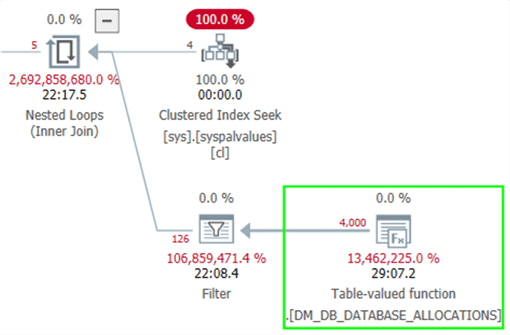
So, I set up some tests to see what happens in other cases. I had some other throwaway databases on this instance, of varying sizes:

Then I set up a script that would simply time First, a logging table in a separate database (Utility):
CREATE TABLE dbo.Logging<br />(<br /> db nvarchar(128),<br /> dbsize decimal(12,2),<br /> page_count bigint,<br /> logical_reads bigint,<br /> buffer_pages bigint,<br /> ts datetime2,<br /> description varchar(255)<br />);
Then a loop in a separate window to capture logical reads every 5 seconds throughout the tests (since these reset at inopportune times, it is harder to capture those inline):
SET NOCOUNT ON<br /><br />WHILE 1 = 1<br />BEGIN<br /> INSERT Utility.dbo.Logging(logical_reads, ts, description) <br /> SELECT logical_reads, sysdatetime(), '{ sample }'<br /> FROM sys.dm_exec_requests <br /> WHERE session_id = 64;<br /> <br /> WAITFOR DELAY '00:00:05';<br />END
Then the test for any given database looked like this (sample from Test011):
DBCC DROPCLEANBUFFERS;<br />GO<br /><br />USE Test011;<br />GO<br /><br />INSERT Utility.dbo.Logging(db, dbsize, ts, description) <br /> SELECT DB_NAME(),300.94, sysdatetime(), 'start no table';<br />GO<br /><br />DROP TABLE IF EXISTS dbo.what;<br />GO<br /><br />INSERT Utility.dbo.Logging(db, page_count, ts, description)<br /> SELECT DB_NAME(), COUNT(*), sysdatetime(), 'no table'<br /> FROM sys.dm_db_database_page_allocations(DB_ID(),OBJECT_ID(N'dbo.what'),1,1,'limited');<br />GO<br /><br />INSERT Utility.dbo.Logging(db, buffer_pages, ts, description)<br /> SELECT DB_NAME(), COUNT(*), sysdatetime(), 'done no table; start table'<br /> FROM sys.dm_os_buffer_descriptors<br /> WHERE database_id = DB_ID();<br />GO<br /><br />DBCC DROPCLEANBUFFERS;<br />GO<br /><br />CREATE TABLE dbo.what(id int);<br />GO<br /><br />INSERT Utility.dbo.Logging(db, page_count, ts, description)<br /> SELECT DB_NAME(), COUNT(*), sysdatetime(), 'with table'<br /> FROM sys.dm_db_database_page_allocations(DB_ID(),OBJECT_ID(N'dbo.what'),1,1,'limited');<br />GO<br /><br />INSERT Utility.dbo.Logging(db, buffer_pages, ts, description)<br /> SELECT DB_NAME(), COUNT(*), sysdatetime(), 'done with table'<br /> FROM sys.dm_os_buffer_descriptors<br /> WHERE database_id = DB_ID(); <br />GO<br /><br />DROP TABLE IF EXISTS what;<br />GO
I ran the tests for all 5 databases, went for coffee, then cleaned up and summarized the data in the logging table. Here is the relevant information from just the tests involving reading the whole database because the table was not found (the results with the empty table that does exist were identical and uninteresting across all databases):
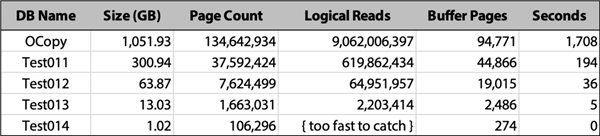
For the 1TB database, we see 9 billion reads. That’s about 14 times the number of reads than a database a little over a third its size (and took almost 10 times as long to process). The data shows how performance gets exponentially worse as the database gets bigger. The clearest way I could think of to show this in a chart would be to display logical reads per GB. For every GB of data, how many logical reads are required? For the four processes that ran long enough to capture logical reads, the hockey stick is very evident when plotted this way:
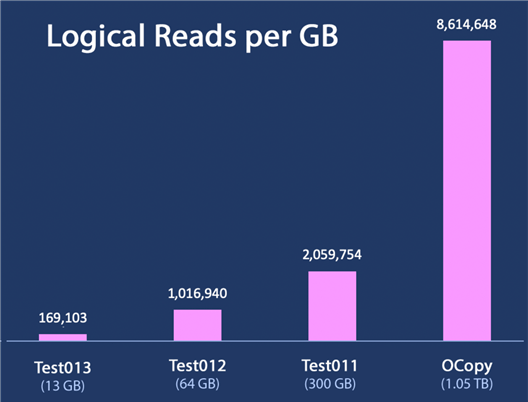
There is definitely some kind of exponential increase in logical reads as the size of the database increases – while you would expect reads to increase relatively linearly with database size, we are observing logical reads per GB quadruple when going from 300 GB to 1.05 TB. I would expect total logical reads to triple or maybe quadruple in that case, but not logical reads per GB.
Side Effects
In addition to taking a long time, a couple of other things I noticed when using this function against a large database:
- Sch-S locks are taken on
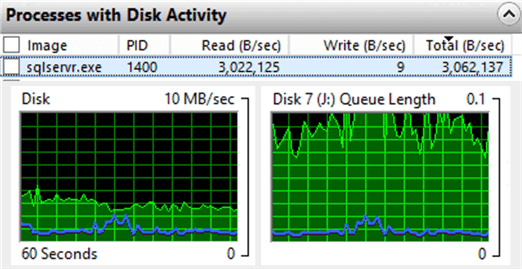
syspalvaluesand the table being read. While this doesn’t block normal read or write activity against any table, it does block DDL on the current target. So anALTER TABLEon the object currently being read, for example, will wait. I did not track how the function reads the data when it’s reading everything; with many large tables, it could very well alternate between objects as it goes, meaning blocking on any specific object could be unpredictable and happen many times during the process. - Disk gets thrashed by SQL Server. This is not all that surprising, but good to keep in mind. If the data file(s) for the database share disk with other databases or applications, there will be contention on those drives, in addition to overall I/O. Here is the disk activity at a random point in time during the
LIMITEDmode process for the 1TB database:
- DETAILED takes longer. A lot longer. I killed the process against the 1TB database after 12 hours, at which point it had only reached 4.25 billion reads. If we were retrieving the results, the process would need to also keep track of things like ghost records per page. We’re discarding those details because we’re just getting a count, so it shouldn’t really need to materialize anything or look at the pages in more detail. There doesn’t seem to be any optimization here that tells the function we’re not going to use that detail level information (even though, and because, we explicitly asked for it). So this thrashes the disks a lot harder, as Sebastien Meine suggested might happen. While the following charts looks similar to
LIMITEDmode, pay close attention to the scale on the y-axis – both charts are an order of magnitude larger:

- The symptoms were not isolated to this system. I thought (and you probably thought, too) maybe something in the metadata was corrupt, or something specific about this database was causing the problem. I found another system in our environment with a 672 GB database and reproduced a similar scenario. And something more. If I ran the query repeatedly, the duration crept higher and the logical reads increased by about 400 million each time (to a cap of around 1.95 billion):

Various attempts to clear in-memory caches (DBCC DROPCLEANBUFFERS, DBCC FREESYSTEMCACHE('ALL')) had no effect, but I didn’t try a reboot. I can’t really explain this, yet. The logical reads are way too high even the first time the query runs, but it’s even more bizarre how the same query yields more and more reads each time it runs. In any case, something to watch out for.
Recommendations
- Be aware of both the cost and the side effects of this function, especially on bigger databases or environments with “less than robust” I/O subsystems. Also note that repeated calls can make this worse.
- Be careful to target only the object(s) you care about. The function treats typos the same as explicit
NULL. - Avoid
DETAILEDmode, except in cases where you really do need the additional detail it provides. - Since it is an undocumented function, it is unsupported, so behavior can change at any time. If you incorporate the function into production processes, you are exposing those processes to risk.
- If you’re just trying to ballpark space for a table or index, try to extrapolate from less intrusive sources, like sys.partitions, sp_spaceused, and others. If the table you care about is the only object on a specific filegroup, you can also look at FILEPROPERTY, since the sum of space used on all the data files is going to roughly equal the size of the object.
Next Steps
Read on for related tips and other resources:
- New Function in SQL Server 2019 – sys.dm_db_page_info
- The sys.dm_db_database_page_allocations DMF
- Determining space used for all tables in a SQL Server database
- Different ways to determine free space for SQL Server databases and database files

Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He also blogs at sqlblog.org.
- MSSQLTips Awards: Author of the Year – 2016, 2023 | Leadership (200+ tips) – 2022