Problem
Please provide examples using the set statistics time statement for tuning queries. In addition to a review of the set statistics time statement, present a general framework for assessing the parse, compile, and execution times of any query. Additionally, include examples that illustrate how to code rowstore and columnstore indexes based on the same table column as well as contrast the impact of using the two different types of indexes.
Solution
There are often multiple ways to return a results set with T-SQL. It is common for DBAs to be tasked with assessing the fastest T-SQL formulation for returning a results set. The set statistics time statement is one tool for assessing the fastest formulation for returning a result set or performing some data manipulation. This tip provides five examples showing how to assess times for T-SQL queries.
If you need help obtaining reliable results with the set statistics time statement, this may very well be the tip that you urgently need to read. The tip provides a framework for using the set statistics time statement in finding the times associated with a T-SQL query. More specifically, you will learn how to
- Turn the set statistics time feature on and off
- Interpret the output from the statement
- Initialize it for consecutively assessing and contrasting multiple query designs
Considerations for running set statistics time
The set statistics time statement can display the number of milliseconds to parse, compile, and execute a T-SQL query statement. This set statement is widely used to assess times to implement a query statement. The basic syntax for invoking the set statement appears below. Put the query for which you seek times in between set statistics time on and set statistics time off. The framework presented and demonstrated in this tip for assessing times associated with a query also uses several other statements described later in this section.
-- set statistics time on and off
set statistics time on
-- query goes in between time on and time off
set statistics time off
Times are sequentially divided conceptually into two segments: parse and compile time versus execution time.
- Parsing and compiling are grouped into a single set of operations.
- Parsing a query statement means verifying the syntax and segmenting the elements in a query statement for the preparation of a query plan.
- Compiling a query statement means converting the segmented elements into a query plan for execution. Compiled query plans are stored in the query cache.
- Execution time is the time that SQL Server spends running the compiled query plan.
The set statistics time statement reports the times for these two types of operation. Within each type, the time is further sub-divided into cpu time and elapsed time.
- The cpu time is the total time spent by the cpu resources on a server. If a server has five cpus, and each cpu runs 3 milliseconds concurrently with the other cpus, then the total cpu time is 15 milliseconds.
- The elapsed time is the total time taken by SQL Server. The set statistics time statement reports elapsed times separately for parse and compile operations as well as the execution of a compiled plan. The elapsed time is how long the operation (either parse and compile or execution of the compile plan) takes overall.
This tip’s framework for assessing the times for a query statement relies on three additional statements. These three statements aim to prepare a fresh environment for each test query’s time assessment. If you run your time assessments successively in one script, this feature can be useful because the results for one assessment can be independent of any assessments run before it.
- Two of the three additional statements appear at the top of the following script framework. These two statements (dbcc dropcleanbuffers and checkpoint) clear the data buffers of any uncommitted data developed during prior time assessments.
- The third statement (dbcc freeproccache) appears just before the set statistics time on statement. This statement can clear the query cache on a server. By clearing the query cache just before assessing its time, you simplify the identification and analysis of a test query in the cache. Microsoft does not recommend running this statement on a production server.
Notice that between the checkpoint statement and the dbcc freeproccache statement there is room for optional T-SQL statements. Theses optional statements can configure an environment for testing a query design. For example, in one run of the framework, you could create some rowstore indexes. Then, in a second run of the framework, you could create some columnstore indexes.
-- clear the buffers before time monitoring
dbcc dropcleanbuffers;
checkpoint;
-- perform any additional operations for enabling a test query design
-- such as creating keys and indexes
-- flush query cache on server
dbcc freeproccache with no_infomsgs;
-- set statistics time on and off
set statistics time on
-- query goes in between time on and time off
set statistics time off
The test database tables for this tip
This tip demonstrates approaches to timing different environments for joining two tables in the for_csv_from_python database. The table names are yahoo_prices_valid_vols_only and ExchangeSymbols. See this tip (Time Series Data Fact and Dimension Tables for SQL Server) for code creating and populating the yahoo_prices_valid_vols_only table. The tip describes how to populate a data warehouse with time series data; the yahoo_prices_valid_vols_only is a fact table in the data warehouse. See this other tip (Collecting Time Series Data for Stock Market with SQL Server) for an example of how to collect raw data for a data warehouse with time series data; additionally this second tip presents code for creating and populating the ExchangeSymbols table.
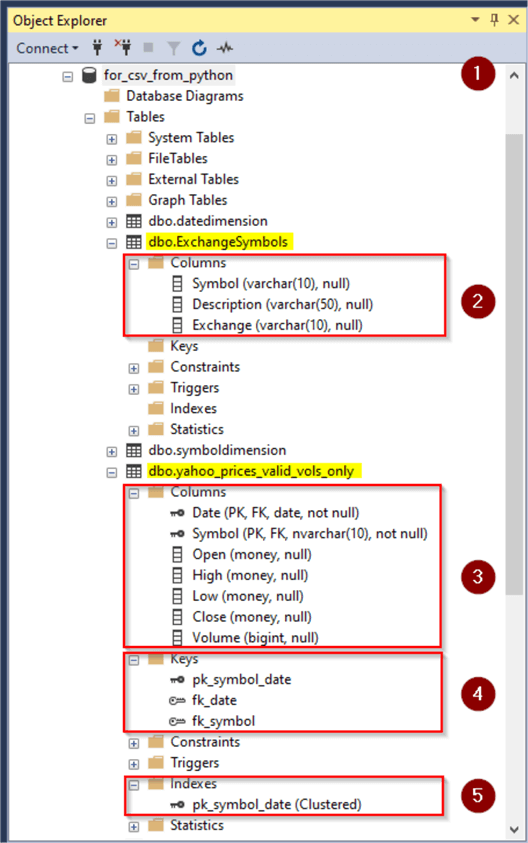
The following screen shot shows an Object Explorer view of the database, tables, and selected elements from each table.
- Item 1 denotes the database name (for_csv_from_python).
- Item 2 shows the column names in the ExchangeSymbols table within the dbo schema. The ExchangeSymbols tables has no keys nor indexes in its default configuration below.
- Item 3 shows the column names in the yahoo_prices_valid_vols_only table within the dbo schema. This table also has three keys as well as one index in its default configuration.
- Item 4 shows the names for the keys in the yahoo_prices_valid_vols_only table.
- pk_symbol_date is the name for the primary key. Rows are unique by symbol and date column values.
- fk_date is the foreign key in the the yahoo_prices_valid_vols_only table pointing at rows in the datedimension table within the data warehouse.
- fk_symbol is the foreign key in the yahoo_prices_valid_vols_only table pointing at rows in the symboldimension table within the data warehouse.
The next screen shot shows several queries with the yahoo_prices_valid_vols_only and ExchangeSymbols tables.
- The yahoo_prices_valid_vols_only fact table has 14620885 rows.
- The fact table also has 8089 distinct symbols. A symbol can appear on multiple rows for a set of trading dates during which its stock trades.
- The ExchangeSymbols table has 8856 rows. There is one row for each distinct symbol in ExchangeSymbols. As a result, the ExchangeSymbols table contains some symbols that do not appear in the yahoo_prices_valid_vols_only fact table. This is, in part, a consequence of the two tables being from two different organizations that do not always follow the same naming conventions for symbols representing securities.
- The join of the yahoo_prices_valid_vols_only fact table with the ExchangeSymbols table contains 14620885 rows. The row count matches the number of rows in the yahoo_prices_valid_vols_only fact table before it is joined to the ExchangeSymbols table.

Start-to-end review of a set statistics time example
The final query in the preceding screen shot is a test query that this tip times in various configurations with different keys and indexes. The T-SQL syntax for the test query joins symbol values between the yahoo_prices_valid_vols_only and ExchangeSymbols tables. The screen shot immediately before the previous one reveals the default configuration for the yahoo_prices_valid_vols_only table includes a primary key (pk_symbol_date) and a foreign key (fk_symbol) that may be able to help query performance. The default configuration for the ExchangeSymbols table includes no keys or indexes to accelerate query performance.
The following script uses the set statistics time statement to assess the parse and compile time as well as the execution time. Recall that both parse and compile time as well as execution time are segmented into cpu time and elapsed time.
After a use statement sets the database context to for_csv_from_python, there are four main parts to the script.
- One part invokes code to clear data buffers. This step is there so that each test of a key and index architecture for running a query starts from a fresh environment relative to any prior queries that may have run.
- The second part creates fresh copies of the pk_symbol_date and fk_symbol. These keys are there by default unless some intermediate code changes their status by, for example, dropping either or both.
- The third part is a dbcc freeproccache statement to clear the query cache. This ensures there is just one query in the query cache when the on and off set statistics time statements operate in the fourth part.
- The fourth part invokes the set statistics time on and set statistics time off statements encapsulating a T-SQL query to generate a results set. This T-SQL statement is the code for which times are calculated.
The code in the script is heavily commented, but here are a few summary remarks to help you navigate your way through the code.
- The dbcc dropcleanbuffers and checkpoint statements allow you to test a query with a cold data buffer without having to shut down and restart the server.
- The lines of code following the checkpoint statement and before the dbcc freeproccache statement conditionally drop and re-create fresh versions of the pk_symbol_date and fk_symbol keys for the yahoo_prices_valid_vols_only table.
- The dbcc freeproccache statement clears the query cache before invoking the set statistics time on statement. It is common advice to avoid invoking the dbcc freeproccache statement on a production server, but it is OK for use on a development server.
- Finally, the set statistics time on and set statistics time off statements embrace a test query that returns a count of the rows from the inner join of the yahoo_prices_valid_vols_only and ExchangeSymbols tables based on the symbol column in each table.
-- pk_symbol_date and fk_symbol for yahoo_prices_valid_vols_only
use for_csv_from_python
go
-- clear the buffers before time monitoring
dbcc dropcleanbuffers;
checkpoint;
-- conditionally drop the default primary key
if (select(object_id('pk_symbol_date'))) is not null
alter table dbo.yahoo_prices_valid_vols_only drop constraint pk_symbol_date;
-- add a fresh copy of the primary key
alter table dbo.yahoo_prices_valid_vols_only
add constraint pk_symbol_date primary key clustered (Symbol, Date);
-- conditionally drop the default foreign key constraint named fk_symbol
if (select(object_id('fk_symbol'))) is not null
alter table dbo.yahoo_prices_valid_vols_only drop constraint fk_symbol;
-- add a fresh copy of the default foreign key constraint named fk_symbol
alter table dbo.yahoo_prices_valid_vols_only
add constraint fk_symbol foreign key (Symbol)
references dbo.symboldimension (Symbol)
on delete cascade
on update cascade;
-- flush query cache on server
dbcc freeproccache with no_infomsgs;
-- time for join between yahoo_prices_valid_vols_only
-- and ExchangeSymbols tables
set statistics time on
-- test query
select count(*) [rows in join of yahoo_prices_valid_vols_only with ExchangeSymbols]
from [dbo].[yahoo_prices_valid_vols_only]
inner join [dbo].[ExchangeSymbols]
on [yahoo_prices_valid_vols_only].Symbol = [ExchangeSymbols].Symbol
set statistics time off
The Results tab populated by the preceding query has the same value as the last query statement in the preceding screen shot, which is the reason the Results tab is not shown in this section. This tab shows a value of 14620885 with a name of “rows in join of yahoo_prices_valid_vols_only with ExchangeSymbols”.
For the purposes of this tip, the most important information is in the Messages tab, which appears in the following screen shot. Within the Messages, there are two key types of time values. Each type is highlighted with a yellow background.
- The parse and compile time have two elements: one for cpu time and another for elapsed time.
- Similarly, the execution time have two elements: one for cpu time and another for elapsed time.
- As you can see, parsing and compilation occur much more quickly than execution.
- The “one row affected” text refers to the number of rows returned by the select statement that appears between the set statistics time on and off statements.

Summary times for five set statistics time examples
Now, you know the basics of how to run the set statistics time statement, and you have some grasp of the output from the statement. This section drills down on the results from five examples using the set statistics time statement. All examples use the exact same T-SQL test query used in the preceding section. Each example is for a specific set of indexes and/or keys for the yahoo_prices_valid_vols_only and ExchangeSymbols tables. As you will see, these keys and indexes can have a profound impact on the times associated with running the test query.
The five set statistics time examples are run consecutively one after the other. This section gives a very short summary of the key/index configuration for each example. Each example applies the set statistics time framework described in the “Considerations for running set statistics time” section. The T-SQL script for running the five consecutive examples is available from a link in the Next steps section.
The next screen shot shows times from the five examples. There are three columns in the summary of results from the five examples.
- The first column offers a very brief description of the example.
- The second column provides cpu time and elapsed time for parsing and compiling processing of the test query.
- The third column provides cpu time and elapsed time for executing the query plan for the test query in its environment of keys and/or indexes.
One of the most important issues to note is which example has the shortest elapsed time for executing the test query. This is the query design environment that you should choose to expedite query performance to the greatest extent. Three execution time cells are color coded to provide guidance about how to use the times reported by the set statistics time statement output.
- The elapsed time in cell D15 has the smallest value of any of the five examples. Recall that the yahoo_prices_valid_vols_only is a fact table with more than fourteen million rows from a data warehouse; as the description in cell B16, there is a columnstore index defined on the symbol column in the yahoo_prices_valid_vols_only table. Cell B15 also indicates a columnstore index exists for the symbol column in the ExchangeSymbols table. Columnstore indexes are well known for quick processing of rows from a large table with many rows.
- The elapsed time in cell D2 has the largest value of any of the five examples. This example has a primary key based on date within symbol as well as a foreign key for linking to the yahoo_prices_valid_vols_only table to the symboldimension table. It appears the primary key does not optimize performance for the test query.
- The second quickest example to run merely drops the primary key from the yahoo_prices_valid_vols_only table. The execution times for this example are in cell D5. Noticed the elapsed time is just 821 milliseconds, which is just about 300 milliseconds more than the example with non-clustered columnstore indexes.
- The other two examples have execution elapsed times in between the second shortest elapsed time (cell D5) and the longest execution elapsed time (cell D2).
- The next section drills down on how to implement the fourth and fifth examples, which depend respectively on rowstore indexes and columnstore indexes.

It may be also useful to contrast elapsed time for parse and compile time versus execution of a compiled query plan. Across all five examples, the elapsed time for parsing and compiling the test query varied between six and eight milliseconds. In contrast, elapsed execution times vary between several hundred and several thousand milliseconds. For these examples, which may have parse and compile times as well as execution times similar to many other queries, the execution times are two to three orders of magnitude greater than the parse and compile times. In other words, parse and compile times do not have a significant impact on performance.
You may have noticed that the times for the first example in this section and the example in preceding section report different times for running the same query with the same indexes. It is not uncommon for elapsed times to vary slightly in successive runs of the same query. In my experience, the exact time values can vary, but the relative order of the elapsed times within a set of runs stays the same. The constantly changing load on a SQL Server as well as the computer on which it runs most likely accounts for these differences.
Code examples for rowstore indexes versus columnstore indexes
The rowstore index code example for timing a query is for the fourth example in the consecutive series of five examples from the prior section. The code for this example is designed to run after the code for the first, second, and third examples complete successfully. The main goals of the example are to add a clustered primary key based on date within symbol for the yahoo_prices_valid_vols_only table and a non-clustered index based on symbol for the ExchangeSymbols table. This example also removes the key and the index added to the tables after timing the test query.
- The code starts with a use statement to declare a default database context.
- Next, a dbcc dropcleanbuffers statement followed by a checkpoint statement clear the data buffers so that timing results for this example will not be impacted by data buffer contents from other previously run timing examples.
- Then, an alter table statement adds a clustered primary key named pk_symbol_date to the yahoo_prices_valid_vols_only table after a preceding alter table statement removes any prior version of the pk_symbol_date key.
- Then, a create nonclustered index statement adds a fresh non-clustered index named ix_ExchangeSymbols_Symbol to the ExchangeSymbols table after a preceding drop index removes any prior version of the index to the table.
- A dbcc freeproccache statement clears the contents of the query cache just before invoking the set statistics time on and off statements to assess the times for processing the test query. The with no_infomsgs clause suppresses informational messages associated with the dbcc freeproccache statement.
- Then, the set statistics time on and off statements generate time assessments for the Messages pane during the running of the test query.
- The script concludes with code to remove the pk_symbol_date primary key from the yahoo_prices_valid_vols_only table and the ix_ExchangeSymbols_Symbol index from the ExchangeSymbols table.
-- nonclustered rowstore index (ExchangeSymbols table)
-- clustered primary key (yahoo_prices_valid_vols_only table)
use for_csv_from_python
go
-- clear the buffers before time monitoring
dbcc dropcleanbuffers;
checkpoint;
-- conditionally drop prior primary key named pk_symbol_date
if (select(object_id('pk_symbol_date'))) is not null
alter table dbo.yahoo_prices_valid_vols_only drop constraint pk_symbol_date;
-- add fresh version primary key named pk_symbol_date
alter table dbo.yahoo_prices_valid_vols_only
add constraint pk_symbol_date primary key clustered (Symbol, Date);
-- conditionally drop ix_ExchangeSymbols_Symbol on dbo.ExchangeSymbols
if exists (select name FROM sys.indexes
where name = N'ix_ExchangeSymbols_Symbol')
drop index ix_ExchangeSymbols_Symbol on dbo.ExchangeSymbols;
-- create non-clustered index for Symbol in ExchangeSymbols
create nonclustered index ix_ExchangeSymbols_Symbol
ON dbo.ExchangeSymbols (Symbol);
-- flush query cache on server
dbcc freeproccache with no_infomsgs;
-- time for join between yahoo_prices_valid_vols_only
-- and ExchangeSymbols tables
set statistics time on
-- test query
select count(*) [rows in join of yahoo_prices_valid_vols_only with ExchangeSymbols]
from [dbo].[yahoo_prices_valid_vols_only]
inner join [dbo].[ExchangeSymbols]
on [yahoo_prices_valid_vols_only].Symbol = [ExchangeSymbols].Symbol
set statistics time off
-- remove rowstore indexes
-- conditionally drop ix_ExchangeSymbols_Symbol on dbo.ExchangeSymbols
IF exists (select name FROM sys.indexes
where name = N'ix_ExchangeSymbols_Symbol')
drop index ix_ExchangeSymbols_Symbol on dbo.ExchangeSymbols;
-- conditionally drop prior primary key named pk_symbol_date
if (select(object_id('pk_symbol_date'))) is not null
alter table dbo.yahoo_prices_valid_vols_only drop constraint pk_symbol_date;
The columnstore index code example for timing a query is for the fifth example in the consecutive series of five examples for timing query performance within the prior section. This example also demonstrates syntax for conditionally adding non-clustered columnstore indexes to SQL Server tables as well as unconditionally dropping the indexes if they are no longer required.
- As with the preceding example, the code begins by setting the default database context and clearing the data buffers from the running of any prior code.
- A try…catch code block is used for adding a non-clustered columnstore index to the ExchangeSymbols table.
- The try block contains a create nonclustered columnstore index statement having a drop_existing setting of off. Therefore, the create nonclustered columnstore index statement fails if the index already exists.
- The catch block operates if there is a failure in the try block. The code in the catch block also contains a create nonclustered columnstore index statement, but its drop_existing clause is set to on. This setting causes the create nonclustered columnstore index statement to drop any prior version of the index before attempting to create a fresh copy of the index.
- Another try…catch code block with the same basic features is used to add a fresh non-clustered columnstore index based on symbol column values within the yahoo_prices_valid_vols_only table.
- Aside from adding fresh versions of the non-clustered columnstore indexes to the ExchangeSymbols and yahoo_prices_valid_vols_only tables, the code operates according to the same guidelines as used for the rowstore indexes in the preceding example.
- The query cache is cleared.
- The set statistics time on and off statements are run with the test query between them.
- The columnstore indexes are removed after the elapsed times are calculated.
-- nonclustered columnstore index (ExchangeSymbols table)
-- nonclustered columnstore index (yahoo_prices_valid_vols_only table)
use for_csv_from_python
go
-- clear the buffers before time monitoring
dbcc dropcleanbuffers;
checkpoint;
-- create first nonclustered columnstore index
begin try
create nonclustered columnstore index [ix_ncl_cs_ExchangeSymbols_Symbol]
on [dbo].[ExchangeSymbols] ([Symbol])
with (drop_existing = off, compression_delay = 0)
end try
begin catch
create nonclustered columnstore index [ix_ncl_cs_ExchangeSymbols_Symbol]
on [dbo].[ExchangeSymbols] ([Symbol])
with (drop_existing = on, compression_delay = 0)
end catch
-- create second nonclustered columnstore index
begin try
create nonclustered columnstore index [ix_ncl_cs_yahoo_prices_valid_vols_only_Symbol_date]
on [dbo].[yahoo_prices_valid_vols_only] ([Symbol],[Date])
with (drop_existing = off, compression_delay = 0)
end try
begin catch
create nonclustered columnstore index [ix_ncl_cs_yahoo_prices_valid_vols_only_Symbol_date]
on [dbo].[yahoo_prices_valid_vols_only] ([Symbol],[Date])
with (drop_existing = on, compression_delay = 0)
end catch
-- flush query cache on server
dbcc freeproccache with no_infomsgs;
-- time for join between yahoo_prices_valid_vols_only
-- and ExchangeSymbols tables
set statistics time on
-- test query
select count(*) [rows in join of yahoo_prices_valid_vols_only with ExchangeSymbols]
from [dbo].[yahoo_prices_valid_vols_only]
inner join [dbo].[ExchangeSymbols]
on [yahoo_prices_valid_vols_only].Symbol = [ExchangeSymbols].Symbol
set statistics time off
-- remove nonclustered indexes
drop index [ix_ncl_cs_ExchangeSymbols_Symbol]
on [dbo].[ExchangeSymbols]
drop index [ix_ncl_cs_yahoo_prices_valid_vols_only_Symbol_date]
on [dbo].[yahoo_prices_valid_vols_only]
Next Steps
Try out the code examples for this tip. If you want to test the code with the data used for demonstrations in this tip, then you will also need to run scripts from here (Collecting Time Series Data for Stock Market with SQL Server) and here (Time Series Data Fact and Dimension Tables for SQL Server).
No attempt has been made in this tip to pick optimal index or key designs for the tables in the test query. However, you can tell the elapsed time for each consecutive test.
- At the very least, I would test an environment with a non-clustered rowstore index based on symbols for both the yahoo_prices_valid_vols_only table and ExchangeSymbols table.
- I would also compare non-clustered columnstore index timing results to clustered columnstore index timing results.
- When working with databases from your business, the needs of your project will dictate the scenarios that are most worthy of you testing with the framework for using the set statistics time statement described in this tip.

Rick Dobson is a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been a practicing Python developer for more than the past half decade – with a special emphasis for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. If you are interested in growing your skills in any of these areas especially as they relate to financial securities, consider visiting his blog at https://securitytradinganalytics.blogspot.com/2023/12/.
- MSSQLTips Awards: Leadership (200+ tips) – 2025 | Author of the Year Contender – 2017-2024


