Problem
The most attractive feature of Azure Data Factory is the support for multiple source and target formats. The following MSDN article goes over the available connectors for the copy activity. Since a data lake is comprised of folders and files, we are extremely interested in the file formats supported by ADF. How do we add support for multiple file formats to the existing parameterized pipeline?
Solution
There are two activities related to controlling the execution flow for a given pipeline. The “if condition” activity allows for the conditional execution of activities given either a true or false expression. In our example, we will just code for the true conditions. The switch activity allows for the conditional execution of activities given an expression that evaluates to a string. The default activity is only executed when the expression does not match any of the supplied case values. While the two statements can be used to design a dynamic pipeline that supports multiple formats, the if activity will waste a few more computing cycles to achieve the same logic.
Background
The development environment created in the previous article will be used to extend the parameter driven pipeline to support multiple destination formats. The following image shows the eight different file formats that can be chosen when setting up a data set for an Azure Data Lake linked service. Our boss has asked us to investigate the use of these data sets in our final dynamic pipeline solution.

One quick way to test a new data set type is to have a set of predefined files existing in the data lake. The enclosed zip file has at least one file per format. The delimited format has two files: csv – comma delimited format and txt – pipe delimited format. The use of a program language specific binary is frown upon nowadays. Who really wants to know the difference between Java and C# floating point numbers at the bit level? Therefore, I chose to zip up the delimited text file to represent a binary file format.
In short, we will be reviewing how to set up data sets with dynamic parameters in the following chapters.
Delimited File Format
The delimited file format has been in use for many years. Logically, the data can be divided into rows and columns. Typically, a carriage return and a new line marks the end of a row of data. Each column is clearly marked by a separator. Optionally, a header line can contain the labels for each of the columns. There are several issues that do not make this format ideal. First, the data types in the file cannot be determined without scanning the file. This is called inferring the data type. Second, the format can be easily broken by humans by adding an additional column or row separator. Third, the text file format makes it very easy for unwanted users to look at the data which might be confidential. Fourth, numeric columns that have leading zero might be converted to their integer or decimal value. This can be fixed by escaping the string with a quote separator and having the target field be a string.
The image below shows the definition of the data set named DS_ADLS2_FILE_TYPE_CSV for the linked service named LS_ADLS2_DATALAKE_STORAGE.

Three pieces of information should be parameterized for this format. The DIR_NAME is used to define the folder, the FILE_NAME is used to define the path, and the DELIMITER is used to change the column separator. Please note I decided to change the last three characters to DEL. This is important. As a default, the data set is setup for comma separated values. However, that can be easily changed by modifying the default value.

The image below shows the completed data set. Please make sure your company follows a standard naming convention for a consistent look and feel. Descriptions for all objects defined within Azure Data Factory make it easier for a developer to pick up the project in the future. Make sure to check off the first row as header if want readable column headings add to the resulting file.

In short, the delimited format does not support compression natively, is not a binary format and does not contain a schema definition. In general, it is very popular format used by the business line. Any comma separated values file can be consumed by Microsoft Excel. The ADF connector does support de-compression before reading and compression after writing. Many popular compression formats are available. Please see MSDN documentation for more information on the Delimited format.
Avro File Format
The Apache Avro file format uses row-based storage and is widely used within Hadoop systems. Avro stores the schema definition in JSON format making it easy to read and stores the data in a binary format making it compact and efficient. The ability to serialize an object from code to storage makes this format popular with developers of many languages. Additionally, the format allows for the tracking of schema lineage which may change over time.
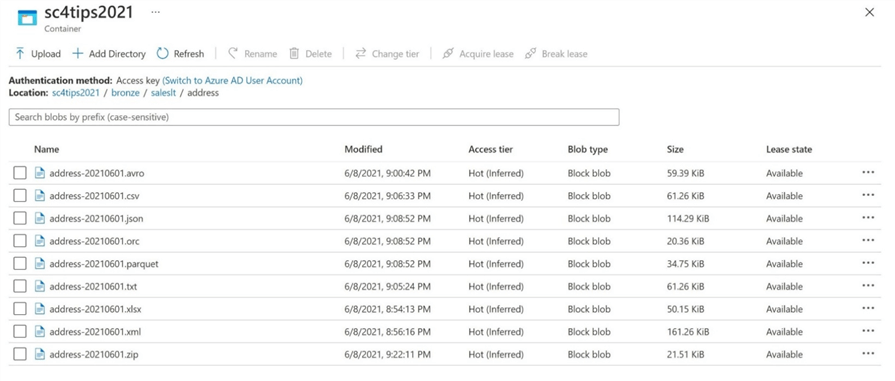
The image below shows the definition of the data set named DS_ADLS2_FILE_TYPE_AVRO for the linked service named LS_ADLS2_DATALAKE_STORAGE.

Again, the name of the folder and file should be parameterized. The image below shows the correct (AVRO) extension being added to the table name.

Finally, we want to use the previously defined parameters in the correct section of the file path. Please note that the container name, sc4tips2021, starts off the fully qualified path name. Optionally, compression can be applied to make the file smaller in size.
There are two main actions not shown in this screen shot. First, we can check the connectivity of the linked service. Second, we can preview the data within the file. If you want to view the data, please copy over the sample file to the address directory and update the parameter accordingly. Please see MSDN documentation for more information on the Avro format.
JSON File Format
JavaScript Object Notation (JSON) is an open standard file format used for data interchange. Human readable text is used to store objects as key-value pairs. More complex objects such as an image can be converted to text using encoding and stored in the record as a string. JSON has become very popular format with web applications. Any text-based format will have limitations and/or issues. For example, if a table with many records is stored in a JSON format, the resulting file can take up a large amount of disk space. Additionally, non-integer numbers must be converted to text. This may lead to small rounding and/or small precision errors.
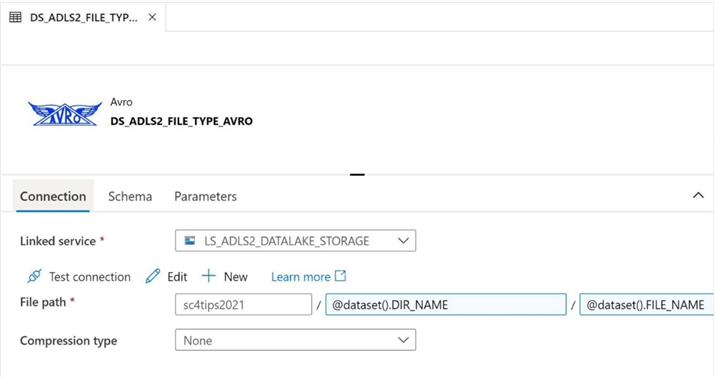
The image below shows the definition of the data set named DS_ADLS2_FILE_TYPE_JSON for the linked service named LS_ADLS2_DATALAKE_STORAGE.

Once more, the name of the folder and file should be parameterized. The image below shows the correct (JSON) extension being added to the table name.

To complete the data set definition, we need to replace the correct sections of the file path with the correct parameters. Two optional settings control how the file is saved. First, text files can be encoded for many different operating systems. The default encoding is UTF-8. Second, the ADF connector does support de-compression before reading and compression after writing. Many popular compression formats are available to choose from.
The JSON format has become very popular since the invention of the internet and web programs. One major drawback with the format is its resulting file size since the keys are stored for every single record. Please see MSDN documentation for more information on the JSON connector used within ADF.
ORC File Format
The Apache ORC (Optimized Row Columnar) is a free and open-source column-oriented data storage format for the Hadoop ecosystem. In January of 2013, there was an initiative to speed up Apache Hive and improve the storage efficiency of files stored in Hadoop. The format is optimized for large streaming reads but has support for indexing so that single record lookups can be retrieved efficiently. Other important features are the support for complex data types and ACID transactions.
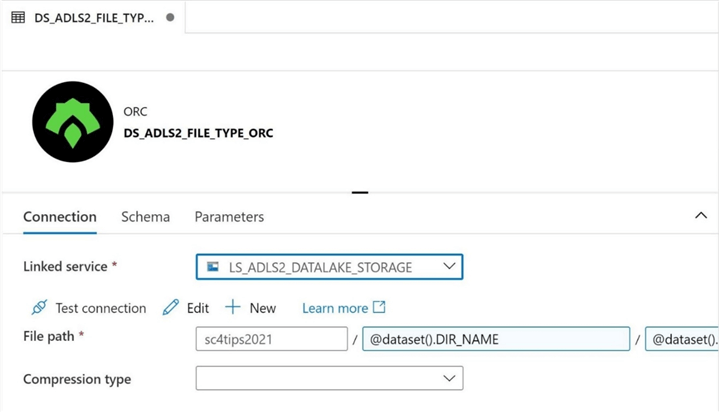
The image below shows the definition of the data set named DS_ADLS2_FILE_TYPE_ORC for the linked service named LS_ADLS2_DATALAKE_STORAGE.
Once more, the name of the folder and file should be parameterized. The image below shows the correct (ORC) extension being added to the table name.

To complete the data set definition, we need to replace the correct sections of the file path with the correct parameters. There is an optional compression type that you can specify with the data set. I choose not to use any compression at this time.
If you go back to the sample files supplied at the top of this article, you will see that the ORC file for the address table takes the least amount of space to store. It is not surprising that big internet companies such as Facebook and Yahoo use this format to save on disk space while achieving fast access times to the data. Please see MSDN documentation for more information on the ORC connector used within ADF.
Parquet File Format
The Apache Parquet is a free and open-source column-oriented data storage format for the Hadoop ecosystem. It was written from the ground up to support a variety of compression algorithms as well as encoding schemes. This format is considered strictly typed since he schema definition is stored within the file. Parquet ranks number two, in terms of size, for our sample file experiment. This format is extremely popular since it is the key building block of the delta file format.
The image below shows the definition of the data set named DS_ADLS2_FILE_TYPE_PARQUET for the linked service named LS_ADLS2_DATALAKE_STORAGE.

It makes sense that the name of the folder and file should be parameterized. The image below shows the correct (PARQUET) extension being added to the table name.

To complete the data set definition, we need to replace the correct sections of the file path with the correct parameters. The snappy compression type is supported by the AVRO, ORC and PARQUET file formats. It is my go-to compression algorithm for Apache file formats.

The Databricks Delta Table has gained popularity since its general availability in February of 2019. The delta architecture provides a transactional way to look at large data sets stored as files on Azure Data Lake Storage. The delta log keeps track of actions that happen to the data sets. Versioned parquet files keep track of the data at points in time and indexes & statistics complete the design. What is attractive to developers is he fact that the delta file has ACID (atomic, consistent, independent & durable) properties. For those who like change data capture, the time travel feature of the architecture allows you to look at the data for a given point of time.
In short, I can keep on talking about the Delta file format. However, some of the credit should go to the parquet file format which is the foundation of this architecture. Please see MSDN documentation for more information on the Parquet connector used within ADF.
Excel File Format
The Microsoft Excel format was originally released in 1987. Many changes have happened to the office product to keep it current with the latest version of the Windows Operating System. Due to the large user base and it being ranked the number two Cloud Office Suite, the Microsoft Excel format is here to stay. Unlike previous formats, the ADF connector for Excel can only be a source data set. In other words, one can only read, not write Excel files.
The image below shows the definition of the data set named DS_ADLS2_FILE_TYPE_EXCEL for the linked service named LS_ADLS2_DATALAKE_STORAGE.

The image below shows the correct (XLSX) extension being added to the table name. Unlike previous formats, the directory name and file name are not enough information to uniquely identify the data. Each spreadsheet can contain multiple worksheets. Therefore, the worksheet name is a required parameter.

To complete the data set definition, we need to replace the correct sections of the connection with the correct parameters. There are six more options to this format that I will let you discover.

This file format can only be used as a source in a copy activity. Therefore, we can use a pipeline to copy the data from one format to another. I’ll leave this experiment as exercise you can complete. However, the quickest way to test the data set is to place a sample file in the correct file path. The image below shows the first three records of the file in a preview window.

In a nutshell, I have been working with the Microsoft Excel format for over 30 years. It is a file format that will be found on-premises as well as in-cloud. Please see MSDN documentation for more information on the Excel connector used within ADF.
XML File Format
The Extensible Markup Language (XML) is a file format that defines a set of rules for encoding documents in text file that is both human-readable and machine-readable. XML is widely used in a Service-oriented architecture (SOA) in which disparate systems communicate with each other by exchanging messages. The message exchange format is standardized by using an XML schema (XSD). In a nutshell, XML has become a commonly used format for the interchange of data over the Internet.
The image below shows the definition of the data set named DS_ADLS2_FILE_TYPE_XML for the linked service named LS_ADLS2_DATALAKE_STORAGE.

Once again, the name of the folder and file should be parameterized. The image below shows the correct (XML) extension being added to the table name.

To complete the data set definition, we need to replace the correct sections of the file path with the correct parameters. Additionally, we can pick a compression type, encoding format and null value. For this simple test, I am going to take the defaults.

This file format can only be used as a source in a copy activity. Therefore, we can use a pipeline to copy the data from one format to another. I leave this experiment as exercise you can complete. However, the quickest way to test the data set is to place a sample file in the correct file path. The image below shows the first two records of the file in a preview window.

Many popular products use the XML format. For example, Microsoft saves excel data in the XLSX format and SQL Server Integration Packages in the DTSX format. Please see MSDN documentation for more information on the XML connector used within ADF.
Binary File Format
Both the EXCEL and XML formats are limited to having the data type being used as a data set source. Thus, you can copy from these formats to another using the COPY activity. The binary format is even more restrictive. It allows the developer to copy from one linked service to another as long as the source and target are both binary data types.
Why is this restriction so? Binary files are governed by the source systems that generate them. A thirty-two bit Visual C++ program will store a floating point number differently than a sixty four bit python program. The same number written to a file might have a different representation. The Binary connector for ADF does not allow the developer to know the internals of a given files. It just guarantees that the data, byte by byte is copied from the source connection to the destination connection.
The image below shows the definition of the data set named DS_ADLS2_FILE_TYPE_BINARY for the linked service named LS_ADLS2_DATALAKE_STORAGE

Like before, we need to parameterize the directory path and file name for the data set to be truly dynamic.

Before saving the data set, please make sure you modify the connection properties to use the newly created parameters.

The image below shows that the validation of a sample pipeline fails when we try to read from Azure SQL Server and write to Azure Data Lake Storage using a binary format.

That was a lot of work, to give you the reader, a complete background on all the data types that can be used with Azure Data Lake Storage. The EXCEL, XML and BINARY formats will be excluded from our final pipeline that reads from Azure SQL Server and writes to Azure Data Lake Storage.
If Condition Activity
The “if condition” activity is a control flow object that can be use with ADF pipelines. Today, we are going to revisit the prior pipeline to allow the source location to dynamically be defined by the pipeline parameters. Our first step is to come up with a list of parameters needed by the pipeline program.

The image above shows the parameters that I choose to define. The schema name and table name are used to uniquely identify the source table to copy over from the Adventure Works LT database. The zone name describes the quality zone within the data lake in which the pipeline is writing to. We are depending on the fact that the table name and file name will be the same to simplify and reduce the number of parameters. Also, the zone, schema, and table are used to uniquely define the full path to the file in the data lake. The last three parameters are used to define the characteristics of the file: file type – what is the target data file type; file extension – might change when writing delimited files; and delimiter char – popular characters are comma, tab and pipe.
The image below shows the completed pipeline called PL_COPY_SQL_TABLE_2_ADLS_FILE_V3. This is a very good choice for a name since we are now supporting 5 different target file formats.

Let us talk about how to create the correct “if condition” activity with an inner most copy activity. Once you understand how to write one, the rest of the activities are just repeating of the design pattern using a different target data set. The image below shows the “if condition” activity for the delimited file format named ACT_ITRC_IF_DEL_FILE_FORMAT. Name conventions and descriptions are very important for long term maintenance.

Please enter the following ADF expression for the “if condition” activity for the delimited file format. Simply change the string comparison for each copy activity accordingly.
@equals(toUpper(pipeline().parameters.FILE_TYPE), 'DEL')
The copy command named ACT_MT_IF_TABLE_2_DEL_FILE is the key component. This control performs the actual data copy from Azure SQL Server to Azure Data Lake Storage. There are three settings that most developers forget to set. The timeout for the activity is set to seven days by default. I have chosen to set this value to five minutes. The retry count and retry interval allow you to recover if the first copy command fails. I left this at zero retries since it is a “proof of concept” (POC) framework. In real life, one might choose a setting of three or five retries with a several minutes between copies.

Please configure the source setting of the copy activity by using the following ADF expression. In this POC pipeline, were are assuming that a full table copy is being used every time we move data.
@concat('select * from ', pipeline().parameters.SCHEMA_NM, '.', pipeline().parameters.TABLE_NM)
The image below shows no partitioning (none) being used to copy over the table data. I will visit topic in a follow up article.

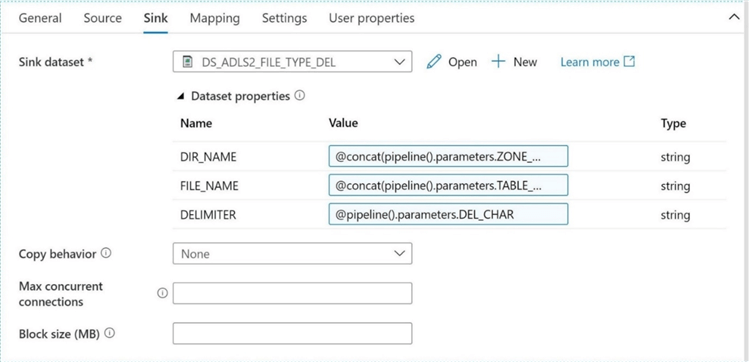
Please configure the target (sink) setting of the copy activity by using the following three ADF expressions for directory name, file name and delimiter character.
@concat(pipeline().parameters.ZONE_NM, '/', pipeline().parameters.SCHEMA_NM, '/', pipeline().parameters.TABLE_NM) @concat(pipeline().parameters.TABLE_NM, '-', replace(replace(substring(utcnow(), 0, 19), '-', ''), ':', ''), '.', pipeline().parameters.FILE_EXT) @pipeline().parameters.DEL_CHAR
The image below shows the completed copy activity. Make sure you publish (save) your work now before you lose it.
Please click the debug button after your finish creating all five “if condition” activities. It is interesting to note that all 5 if conditions must be evaluated which results in some lost processing time. While this is not a lot of time, it can add up if the pipeline program is executed many times.

Switch Activity
The switch activity is part of the control flow objects that can be use with ADF pipelines. Can we use this conditional activity to reduce the wasted computing time see with the “if condition” activity? The image below shows the completed pipeline called PL_COPY_SQL_TABLE_2_ADLS_FILE_V3. Instead of 5 “if condition” activities, we have 1 switch activity.

Please enter the following ADF expression for the switch statement. The only rule to follow is the evaluation of the expression must result in a string.
@toUpper(pipeline().parameters.FILE_TYPE)
There is a default activity that is called if no matches are found. Use the add case button to create an entry for each file type. Please copy over the copy activities from the previous pipelines to their correct place.

Using the debug button, we can test the execution of this new pipeline. Instead of five activities being evaluated, only one switch activity is executed. The longer execution time is caused by the serverless Azure SQL database being awoken from a paused state.

Summary
Azure Data Factory is a simple Extract, Load and Translate program. At its core, the developer needs to define both a source and target data set. The most common activity is the copy command. This allows the developer to move data from one location to another. The number of connectors available in Azure Data Factory make the tool very attractive to data engineers.
Today, we want to expand our previous dynamic pipeline to allow for multiple target file formats. An in-depth exploration of the eight file types supported by Azure Data Lake Storage was required for a good foundation. Only five of the file types can be used as a target within a copy activity. Dynamic parameters were defined for each of the five data sets.
The third version of the pipeline program was designed using the “if condition” activity. Every single condition had to be evaluated before picking the correct copy activity to run. This could result in wasted computing cycles. This type design pattern only makes sense if more than one condition might be executed at the same time. Regardless of a little overhead, the program now dynamically supports five target file formats.
The fourth version of the pipeline program was designed using the switch activity. Only one condition had to be evaluated before picking the correct copy activity to run. This may save you Default Integration Runtime computing power. This activity also supports a default condition. This is a great place to log the fact that the developer passed an invalid parameter which resulted in no copy action being performed.
The last action is to create a scheduling pipeline to save all Adventure Works tables to the Raw Zone of Azure Data Lake Storage. I will leave this task for you to complete. Unlike before, we have five different target file formats to choose from. We can see that the number of parameters will increase as the functionality of the program increases. Therefore, in the future we will have to use a more complex data type to pass the parameters.
Today was our second adventure in advanced ADF programming. Please stay tuned for more exciting articles to come this summer. Enclosed is Azure Resource Management (ARM) template export of all the Azure Data Factory objects that were created today.
Next Steps
- How to create parquet files when using the self-hosted integration runtime.
- Partitioning source data tables for faster transfer times.
- Preventing schema drift with the tabular translator mapping.
- Custom execution, error, and catalog logging with Azure Data Factory.
- Creating a meta data driven framework for Azure Data Factory
- How to scale parallel processing with Azure Data Factory

John Miner is a Senior Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
He has over thirty years of data processing experience, and his architecture expertise encompasses all phases of the software project life cycle, including design, development, implementation, and maintenance of systems.
His credentials include undergraduate and graduate degrees in Computer Science from the University of Rhode Island. Also, he has earned certificates from Microsoft for Database Administration (MCDBA), System Administration (MCSA), Data Management & Analytics (MCSE), Data Science (MPP), Databricks Certified, and Fabric Certified.
John has been recognized with the Microsoft MVP award nine times for his outstanding contributions to the Data Platform community.
When he is not busy talking to local user groups or writing blog entries on new technology, he spends time with his wife and daughter enjoying outdoor activities. Some of John’s hobbies include wood working projects, crafting a good beer and playing a game of chess.
- MSSQLTips Awards: Author of the Year – 2019, 2022, 2023 | Champion (100+tips) – 2023


Good example. Thanks