By: Aaron Bertrand | Updated: 2022-01-18 | Comments (4) | Related: > Database Configurations
Problem
At Stack Overflow, the upgrade to SQL Server 2019 was not as smooth as expected. It introduced long recovery times and high CPU on a secondary, during synchronization activity after failover, patching, and network connectivity testing. This symptom wasn't present during similar activities and workloads under SQL Server 2017.
Solution
Enabling Accelerated Database Recovery (ADR, which I've also talked about here) was one approach to circumventing the problem. Long story short, though: ADR was not a miracle cure in this specific case; recovery still takes over 20 minutes, with sustained elevated CPU usage throughout.
In an ongoing support case, Microsoft's suggestion has been to throw hardware at the problem – specifically, more CPUs, to allow more worker threads to process redo. They also advised us to limit the number of databases in any Availability Group to 100 which, admittedly, aligns with guidance.
But we're not in a rush to do either of these things, because:
- While it's true that this specific Availability Group has close to 400 databases (much higher than the recommended limit), splitting it up into at least four separate AGs is not practical in the short term. This would be an extremely complex endeavor – due to cross-database dependencies, potential breaking changes, and various assumptions in the codebase.
- It is also unclear how failing over 4 * 100 databases is going to do significantly better than 1 * 400 databases – if anything, I'd expect this to produce more concurrent CPU pressure, which may not improve overall duration at all, unless we also invest in additional CPUs. Investing in additional CPUs on relatively older physical hardware is far from simple, and in addition to the cost of the CPUs themselves and the operational overhead of implementing the upgrade, it will also drive up our licensing costs. This is not an appealing way to potentially (not guaranteed!) slightly reduce (not solve!) a problem that only happens during recovery.
When I came on board in November, I was asked to look at this with fresh eyes. One of the first things I noticed was that most databases had old-style checkpoints, since they had been upgraded from older versions. The original source databases were created long before the SQL Server 2016 change to default new databases to indirect checkpoints (background here).
The change mainly provides more predictable checkpoint activity, really helping to smooth out I/O bursts. I've talked before about checkpoints and why we should all be using indirect checkpoints everywhere – most famously in this blog post.
In addition to the old-style checkpoint settings, I observed these other symptoms (some after enabling an Extended Events session to monitor checkpoint activity):
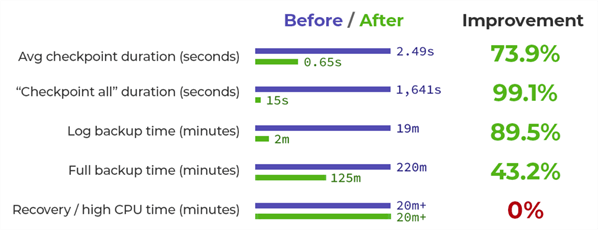
- Long checkpoint times (average 2.5 seconds).
- Infrequent checkpoints for some dbs – in the 30-minute interval before changing the setting, about 20% of the databases were not represented at all.
- A loop to perform a manual checkpoint of all databases – a typical tactic prior to planned maintenance to minimize subsequent recovery times – took 1,001 seconds and then, 5 minutes later, 639 seconds.
- Long full backup times (average ~220 minutes).
- Long log backup times (average ~19 minutes).
Then we applied these changes:
- We performed virtual log file maintenance on several databases, reducing VLFs from ~9,000 to ~4,000 (one log file alone had 2,500, which is way too many).
- We enabled indirect checkpoints on all databases throughout our environment using the script from this post, intentionally spacing the changes out over several days, just in case, to observe any impact. There was none.
After the change, and over a similar observation period, we saw:
- Faster checkpoints (average 0.65 seconds).
- Better distributed checkpoints (every database had at least one in the first 10 minutes).
- A manual loop to checkpoint all databases took 8 seconds; 5 minutes later, it took 7 seconds.
- Faster full backup times (average ~125 minutes).
- Faster log backup times (average ~2 minutes), which exceeded even our most optimistic expectations. Even better, this will allow us to drop our transaction log schedule from 30 minutes to a much more RPO-friendly 5 or 10 minutes.
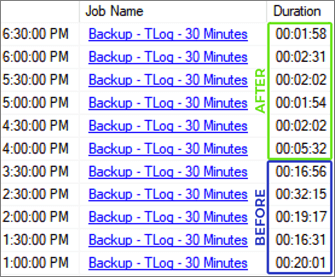
Unfortunately, like ADR, indirect checkpoints did not materialize to be the magic cure we needed, and I was not an instant hero with legendary status in my first month in my new role. The next time we performed a failover, the secondary still took over 20 minutes to recover, with pegged CPU for most of that time. Still, the improvements we did observe were positive, summarized nicely in this visual:
While they didn't solve our most pressing issue, we're still going to proceed with indirect checkpoints everywhere, and Accelerated Database Recovery by default, and staying on top of VLFs, since these are all positive changes that contribute to better performance and stability in various ways. I invite you to adopt the same philosophy – especially for indirect checkpoints, provided you are using a relatively modern I/O subsystem (check with your storage team if you're not sure).
And to wax a little more on indirect checkpoints specifically, while Microsoft did a great thing in changing the default for new databases, I wish they would do a better job of promoting this as a change people should proactively make to databases that have been upgraded. Also, I can't stop thinking about the fact that checkpoint configuration didn't come up at any point during the nearly year-long support case, until we brought it up. Maybe they knew it wouldn't help, but we still thought it was worth a try.
Conclusion
These changes are much easier to test and implement than changing your hardware or reconfiguring your Availability Group configuration. At the very least, just switch to indirect checkpoints, everywhere. On your standalone instances, the code is as follows:
DECLARE @sql nvarchar(max) = N''; SELECT @sql += N'
ALTER DATABASE ' + QUOTENAME(d.name)
+ N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
FROM sys.databases AS d
WHERE d.target_recovery_time_in_seconds <> 60
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0; EXEC sys.sp_executesql @sql;
If you are performing this on an Availability Group, though, you'll need to deal with additional scenarios. Most importantly, when the local database is not the primary replica, but also when it is "kind of" the primary replica because it is the "forwarder" in a distributed AG:
DECLARE @sql nvarchar(max) = N''; SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE')
OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name)
+ N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0; EXEC sys.sp_executesql @sql;
(This latter script will work just fine on standalone instances too.)
If you can't fix the checkpoint mechanism due to change control, doubt, or fear, but are having issues with high CPU / long recovery after failovers or other outages, you could at least checkpoint all of the old-style databases immediately prior to planned failovers:
DECLARE @sql nvarchar(max) = N'CHECKPOINT;',
@cur cursor,
@exec nvarchar(2000); SET @cur = CURSOR FORWARD_ONLY STATIC READ_ONLY
FOR SELECT QUOTENAME(name) + N'.sys.sp_executesql'
FROM sys.databases AS d
WHERE d.target_recovery_time_in_seconds <> 60
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0; OPEN @cur; FETCH NEXT FROM @cur INTO @exec; WHILE @@FETCH_STATUS = 0 BEGIN
EXEC @exec @sql;
FETCH NEXT FROM @cur INTO @exec;
END
This should minimize the amount of reconciliation that has to happen on the other end of the event.
Next Steps
Change all of your databases to indirect checkpoints. You should see trickle-down effects like faster log and full backups, even if they don't resolve any issues you're observing after failovers. And if you experience any negative effects, I'd love to hear about them below, but this is not a very risky change because it's so easy to switch back.
If you can't change the databases just yet, change your failover procedures to include a step that manually checkpoints all databases that are still using the old style (you might want to do this anyway).
See these tips and other checkpoint resources:
- Indirect Checkpoints in SQL Server 2012
- SQL Server Checkpoint Monitoring with Extended Events
- "0 to 60" : Switching to indirect checkpoints
- Change the Target Recovery Time of a Database (SQL Server)
- SQL 2016 - It Just Runs Faster: Indirect Checkpoint Default
- How we made backups faster with SQL Server 2017






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-01-18
