By: Aaron Bertrand | Updated: 2022-11-02 | Comments (2) | Related: 1 | 2 | 3 | More > Database Administration
Problem
We all have one: the table that grows forever. Maybe it contains chat messages, post comments, or simple web traffic. Eventually, the table gets large enough that it becomes problematic – for example, users will notice that searches or updates take longer and longer as this massive, ever-growing table is scanned.
People often deal with this by archiving older data into a separate table. In this tip series, I'll describe an archive table, explain why that solution carries its own set of problems, and show other potential ways to deal with data that grows indefinitely.
Solution
Sometimes, when a table grows faster than expected, it fills the allocated disk, becoming an emergency that must be addressed immediately. Let's pretend we have an Orders table, and it has filled the Disk A; the knee-jerk reaction is to add a disk (Disk B), add new files to the initial filegroup, and let new data spill into those new files, as illustrated here:
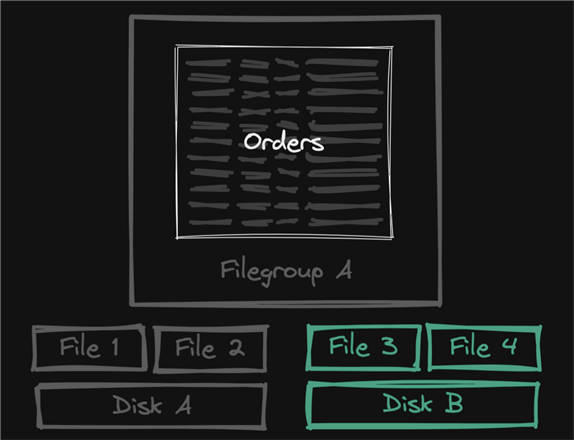
Throwing disk at the problem in this simple way doesn't help retention efforts because the table continues to grow unchecked. In fact, I would argue that spreading the entire table across even more files and more disks will make it harder to clean up later.
Imagine if, when you filled your junk drawer, you never tried to organize it, but rather just displaced everything in another drawer and made that your second junk drawer.
For some, it may be possible to simply delete old data to make room for new data; let's say if you have a finite retention period and a lot of your old data falls outside. Most businesses increase volume over time, so unless you're saving a constant amount of data (like time-based sensor reading for a never-changing number of sensors), you won't be able to keep up as time goes on. For example, if you must keep 5 years of data, is it really the case that a month of 2017 data is the same size as a month of 2022 data? Or is a month today represented by a lot more data than it used to be?
The solution many will resort to is an archive table.
What is an archive table?
An archive table is a separate table with a similar schema where you offload older data. The primary goal is to prevent the main table – the one that users and bulk import processes continue to interact with constantly – from getting too big and slowing everybody down. Sometimes it's on slower storage, sometimes it has more aggressive compression, sometimes it has completely different indexes – both to further reduce space requirements and, also, to support a narrower workload.
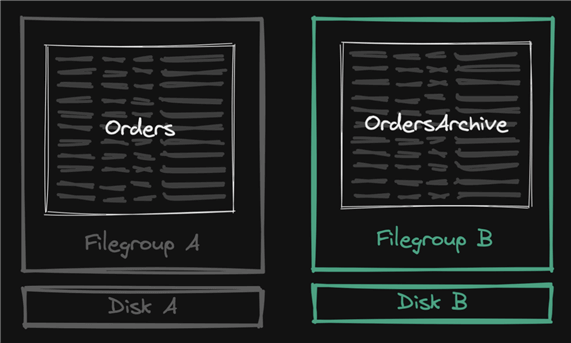
As you start to clean up older data, though, you'll quickly realize it isn't so easy – deleting large chunks of old data causes blocking, especially if there are multiple indexes, and has major impacts from triggers and to anything that uses the transaction log – think availability groups, change tracking, change data capture, replication… and the impacts some of those have on downstream replicas. Throughout this series, I'm going to refer to this collection of effects as simply "log impact."
Even in the simplest case, look at how much log is generated for a single row as it moves through the system. First, it is inserted (the first log write), then when it has reached archive age, it is copied to the archive table (that's two writes), then deleted from the original table (that's three log writes), then eventually it also gets deleted from the archive table (the fourth log write).
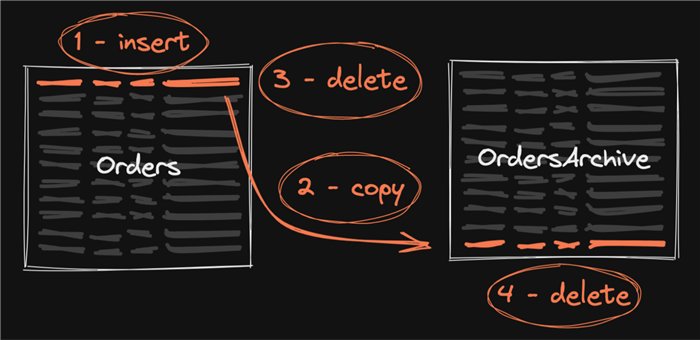
Multiply that by the number of non-clustered indexes, persisted computed columns, LOB columns, how big that LOB data is, writes from triggers, indexed views, writes from triggers, and everything else that has log impact. And the more you're writing at each step in that process, the more blocking you're going to cause for consumers of one or both tables.
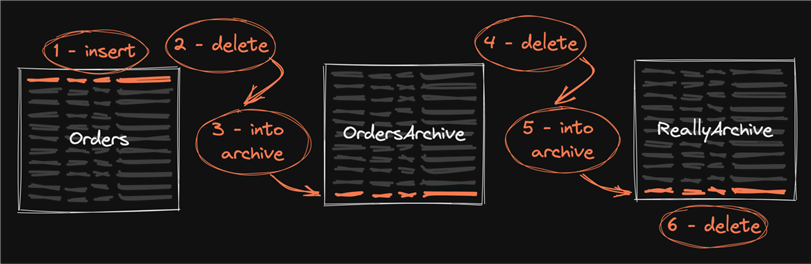
Sometimes folks have an additional layer, maybe with more compression and/or slower, cheaper storage for the really old data, which adds more writes:
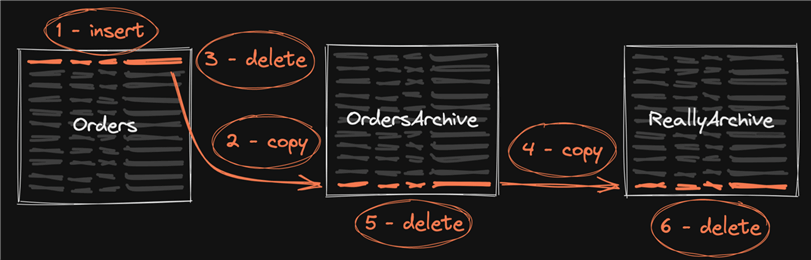
Sometimes it is tightened up a bit, by combining the insert and delete operations into a single statement using OUTPUT INTO:
But often I see some tempdb flogging brought into the mix by using the OUTPUT clause to DELETE … OUTPUT INTO @t and then insert from @t into the destination. For any row there could be a total of 8 writes (multiplied by all the other factors mentioned above):
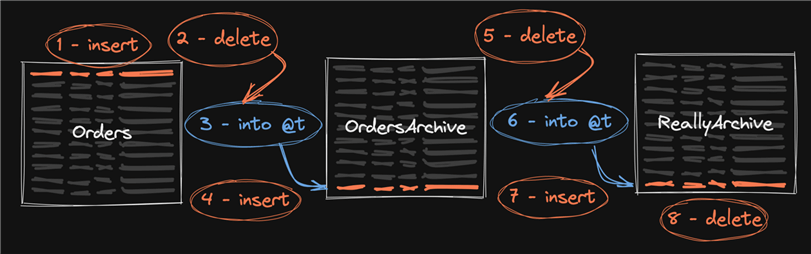
Again, this is over the lifetime of a row, so these writes could be happening months or years apart. Still, every write you perform has a cost, and you have to multiply all of that by your scale. If you are currently generating a million rows per day, one day of data will eventually cause up to 8 million log writes. This revolving door and never-ending shell game may reduce your overall disk space requirements a little, but it will eventually catch up with you in all the other ways outlined above – mainly log impact.
In upcoming tips in this series, I'll talk about a few ways to handle future growth, minimizing log impact while not painting yourself into a corner.
Next Steps
- If you have tables that are only getting larger, start thinking about how you will eventually deal with this – before you have to.
- See these tips and other resources:






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-11-02
