By: Greg Robidoux | Comments (11) | Related: 1 | 2 | 3 | 4 | 5 | 6 | > Partitioning
Problem
With the increasing use of SQL Server to handle all aspects of the organization as well as the increased use of storing more and more data in your databases there comes a time when tables get so large it is very difficult to perform maintenance tasks or the time to perform these maintenance tasks is just not available. In the past, one way of getting around this issue was to partition very large tables into smaller tables and then use views to handle the data manipulation. With SQL Server 2005 a new feature was added that handles this data partitioning for you automatically, so the ability to create and manipulate data in partitioned tables is much simpler.
Solution
In SQL Server 2005 a new feature called data partitioning was introduced that offers built-in data partitioning that handles the movement of data to specific underlying objects while presenting you with only one object to manage from the database layer. The picture below shows how a table may look when it is partitioned. To the DBA and to the end user it looks like there is only one table, but based on the partition scheme the underling data will be stored in a different partitions and not in one large table. This makes all of the existing code you have in place work without any changes and you get the advantage of having smaller objects to manage and maintain.
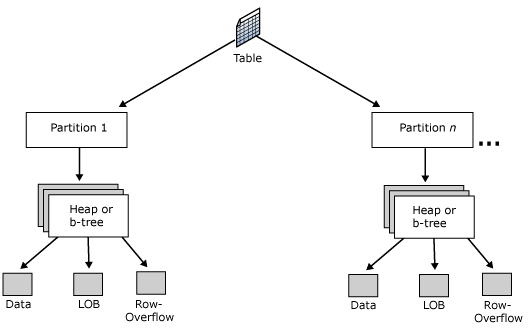
(source: SQL Server books online)
Creating a Partitioned Table
To create a partitioned table there are a few steps that need to be done:
- Create additional filegroups if you want to spread the partition over multiple filegroups.
- Create a Partition Function
- Create a Partition Scheme
- Create the table using the Partition Scheme
Step 1 - Create Additional Filegroups
For this example, I have created four filegroups flg1, flg2, flg3 and flg4.
This is step is not mandatory, you can still use just one filegroup even if you partition the data, but one of the advantages of partitioning a table is to spread the data over multiple filegroups to get better IO throughput.
Step 2 - Create Partition Function
This creates a range of values for the partition. This will create four partitions:- values <= 10,000
- values > 10,000 and <= 100,000
- values > 100,000 and <= 1,000,000
- values > then 1,000,000
CREATE PARTITION FUNCTION partRange1 (int) AS RANGE LEFT FOR VALUES (10000, 100000, 1000000); GO
Step 3 - Create Partition Scheme
This creates the partition scheme to determine where each of the partitions will reside. In this example we are spreading it over four filegroups:- values <= 10,000 (flg1)
- values > 10,000 and <= 100,000 (flg2)
- values > 100,000 and <= 1,000,000 (flg3)
- values > then 1,000,000 (flg4)
CREATE PARTITION SCHEME partScheme1 AS PARTITION partRange1 TO ( flg1, flg2, flg3, flg4 ); GO
Step 4 - Create Table Using Partition Scheme
This creates the table using the partition scheme partScheme1 that was created in step 2. The column col1 is used to determine what data gets placed in which partition/filegroup.
CREATE TABLE partTable (col1 int, col2 char(10)) ON partScheme1 (col1); GO
Adding Data to Partitioned Table
After the table has been setup as a partitioned table, when you enter data into the table SQL Server will handle the placement of the data into the correct partition automatically for you.
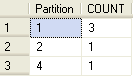
So, based on the above setup if we run the below commands the data will be placed in the appropriate partition as shown below.
-- data will go to partition 1 on filegroup flg1 INSERT INTO partTable (col1, col2) VALUES (25, 'Test1') -- data will go to partition 1 on filegroup flg1 INSERT INTO partTable (col1, col2) VALUES (1234, 'Test1') -- data will go to partition 2 on filegroup flg2 INSERT INTO partTable (col1, col2) VALUES (10243, 'Test1') -- data will go to partition 4 on filegroup flg4 INSERT INTO partTable (col1, col2) VALUES (25000000, 'Test1') -- data will go to partition 1 on filegroup flg1 INSERT INTO partTable (col1, col2) VALUES (-2523, 'Test1')
To determine what exists in each partition you can run the following command:
SELECT $PARTITION.partRange1(col1) AS Partition, COUNT(*) AS [COUNT] FROM dbo.partTable GROUP BY $PARTITION.partRange1(col1) ORDER BY Partition ;
Here is the result from running the above query on our simple test of record inserts.
In addition to determining the number of rows that are in each of the partitions we can also see how fragmented each of these partitions are. By using the DMV sys.dm_db_index_physical_stats we can get this information
SELECT object_id, partition_number, avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats (DB_ID(),OBJECT_ID(N'dbo.partTable'), NULL , NULL, NULL);
Based on this results from sys.dm_db_index_physical_stats, you can rebuild an index for a particular partition. Here is an example of the code that could be used to rebuild index IX_COL1 only on partition #4.
ALTER INDEX IX_COL1 ON dbo.PartTable REBUILD Partition = 4; GO
As you can see this is a great enhancement to SQL Server. The only downside is that it only exists in the Enterprise and Developer editions.
Next Steps
- Take a closer look at this new feature on books online
- Also take a look at this white paper Partitioned Tables and Indexes in SQL Server






About the author
 Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.
Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
