Problem
I want to delete historical data from an old partition in my SQL Server database. How can I achieve this without having downtime?
Solution
As the business grows over a period of time, it is mandatory to archive or purge unwanted historical data. The classical delete command on the partitioned table will fill up the database transaction log quickly and it may take a very long time to complete the task. In this tip, I will walkthrough a method to purge data using partition switching. This methodology is also known as “Sliding Partitioning”.
SQL Server Partition Switching
Partition switching will allow you to move a partition between source and target tables very quickly. As this is a metadata-only operation, no data movement will happen during the switching. Hence this is extremely fast. Using this methodology, the old data can be switched to a work (Staging) table and then the data in the work table can be archived and purged.
In sliding window methodology, we don’t create new files/file group when we create new partition. We purge/archive an old partition and we reuse that partition to receive new data. Hence in a repeated/circular method, we try to use the same data files/filegroups again and again.
Partition Switching Points to Consider
The following criteria must be met for partition switching:
- The target table must be empty
- Source and target tables must have identical columns and indexes
- Both the source and target table must use the same column as the partition column
- Both the source and target tables must be in the same filegroup
If you try to switch the partition without satisfying any of the criteria, the SQL Server will throw an exception and will provide a detailed error message.
SQL Server Partition Switching Syntax
Partition switching can be accomplished by using the "ALTER TABLE SWITCH" statement.
Sliding Window Partition Steps in SQL Server
There are 5 steps to implement in the Sliding Window Partition:
- Step1: Switching partition between main and work table
- Step2: Purge or archive data from the work table
- Step3: Prepare the filegroup to accept new boundaries
- Step4: Split the right most partition based on a new boundary
- Step5: Merge the old partition with the new boundary
Example Solution
In this example, I have created an Orders table with order date as the partition column.
This table will be created with 3 partitions to accept data on a monthly basis. Initially partition one will accept data until November 30, 2017 and the second partition will accept data between Dec 1, 2017 and Dec 31, 2017. The last empty partition will accept data from Jan 1, 2018 onwards.
The below script will create physical data files, file groups, partition scheme, partition function and the Order table. Also, this script will load sample data for a few months.
USE [master]
GO
--Drop if the DB already exists
If exists(Select name from sys.databases where name = 'Staging_TST')
Begin
Drop database Staging_TST
End
Go
--Create the DB
CREATE DATABASE [Staging_TST]
CONTAINMENT = NONE
ON PRIMARY ( NAME = N'Staging_TST', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.SQL2012\MSSQL\DATA\Staging_TST.mdf' , SIZE = 28672KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB )
LOG ON ( NAME = N'Staging_TST_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL11.SQL2012\MSSQL\DATA\Staging_TST_log.ldf' , SIZE = 470144KB , MAXSIZE = 2048GB , FILEGROWTH = 10%)
go
--Remove physical database files for 3 partitioning
If (Exists(Select name from sys.database_files where name='Staging_TST_01'))
Begin
Alter Database Staging_TST
Remove file Staging_TST_01
End
Go
If (Exists(Select name from sys.database_files where name='Staging_TST_02'))
Begin
Alter Database Staging_TST
Remove file Staging_TST_02
End
Go
If (Exists(Select name from sys.database_files where name='Staging_TST_03'))
Begin
Alter Database Staging_TST
Remove file Staging_TST_03
End
Go
----Remove file groups for 3 partitioning
If (Exists(Select name from sys.filegroups where name='Staging_TSTFG_01'))
Begin
Alter Database Staging_TST
Remove Filegroup Staging_TSTFG_01
End
Go
If (Exists(Select name from sys.filegroups where name='Staging_TSTFG_02'))
Begin
Alter Database Staging_TST
Remove Filegroup Staging_TSTFG_02
End
Go
If (Exists(Select name from sys.filegroups where name='Staging_TSTFG_03'))
Begin
Alter Database Staging_TST
Remove Filegroup Staging_TSTFG_03
End
Go
Use Master
go
--Create FileGroups for partitioning
ALTER DATABASE Staging_TST
ADD FILEGROUP Staging_TSTFG_01
GO
ALTER DATABASE Staging_TST
ADD FILE
(
NAME = [Staging_TST_01],
FILENAME = --'K:\Program Files\Microsoft SQL Server\MSSQL11.SIR\MSSQL\Data\Staging\Staging_TST_01.ndf',
'C:\Program Files\Microsoft SQL Server\MSSQL11.SQL2012\MSSQL\DATA\Staging\Staging_TST_01.ndf',
SIZE = 5242880 KB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 5242880 KB
) TO FILEGROUP Staging_TSTFG_01
GO
ALTER DATABASE Staging_TST
ADD FILEGROUP Staging_TSTFG_02
GO
ALTER DATABASE Staging_TST
ADD FILE
(
NAME = [Staging_TST_02],
FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL11.SQL2012\MSSQL\DATA\Staging\Staging_TST_02.ndf',
SIZE = 5242880 KB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 5242880 KB
) TO FILEGROUP Staging_TSTFG_02
GO
ALTER DATABASE Staging_TST
ADD FILEGROUP Staging_TSTFG_03
GO
ALTER DATABASE Staging_TST
ADD FILE
(
NAME = [Staging_TST_03],
FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL11.SQL2012\MSSQL\DATA\Staging\Staging_TST_03.ndf',
SIZE = 5242880 KB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 5242880 KB
) TO FILEGROUP Staging_TSTFG_03
GO
Use Staging_TST
go
CREATE PARTITION FUNCTION OrderPartitionFunction (Datetime)
AS RANGE LEFT FOR VALUES ('20171201', '20180101');
GO
CREATE PARTITION SCHEME OrderPartitionScheme
AS PARTITION OrderPartitionFunction
TO (Staging_TSTFG_01,Staging_TSTFG_02,Staging_TSTFG_03);
GO
--Creating Orders table
CREATE TABLE Orders (
OrderID INT IDENTITY NOT NULL,
OrderDate DATETIME NOT NULL,
CustomerID INT NOT NULL,
OrderStatus CHAR(1) NOT NULL DEFAULT 'P',
ShippingDate DATETIME
);
Go
ALTER TABLE Orders ADD CONSTRAINT PK_Orders PRIMARY KEY Clustered (OrderID, OrderDate)
ON OrderPartitionScheme (OrderDate);
Go
INSERT INTO [dbo].[Orders]([OrderDate],[CustomerID],[OrderStatus],[ShippingDate])
VALUES(DateAdd(d, ROUND(DateDiff(d, '2017-10-01', '2017-12-31') * RAND(CHECKSUM(NEWID())), 0),DATEADD(second,CHECKSUM(NEWID())%48000, '2017-10-01')),ABS(CHECKSUM(NewId())) % 1000,'P',DateAdd(d, ROUND(DateDiff(d, '2017-10-01', '2017-12-31') * RAND(CHECKSUM(NEWID())), 0),DATEADD(second,CHECKSUM(NEWID())%48000, '2017-10-01')))
GO 1000

Now the order table has been created and test data has been loaded into the partitions. I have prepared a SQL query with the help of a DMV and this will show the details of the newly created partitions.
SELECT
OBJECT_SCHEMA_NAME(pstats.object_id) AS SchemaName
,OBJECT_NAME(pstats.object_id) AS TableName
,ps.name AS PartitionSchemeName
,ds.name AS PartitionFilegroupName
,pf.name AS PartitionFunctionName
,CASE pf.boundary_value_on_right WHEN 0 THEN 'Range Left' ELSE 'Range Right' END AS PartitionFunctionRange
,CASE pf.boundary_value_on_right WHEN 0 THEN 'Upper Boundary' ELSE 'Lower Boundary' END AS PartitionBoundary
,prv.value AS PartitionBoundaryValue
,c.name AS PartitionKey
,CASE
WHEN pf.boundary_value_on_right = 0
THEN c.name + ' > ' + CAST(ISNULL(LAG(prv.value) OVER(PARTITION BY pstats.object_id ORDER BY pstats.object_id, pstats.partition_number), 'Infinity') AS VARCHAR(100)) + ' and ' + c.name + ' <= ' + CAST(ISNULL(prv.value, 'Infinity') AS VARCHAR(100))
ELSE c.name + ' >= ' + CAST(ISNULL(prv.value, 'Infinity') AS VARCHAR(100)) + ' and ' + c.name + ' < ' + CAST(ISNULL(LEAD(prv.value) OVER(PARTITION BY pstats.object_id ORDER BY pstats.object_id, pstats.partition_number), 'Infinity') AS VARCHAR(100))
END AS PartitionRange
,pstats.partition_number AS PartitionNumber
,pstats.row_count AS PartitionRowCount
,p.data_compression_desc AS DataCompression
FROM sys.dm_db_partition_stats AS pstats
INNER JOIN sys.partitions AS p ON pstats.partition_id = p.partition_id
INNER JOIN sys.destination_data_spaces AS dds ON pstats.partition_number = dds.destination_id
INNER JOIN sys.data_spaces AS ds ON dds.data_space_id = ds.data_space_id
INNER JOIN sys.partition_schemes AS ps ON dds.partition_scheme_id = ps.data_space_id
INNER JOIN sys.partition_functions AS pf ON ps.function_id = pf.function_id
INNER JOIN sys.indexes AS i ON pstats.object_id = i.object_id AND pstats.index_id = i.index_id AND dds.partition_scheme_id = i.data_space_id AND i.type <= 1 /* Heap or Clustered Index */
INNER JOIN sys.index_columns AS ic ON i.index_id = ic.index_id AND i.object_id = ic.object_id AND ic.partition_ordinal > 0
INNER JOIN sys.columns AS c ON pstats.object_id = c.object_id AND ic.column_id = c.column_id
LEFT JOIN sys.partition_range_values AS prv ON pf.function_id = prv.function_id AND pstats.partition_number = (CASE pf.boundary_value_on_right WHEN 0 THEN prv.boundary_id ELSE (prv.boundary_id+1) END)
ORDER BY TableName, PartitionNumber;
Go

The above result set confirms that we have created three partitions for the order table and we have loaded data into partition #1 and partition #2.
It is also observed that partition #1 maintains orders with the order date until November 30, 2017. The orders with order date between Dec 1, 2017 and Dec 31, 2017 have been loaded into partition #2. The last partition, #3 is empty.
The above SQL query will be used multiple times to understand the capacity and the performance of multiple partitions. Hence, I have created a simple stored procedure based on the SQL query. This stored procedure can be executed to understand the partition details.
Create procedure dbo.PartitionDetails
as
SELECT
OBJECT_SCHEMA_NAME(pstats.object_id) AS SchemaName
,OBJECT_NAME(pstats.object_id) AS TableName
,ps.name AS PartitionSchemeName
,ds.name AS PartitionFilegroupName
,pf.name AS PartitionFunctionName
,CASE pf.boundary_value_on_right WHEN 0 THEN 'Range Left' ELSE 'Range Right' END AS PartitionFunctionRange
,CASE pf.boundary_value_on_right WHEN 0 THEN 'Upper Boundary' ELSE 'Lower Boundary' END AS PartitionBoundary
,prv.value AS PartitionBoundaryValue
,c.name AS PartitionKey
,CASE
WHEN pf.boundary_value_on_right = 0
THEN c.name + ' > ' + CAST(ISNULL(LAG(prv.value) OVER(PARTITION BY pstats.object_id ORDER BY pstats.object_id, pstats.partition_number), 'Infinity') AS VARCHAR(100)) + ' and ' + c.name + ' <= ' + CAST(ISNULL(prv.value, 'Infinity') AS VARCHAR(100))
ELSE c.name + ' >= ' + CAST(ISNULL(prv.value, 'Infinity') AS VARCHAR(100)) + ' and ' + c.name + ' < ' + CAST(ISNULL(LEAD(prv.value) OVER(PARTITION BY pstats.object_id ORDER BY pstats.object_id, pstats.partition_number), 'Infinity') AS VARCHAR(100))
END AS PartitionRange
,pstats.partition_number AS PartitionNumber
,pstats.row_count AS PartitionRowCount
,p.data_compression_desc AS DataCompression
FROM sys.dm_db_partition_stats AS pstats
INNER JOIN sys.partitions AS p ON pstats.partition_id = p.partition_id
INNER JOIN sys.destination_data_spaces AS dds ON pstats.partition_number = dds.destination_id
INNER JOIN sys.data_spaces AS ds ON dds.data_space_id = ds.data_space_id
INNER JOIN sys.partition_schemes AS ps ON dds.partition_scheme_id = ps.data_space_id
INNER JOIN sys.partition_functions AS pf ON ps.function_id = pf.function_id
INNER JOIN sys.indexes AS i ON pstats.object_id = i.object_id AND pstats.index_id = i.index_id AND dds.partition_scheme_id = i.data_space_id AND i.type <= 1 /* Heap or Clustered Index */
INNER JOIN sys.index_columns AS ic ON i.index_id = ic.index_id AND i.object_id = ic.object_id AND ic.partition_ordinal > 0
INNER JOIN sys.columns AS c ON pstats.object_id = c.object_id AND ic.column_id = c.column_id
LEFT JOIN sys.partition_range_values AS prv ON pf.function_id = prv.function_id AND pstats.partition_number = (CASE pf.boundary_value_on_right WHEN 0 THEN prv.boundary_id ELSE (prv.boundary_id+1) END)
ORDER BY TableName, PartitionNumber;
Go
Execute dbo.PartitionDetails
Go

Step 1 – Partition Switching
Let’s assume that the left most partition (partition number #1) contains unwanted historical data and we would like to purge the data. After the purge we will be reusing the partition to store a new set of data.
As a first step to purge data, we need to switch the left most partition to another work (staging) table. This table needs to be empty while we switch the partition.
This work (staging) table must have the same columns as the main orders table and must have the partition column as order date. In addition, this work table must use the same partition scheme/function.
The below script will create the work table.
--Creating Orders Staging tableCREATE TABLE Orders_Work (
OrderID INT IDENTITY NOT NULL,
OrderDate DATETIME NOT NULL,
CustomerID INT NOT NULL,
OrderStatus CHAR(1) NOT NULL DEFAULT 'P',
ShippingDate DATETIME
);
Go
ALTER TABLE Orders_Work ADD CONSTRAINT PK_Orders_Work PRIMARY KEY Clustered (OrderID, OrderDate)
ON OrderPartitionScheme (OrderDate);
Go
Execute dbo.PartitionDetails
Go
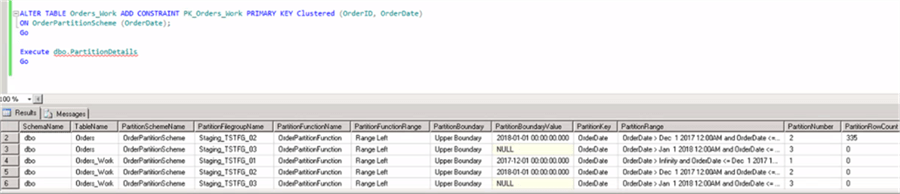
From the image it confirms that the new Orders_Work table has been created using the Orders partition scheme and the Orders partition function.
Now let’s switch partition number #1 from the Orders table to the Orders_Work table. As this is a meta data only operation, this will be done in a relatively short period of time.
After the partition switch, let’s execute the “PartitionDetails” stored procedure to understand the partition details.
ALTER TABLE Orders SWITCH PARTITION 1 TO Orders_Work PARTITION 1
Go
Execute dbo.PartitionDetails
Go
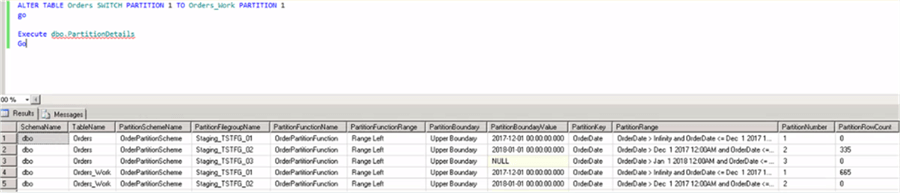
From the above image it is confirmed that the left most partition of the Orders table is empty and the left most partition of the Orders_Work table has the actual data.
Step 2 – Purge data from the Orders_Work table
Now we can safely purge the data in the Orders_Work table using the below script.
Truncate table Orders_Work
Go
Execute dbo.PartitionDetails
Go
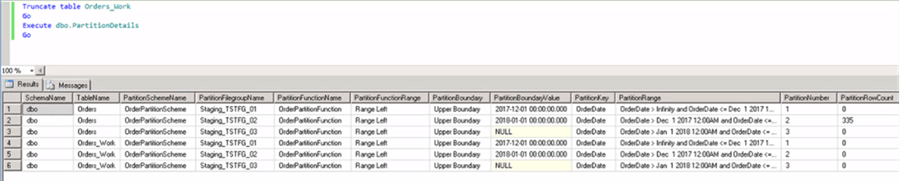
It is confirmed that the data in the Orders_work table has been purged.
Step 3 – Partition Splitting
As a next step, we need to split the partition to accommodate for the new boundary. The "Alter Partition Scheme NEXT USED" SQL statement will help to prepare the filegroup to accommodate the new partition.
The SQL statement "Alter Partition Function SPLIT" will split the partition to accommodate for the new boundary.
Alter Partition Scheme OrderPartitionScheme NEXT USED Staging_TSTFG_01
Go
Execute dbo.PartitionDetails
Go

After the execution of the SQL statements, it is confirmed that a new partition has been created with the new boundary.
Step 4 – Partition Merge
In this final step, we are going to merge the unwanted partition with the new partition. We have already identified the partition with the date range "Infinity to Nov 30, 2017" is redundant and the data has been moved to the Orders_Work table. Hence this partition can be merged with the new partition.
Alter Partition Function OrderPartitionFunction() SPLIT RANGE ('20180201');
Go
Execute dbo.PartitionDetails
Go
Alter Partition Function OrderPartitionFunction() MERGE RANGE ('20171201');
Go
Execute dbo.PartitionDetails
Go
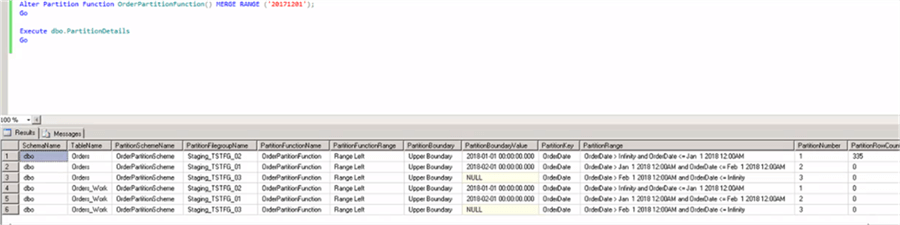
After the execution of the above script, it is confirmed that the old partition has been merged and we can see only three partitions.
It is observed that the previous Filegroup has been reused for the new partition. In the next month, when we execute the script, the current left most partition will be reused as a new partition.
This is how the sliding partition methodology works and this uses the same number of file groups and files. As the partition switching is a meta data only operation, this methodology is ideal for very large tables.
Step 5 – Automate the partition creation
We need to complete the partitioning on a monthly basis, we need a script that can automatically workout the necessary parameters for the new partition. I have enhanced the previously prepared script to make it dynamic and created a stored procedure.
The below stored procedure will accept a boundary date as a parameter and does the partition switching, splitting and merging for the order table.
If Exists(Select Name from sys.procedures where name='CreateNextPartition')
Drop procedure CreateNextPartition
Create procedure dbo.CreateNextPartition (@DtNextBoundary as datetime)
as
Begin
Declare @DtOldestBoundary AS datetime
Declare @strFileGroupToBeUsed AS VARCHAR(100)
Declare @PartitionNumber As int
SELECT @strFileGroupToBeUsed = fg.name, @PartitionNumber = p.partition_number, @DtOldestBoundary = cast(prv.value as datetime) FROM sys.partitions p
INNER JOIN sys.sysobjects tab on tab.id = p.object_id
INNER JOIN sys.allocation_units au ON au.container_id = p.hobt_id
INNER JOIN sys.filegroups fg ON fg.data_space_id = au.data_space_id
INNER JOIN SYS.partition_range_values prv ON prv.boundary_id = p.partition_number
INNER JOIN sys.partition_functions PF ON pf.function_id = prv.function_id
WHERE 1=1
AND pf.name = 'OrderPartitionFunction'
AND tab.name = 'Orders'
AND cast(value as datetime) = (
SELECT MIN(cast(value as datetime)) FROM sys.partitions p
INNER JOIN sys.sysobjects tab on tab.id = p.object_id
INNER JOIN SYS.partition_range_values prv ON prv.boundary_id = p.partition_number
INNER JOIN sys.partition_functions PF ON pf.function_id = prv.function_id
WHERE 1=1
AND pf.name = 'OrderPartitionFunction'
AND tab.name = 'Orders'
)
Select @DtOldestBoundary Oldest_Boundary , @strFileGroupToBeUsed FileGroupToBeUsed,@PartitionNumber PartitionNumber
ALTER TABLE Orders SWITCH PARTITION @PartitionNumber TO Orders_Work PARTITION @PartitionNumber
TRUNCATE TABLE Orders_Work
EXEC('Alter Partition Scheme OrderPartitionScheme NEXT USED '+@strFileGroupToBeUsed)
Alter Partition Function OrderPartitionFunction() SPLIT RANGE (@DtNextBoundary);
Alter Partition Function OrderPartitionFunction() MERGE RANGE (@DtOldestBoundary);
End
Go
Execute CreateNextPartition '20180301'
Go
Execute dbo.PartitionDetails
Go

Once the stored procedure has been created, the stored procedure can be executed with a date parameter to switch the partition to the next boundary.

The above script has created a new partition and reused the old file group. This stored procedure can be automated further to calculate the boundary datetime based on the month end datetime.
Partition Truncation in SQL Server 2016
SQL Server 2016 supports the truncation of a partition, so we can directly purge the partition data. Hence, we don’t need any work/staging table and we can skip the partition switch method.
The partition truncation can be achieved by using the command “Truncate table <TableName> (with Partitions (PartitionNumber)). In our example the first partition data can be truncated using the below command.
Truncate Table Orders with (Partitions(1))
Go
Summary
In this tip, we have learned about sliding window partitioning to effectively reuse old partitions for a new boundary.
Partitioned tables and indexes is now available in all editions of SQL Server starting with SQL Server 2016 SP1.
Next Steps
- Read other SQL Server Partitioning tips here.

Nat Sundar is working as an independent SQL BI consultant in the UK with a Bachelor’s Degree in Engineering. He has considerable years of experience with the UK Financial Services Industry (mainly in Insurance and Investment Banking).
He is passionate about SQL Server, SSIS, SSAS, SSRS and MDX. He has presented at SQLBits, SQLPass and the SQL London User Group. He has special interest towards Continuous Integration, Continuous Delivery and Deployment automation for the SQL BI (SSIS, SSAS and SSRS) stack.
He can be contacted at sqlnat@gmail.com, via LinkedIN and on Twitter at @SQLNat.

Thank you so much for a great article!!!
I’m hoping this process can be adapted to a different use. We have several large tables (> 5B rows) and we need to reprocess smaller subsets of this data (anywhere from 3-5M rows). Essentially all data is active, but when we need to reprocess data, the old data must first be removed. The idea is have and Active and Inactive partition. All data toed into the Active partition by default. When we need to delete data, we would update the partition key to “move” data to the inactive partition. once moved, we proceed with the partition dropping. We’d “chunk” the updates to manage TLog. We have the liberty of using exclusive locks for this operation.
Does this sound reasonable?