Problem
Large databases usually have a negative impact on maintenance time, scalability and query performance. For maintenance, these large single databases have to be backed up daily while the amount of actual changing data might be small. For performance, tables without correct indexes result in full table or clustered index scans. As the data grows the total query time increase linearly. How can we decrease downtime for the maintenance window for large databases and optimize the performance of daily queries?
Solution
Database partitioning is an old technique that divides the table data into buckets or shards using some type of hash or shard key. The reference data, typically known as dimension tables, is replicated across N databases. The event data sometimes referred to as fact tables, is segregated into N databases using the hash key as the key identifier. Index maintenance and backup tasks can be simplified since N-1 databases (shards) are inactive. These databases can be optimized and set to read-only. Many companies deal with a rolling window of data for reporting. For example, if your company keeps two years of data online by quarter, then we have eight database shards. To remove the oldest shard, we use a drop database statement which is extremely quick. If we did not use database partitioning, the delete statement would take a long time and may result in fragmentation.
Business Problem
The goal of Big Jon’s BBQ company is to send out packages of pig parts to members on a monthly basis. Users of the company website have been complaining that responsiveness of the database server has been decreasing over time. Since data older than three months is hardly used, the customer table is a great candidate for database sharding by quarter. The two reference tables will be replicated to each database shard. The rest of the article will focus on how to convert this one large database into several database shards. During this exercise, we will review the benefits and drawbacks of using database partitioning (sharding).
Sandbox Environment
We always want to explore new database designs in a lower environment before moving them to production. The first step is to restore our Big Jon’s Barbeque database from a backup file. For more detailed information on this sample database, please see my article on partitioned views. The current virtual machine named vm4sql22 is a windows 2022 server with the developer version of SQL Server 2022. This is the target system for today’s exploration. For more information on how to restore a backup, please see this Microsoft learn article.
If we right-click the restored database, we can look at the file properties. To prevent ownership issues in the future, it is a best practice to have this restored database owned by [sa]. Just change the owner in the text box and click okay to save the change.
![database sharding - file properties of the database. make sure the owner is [sa].](/wp-content/images-tips/7479_understanding-when-to-use-database-sharding.002.png)
I work with many different clients each year. Many times, the accidental DBA does not realize that compatibility level determines what features are available to the database engine when processing queries. Over the years, the product team makes changes to improve the database engine. Unless you have a good argument, please use the latest compatibility level.
One such argument is that the third-party vendor might not certify their software on the latest version. This can be easily solved by asking when will the software be certified for the newest version. Then plan to upgrade both the software and database at that time.

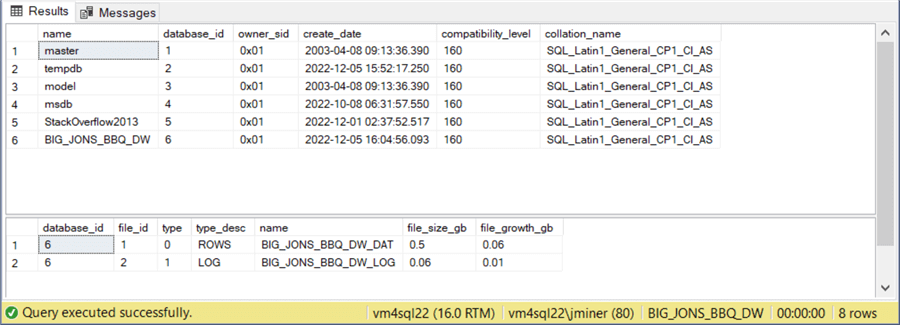
Since I made some changes to the database, let’s look at two queries that can verify our work. The query named S1 below returns a small set of fields about the database. We are interested in both the owner and compatibility level of the database.
-- -- Query S1 - database properties -- select name, database_id, owner_sid, create_date, compatibility_level, collation_name from sys.databases; go
The second query named S2 just looks at the file size and file growth for each database file.
-- -- query S2 - database file size -- select database_id, file_id, type, type_desc, name, round(((cast(size as float)*8)/1024/1024), 2) as file_size_gb, round(((cast(growth as float)*8)/1024/1024), 2) as file_growth_gb from sys.master_files where database_id = 6; go
The image below shows information about the BIG_JONS_BBQ_DW database. We can see that both property changes to the database have been performed.
Technical Overview
What is the purpose of database sharding? The main idea is to reduce maintenance and increase performance for an extremely large database. This can be achieved by picking a hash key such as year and quarter (YYYYQQQ). Then, dynamically create a new database for each hash value. Tables that are considered reference, are copied over in full. Tables that are being sharded are copied by matching hash key. The diagram below shows the logical implementation of sharding. In short, we are reducing the size of the database by N.
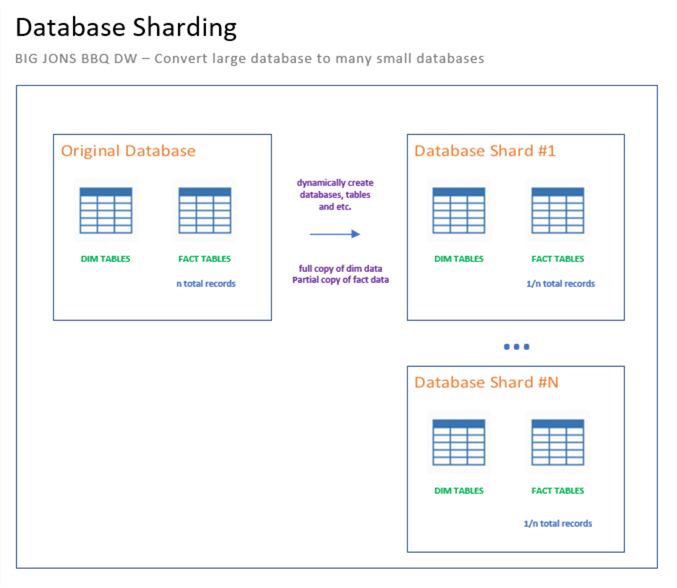
At the end of this article is the script to convert the BIG_JONS_BBQ_DW into 8 database shards. It uses dynamic T-SQL to create the new databases with the required schema. Is there a quicker way to dynamically create the schema over and over again without using dynamic T-SQL?
Yes, if you are willing to dedicate a local SQL Server instance to your application, you can create the database schema within the model database. This database is a template for any new databases. Any schema objects deployed to this database will be copied to any new database. This does not apply to Azure SQL database since we do not have access to the model database in the cloud service.
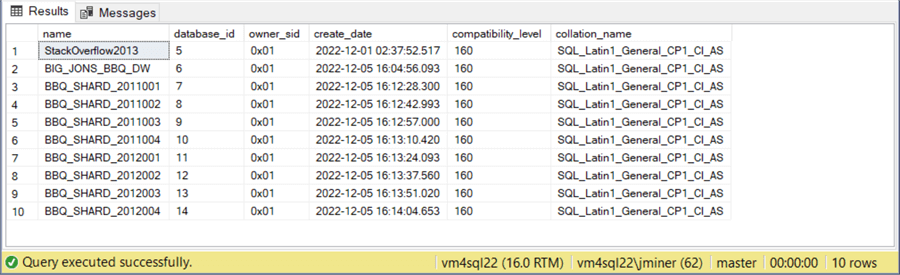
The image below shows that the two years of customer data from the original database has been moved to 8 separate databases.
Like any software technique, there are pros and cons for a given design. The table shown below goes over topics that you should consider when implementing database sharding. As long as the PROs outweigh the CONs for your company, database sharding might be a good fit.
| Category | Action | Description |
|---|---|---|
| PRO | SELECT / INSERT / UPDATE | Actions are performed on a smaller database. |
| PRO | DELETE | This is a drop database action. |
| PRO | MAINTENANCE | Only active databases need constant care. |
| CON | AGGREGATION | Need to query multiple databases. |
| CON | APPLICATION | Must know which shard to connect to. |
Testing SELECT Timings
How do we know that the query performance of the new database shards is quicker than the whole database? The best way is to execute queries, look at the execution plans and collect timings. The query below gets records counts by quarter hash key.
-- -- Query A1 -- SELECT c.cus_qtr_key, count(*) as cus_total FROM [FACT].[CUSTOMERS] c GROUP BY c.cus_qtr_key ORDER BY c.cus_qtr_key;
If we execute this query against the original data mart, we have to traverse one million rows to calculate record counts by hash key. This query takes 40 seconds to complete. I want to point out that the processing has been slowed down by a calculated column that defines the hash key. The reason behind this choice is to work with execution times in seconds, not fractions of a second.
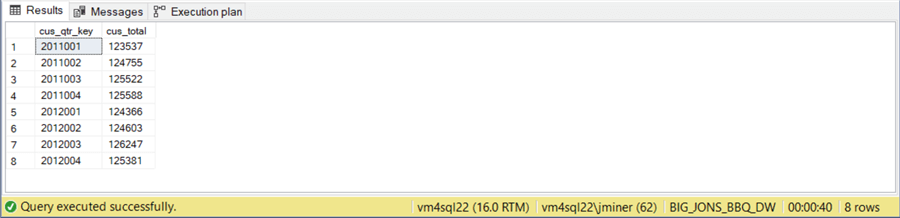
If we take a look at the execution plan, we can see a clustered index scan.
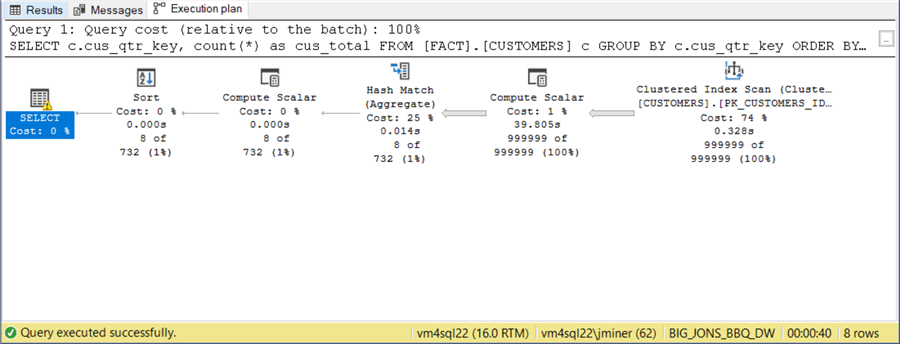
If we execute this query against the first database shard, we can see about 125 thousand records are traversed. The execution time is exactly 1/8 the original time. Thus, we have reduced the query time linearly given the number of partitions.

If we take a look at the query plan, the same clustered index scan is used to find our results.
Another sample query is to find out the number of pig packages sold for a given time period.
-- -- Query A2 -- SELECT c.cus_qtr_key, c.cus_package_key, count(*) as cus_total FROM [FACT].[CUSTOMERS] c GROUP BY c.cus_qtr_key, c.cus_package_key ORDER BY c.cus_qtr_key, c.cus_package_key;
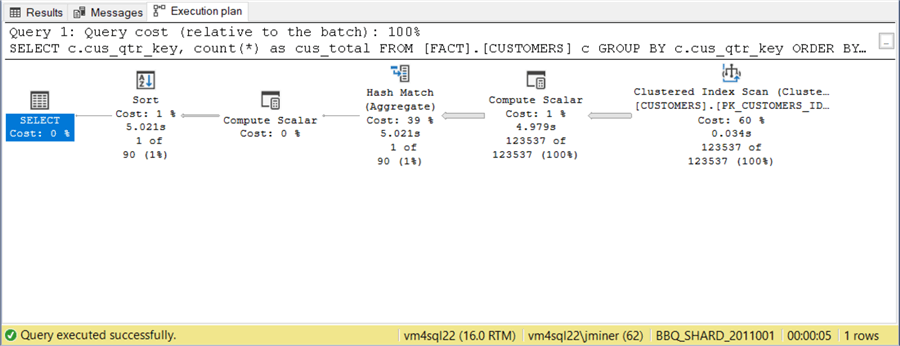
Since the size of the data is constant and the query plan is the same, it is not surprising that the same execution time of 40 seconds is achieved.
The image below shows a similar query plan for the second query.
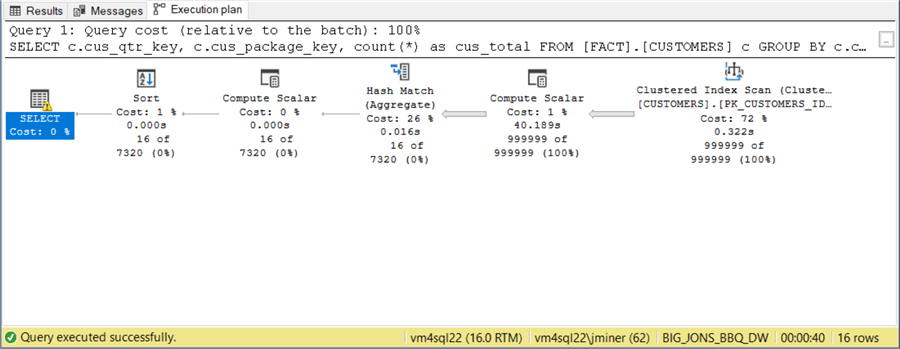
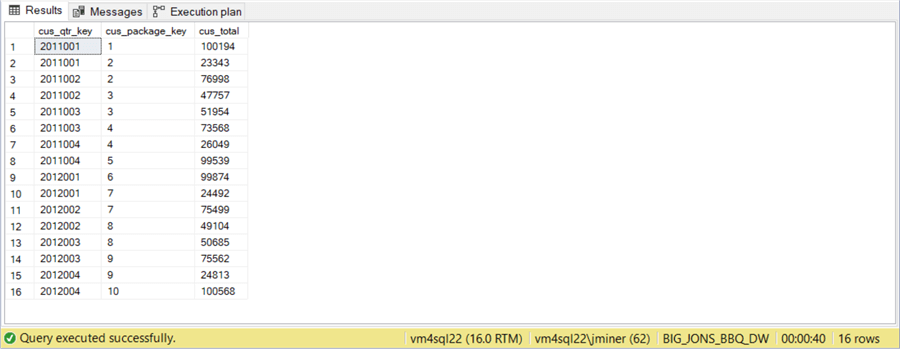
The image below shows that 100 thousand people ordered the first package in the first quarter of 2011. The rest of the people received the second type of pig parts package. This query was executed against the first database shard representing dates with the first quarter of 2011.

Again, a similar plan and execution time is achieved on the smaller database.
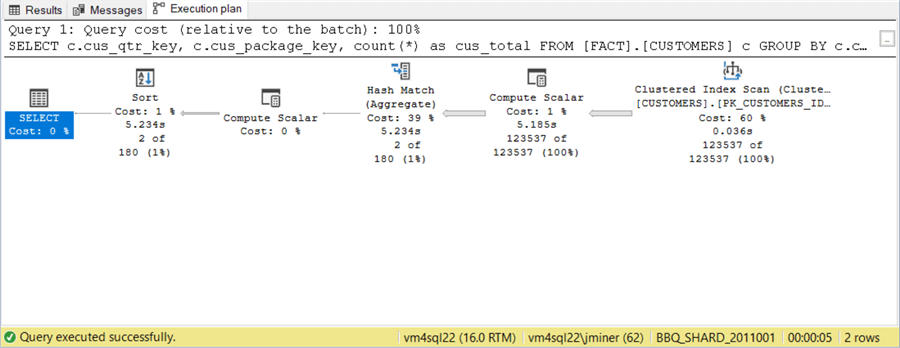
To recap, the execution time of the SELECT query has been reduced linearly in terms of the database shards. Both single INSERT and UPDATE actions regardless of the size of the database should have similar execution times given the DISK speed of the virtual machine. I am assuming these actions use the customer id, which is a clustered primary key, in the WHERE clause.
Testing DELETE queries
Even with reporting systems, business users only want to look at a limited window of data. For instance, year-over-year reporting is very common in many companies. That means we might have to remove data from our large table if we are keeping a rolling 24 months of data.
The query below removes the oldest quarter of data from our original data mart.
-- -- Query A3 -- DELETE FROM [FACT].[CUSTOMERS] WHERE cus_qtr_key = 2011001;
Since we have no way to identify the data that needs to be deleted, we have to perform a table scan. Since the table has a primary key that is clustered, the query optimizer chooses to use a clustered index table scan. If we want a different plan, we need to add a non-clustered index for the hash key. Also, in real life we would convert the calculated column from a dynamic to a persistent value.
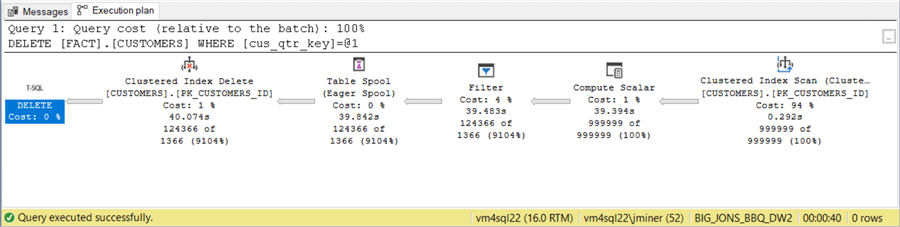
The execution time of any action on the original data mart is the amount of time to traverse all the records or 40 seconds. The nice feature about partitioning is that delete actions are now metadata actions. Thus, removing a quarter of data from the sharded database design is a DROP DATABASE statement.

The above action is so fast that it records as zero seconds to execution. In short, most of our execution times are faster than the original database. But how do we aggregate the data that is now spread across several databases?
Use Views to Combine Data
One way to solve the aggregate problem with database sharding is to create a reporting database. Within this database, we can duplicate static data such as dimensional tables. We can then use a view to UNION all the tables in separate databases. From the report developer’s standpoint, we have the original database. From a database administrator standpoint, we are reducing maintenance. How do aggregated queries perform on the new view?
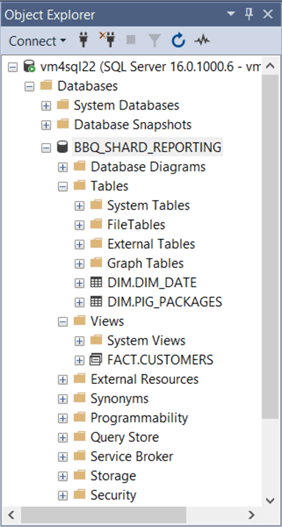
The above image shows the object explorer view of this new database. If we execute the query labeled A2, we can see the execution plan is a serial execution of all 8 queries. Please see the image below for details. The total execution time of the query is one second slower than the query against the original database.
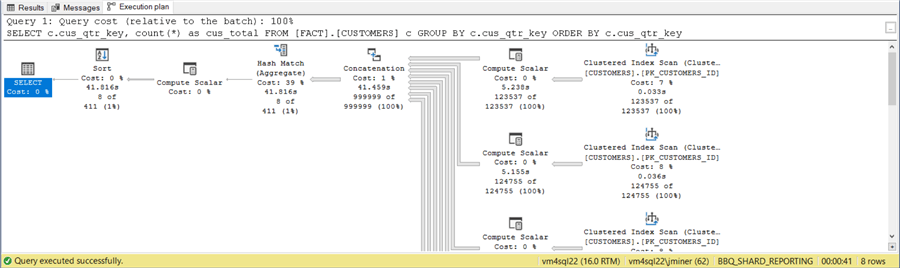
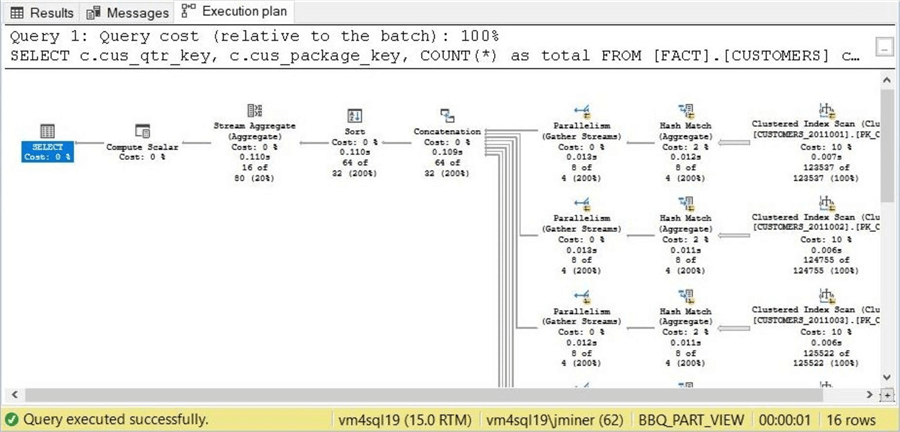
The image below was taken for the partitioned view article. It is using parallelism to execute the queries at the same time.
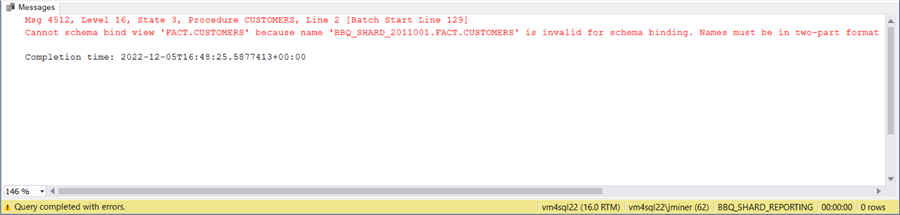
Can we trick the query optimizer into executing the query against our reporting view in parallel by adding the WITH SCHEMABINDING clause? The answer is no. It is looking for a two-dot notation for the table name. See the error we get when modifying the single defined view.
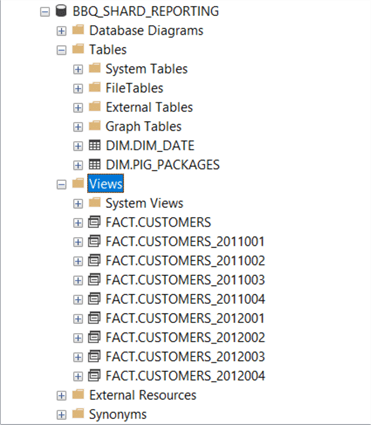
Okay, let’s create 8 local queries that represent the tables in each of the sharded databases. Then one query to combine all the tables using the WITH SCHEMABINDING clause. The image shows the new set of queries.
When we try to alter the view and add the schema binding clause, we get the same error.
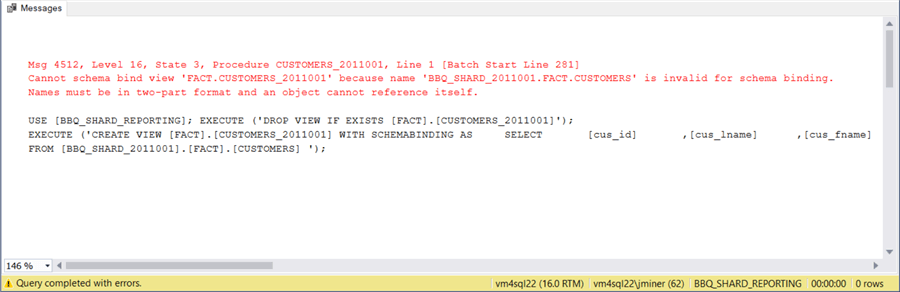
To recap, if you require speedy aggregation of data between database shards, then you might want to look at partition views or table partitioning as a design pattern. These designs will give you the parallel execution of the queries. On other hand, if the queries execute across the database shards are seldomly executed and the queries do not need to be performant, then database sharding might be a good idea.
One use case that comes to mind is Power BI datasets. These datasets might be refreshed once a day. If it takes a couple minutes to update the data, it is not a big deal. Most of the other time the application would be using the most current shard to perform daily work.
Elastic Database Pools
I cannot end this article without introducing Azure Elastic Database Pools.
The cloud services are limited by compute and size. Therefore, it might be required to use database sharding to spread a large database across several Azure SQL Databases. In addition, both geography restrictions and client confidentiality might be two other reasons for database sharding. For instance, we have manufacturing in both Europe and Asia, and there might be country restrictions on keeping the data separate. For software as a service provider (SaaS), the database schema for each client is the same but the data for each client is different. We might use database sharding to keep the data physically separate for confidentiality reasons.
How do elastic database pools come to play in this design?
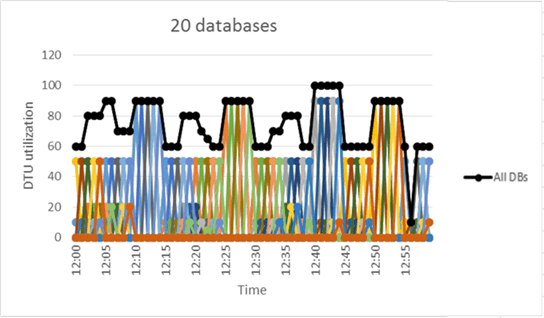
The above image was taken from Microsoft’s learn web page about Azure Elastic Database Pools. If we go back to the Software as a Service (SaaS) provider example, we might have 20 different companies using our software to manage Pig Packages. However, each company is located in different time zones. If the total number of DTU’s is always below 100, we might be able to save money by placing all the databases into one Pool.
There are three other technologies that Microsoft created for Elastic Pools: shard map manager, elastic database jobs, and elastic database queries. Only the first technology has gone to general acceptance (GA) as a product.
Summary
In this article, we reviewed the technique to reduce maintenance and increase query performance. Database sharding duplicates small static tables and spreads out large dynamic tables across multiple databases using a hash key. Since the size of the data is reduced by multiple N, the performance of the queries may increase by a factor of N. The hardest part of database sharding is creating the schema for each new database dynamically. If you are implementing this technique on-premises, consider dedicating an instance to the application. That way the schema can be deployed to the model database and the dynamic code be eliminated.
Database sharding is the easiest partition technique that can be used with SQL Server. However, it does have a drawback with aggregating data across the multiple databases. These queries run in serial, not parallel execution. Products like elastics database queries and elastic database jobs have been created to fill this gap. Unfortunately, they are currently in public preview at this time. In fact, they have been that way for multiple years. Last but not least, if you are a SaaS provider you might want to look at Azure Elastic Database Pools. If you have databases with different usage patterns, this service might be able to save you money.
To complete this article, enclosed are the scripts to create the database shards and query the resulting database.
Next Steps
- Check out this related article on partitioned views.

John Miner is a Senior Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
He has over thirty years of data processing experience, and his architecture expertise encompasses all phases of the software project life cycle, including design, development, implementation, and maintenance of systems.
His credentials include undergraduate and graduate degrees in Computer Science from the University of Rhode Island. Also, he has earned certificates from Microsoft for Database Administration (MCDBA), System Administration (MCSA), Data Management & Analytics (MCSE), Data Science (MPP), Databricks Certified, and Fabric Certified.
John has been recognized with the Microsoft MVP award nine times for his outstanding contributions to the Data Platform community.
When he is not busy talking to local user groups or writing blog entries on new technology, he spends time with his wife and daughter enjoying outdoor activities. Some of John’s hobbies include wood working projects, crafting a good beer and playing a game of chess.
- MSSQLTips Awards: Author of the Year – 2019, 2022, 2023 | Champion (100+tips) – 2023

great thought process. thanks for writing this.