Problem
Sales data in my production database has increased significantly. I am planning to archive this data apart from the production database, so this can still be used for reporting purposes. I am conscious about performance issues while inserting new data to these archive tables and also for report response time. During the planning phase I found out about the new partitioning feature in SQL Server 2005 and later editions of SQL Server. It is a vast topic with several associated operations and configurations involved. In this tip I will share what I learned about partitioning, show an example to implement horizontal table partitioning along with a comprehensive list of related benefits and considerations.
Solution
In SQL Server 2000 and prior there was option for partitioned views, but this had several limitations and there were several things to consider before implementing. With SQL Server 2005 and onwards we now have an option to horizontally partition a table with up to 1000 partitions and the data placement is handled automatically by SQL Server. Horizontal partitioning is the process of dividing the rows of a table in a given number of partitions. The number of columns is the same in each partition.
Although you can have multiple partitions of a horizontally partitioned table on just one filegroup it makes more sense to break these out into separate filegroups, so you can also get some performance benefits. Some of the benefits include an I/O performance boost, because all partitions can reside on different disks. Another reason is the advantage of being able to separately backup a partition through filegroup backups. Also, the SQL Server database engine intelligently determines the partition to be accessed for certain data. And if more than one partition is to be accessed the database engine may use multiple processors in parallel for data retrieval. Such design aspects are very important to get the full advantages of table partitioning.
Before running this script, create the following folders for this example. You can use different folders, but you will need to adjust the scripts below accordingly.
- D:\PartitionDB\FG1
- D:\PartitionDB\FG2
- D:\PartitionDB\FG3
Now run following script to create a new database with three data files on three filegroups.
--Script # 1: Create a table with two data files
USE Master
GO
CREATE DATABASE DBForPartitioning
ON PRIMARY (NAME='DBForPartitioning_1',
FILENAME= 'D:\PartitionDB\FG1\DBForPartitioning_1.mdf',
SIZE=2,
MAXSIZE=100,
FILEGROWTH=1 ),
FILEGROUP FG2 (NAME = 'DBForPartitioning_2',
FILENAME = 'D:\PartitionDB\FG2\DBForPartitioning_2.ndf',
SIZE = 2,
MAXSIZE=100,
FILEGROWTH=1 ),
FILEGROUP FG3 (NAME = 'DBForPartitioning_3',
FILENAME = 'D:\PartitionDB\FG3\DBForPartitioning_3.ndf',
SIZE = 2,
MAXSIZE=100,
FILEGROWTH=1 )
GO
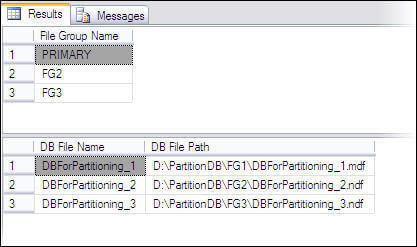
Now we have a database DBForPartitioning with three data files created in three file groups. This may be confirmed using the following script.
--Script # 2: Confirm number of file groups and files in DBForPartitioning
Use DBFOrPartitioning
GO
-- Confirm Filegroups
SELECT name as [File Group Name]
FROM sys.filegroups
WHERE type = 'FG'
GO
-- Confirm Datafiles
SELECT name as [DB File Name],physical_name as [DB File Path]
FROM sys.database_files
WHERE type_desc = 'ROWS'
GO
Broad plan
In a broad plan there are three major steps for implementing horizontal partitioning in SQL Server
- Create a partitioning function. It will have criteria to partition the data in the partitions.
- Create partition schemes to map the created partition function to file groups. It is related to the physical storage of data on disk.
- Create the table by linking it to the partition scheme and also to the partition function. A partition column will be used for this purpose.
At this point before implementation of these three steps we should have a clear idea about the structure of the table that we are going to create with horizontal partitioning. As mentioned earlier we have to implement horizontal partitioning on a table where sales data will be archived. For simplicity we will assume that the structure of our partitioned archival table will be SalesArchival (saleTime dateTime, item varchar(50)). The column on which data will be referred to partitions is called the partition column and it will be used in the partition function as the partition key. The partition column is important and should have the following conditions fulfilled:
- Partition column is always a single column or computed column or persisted computed column by combining more than one columns.
- Any data type that may be used for index key is eligible for partition column except TIMESTAMP data type.
Create partition function
In our example we have sales data for 2007, 2008 and 2009. So here we will create three partitions by providing two partition ranges in our partitioning function. The function will create data boundaries. In our case we are required to place all the data before 2009 in the first partition, data for 2009 will be placed in the second partition and data after 2009 will be placed in the third partition.
--Script # 3: Create partition function
Use DBForPartitioning
GO
CREATE PARTITION FUNCTION salesYearPartitions (datetime)
AS RANGE RIGHT FOR VALUES ( '2009-01-01', '2010-01-01')
GO
The partition key provided in the function is of type that will be the primary key in our partitioned table and partition ranges are based on this column. In our table this column is saleTime with a data type of DATETIME. The range defined may be RIGHT or LEFT. Here we have used a range RIGHT. As a rule of thumb ranges can be translated as
- RIGHT means < or >=
- LEFT can be translated as <= and >.
In our case we have used RIGHT with following values.
| Range RIGHT translation | |
|---|---|
| Record with saleTime | Destination partition |
| < 2009-01-01 | DBForPartitioning_1 |
| >=2009-01-01 and < 2010-01-01 | DBForPartitioning_2 |
| >=2010-01-01 | DBForPartitioning_3 |
If we had used range LEFT then partitioning criteria would be as follows:
| Range LEFT translation | |
|---|---|
| Record with saleTime | Destination partition |
| <= 2009-01-01 | DBForPartitioning_1 |
| >2009-01-01 and <= 2010-01-01 | DBForPartitioning_2 |
| > 2010-01-01 | DBForPartitioning_3 |
As you can see from these two examples there is not a big difference on where the data would reside when using date, but it could be significant based on some other data that may be used.
Create partition scheme
To get optimized file structure, we have already created three file groups for this database and a partition function is created with three partitions defined with certain criteria. Now it is time to link file groups and partition functions. We have to define the physical storage of records partitioned on the basis of ranges defined in the partition function. In our design each partition will go to separate file group. This approach will also allow us achieve benefits of performance for data load or delete operations along with utilization of filegroup backups.
--Script # 4: Create partitioning scheme
Use DBForPartitioning
GO
CREATE PARTITION SCHEME Test_PartitionScheme
AS PARTITION salesYearPartitions
TO ([PRIMARY], FG2, FG3 )
GO
Mapping partitions to filegroups is flexible. Multiple partitions may exist on a single filegroup and single partition may be allotted to a single filegroup.
Create partitioned table
Now we may create a horizontal partitioned table by using the partitioned scheme and partition column. And for performance optimization we will make the SaleTime column the primary key hence a cluster index for this table.
--Script # 5: Create table with horizontal partitioning
Use DBFOrPartitioning
GO
CREATE TABLE SalesArchival
(SaleTime datetime PRIMARY KEY,
ItemName varchar(50))
ON Test_PartitionScheme (SaleTime);
GO
Insert data to check the partitioned table functionality
Now it is time to insert data to verify our required functionality for partitioned table.
--Script # 6: Insert sample in horizontally partitioned table
Use DBFOrPartitioning
GO
INSERT INTO SalesArchival (SaleTime, ItemName)
SELECT '2007-03-25','Item1' UNION ALL
SELECT '2008-10-01','Item2' UNION ALL
SELECT '2009-01-01','Item1' UNION ALL
SELECT '2009-08-09','Item3' UNION ALL
SELECT '2009-12-30','Item2' UNION ALL
SELECT '2010-01-01','Item1' UNION ALL
SELECT '2010-05-24','Item3'
GO
Lastly , we can verify the rows in the different partitions
--Script # 7: Verify data distribution in horizontally partitioned table
Use DBFOrPartitioning
GO
SELECT partition_id, index_id, partition_number, Rows
FROM sys.partitions
WHERE OBJECT_NAME(OBJECT_ID)='SalesArchival'
GO

We have created and verified a horizontal partitioned table for archival. Now data may be loaded in this table by any means.
There are some further considerations that are necessary to keep in mind while implementing horizontal partitioning:.
Considerations while planning
- In a clustered table, partition column should be part of primary key or clustered key.
- By default, indexes created on a partitioned table will also use the same partitioning scheme and partitioning column that is being used by the table
- If data in a partition is not required to be modified that partition may be marked READ ONLY
- Entire table will be locked during an index rebuild operation so you can not rebuild indexes on a single partition with the ONLINE option.
- If you ever require to change partition key then you will be required to recreate the table, reload the data and rebuild the indexes.
- Partition column and partition key both should match in terms of data type, length and precision.
- Only available in Enterprise and Developer editions
- All partitions must reside in the same database
- You can rebuild indexes based on a partition instead of rebuilding the entire index.
Some enhancements for SQL Server 2008
- Data compression can be implemented on specified or all partitions.
- When appropriate use the date data type for a partition column and partition key which can cut down the storage needs and improve performance..
- Lock settings may be implemented at partition level rather than at table level.
Next Steps
- CREATE PARTITION FUNCTION to read further about creating PARTITION FUNCTION
- CREATE PARTITION SCHEME to read further about defining PARTITION SCHEMES
- Instead of backing up whole large table, you may backup only the partition that gets updated after a data load session
- Try to span the partitions on multiple physical disks through multiple filegroups.
- Refer to these other tips about partitioning

Atif Shehzad is a passionate DBA currently serving at Pakistan Revenue Automation Limited (PRAL). His main areas of interest are SQL Server database design, best practices, performance optimization, security/permissions and Reporting Services. He blogs his SQL Server notes on DBDigger. Find him on Twitter and LinkedIn.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2013
