By: Greg Robidoux | Comments (17) | Related: 1 | 2 | 3 | 4 | 5 | 6 | > Partitioning
Problem
One of the challenges of working with large datasets or datasets that become stale is the need to move large chunks of data in and out of your tables. This can be done with large INSERT and DELETE statements or by using views, but with SQL Server 2005 data partitioning makes this task much easier to manage than in previous versions of SQL Server. In this tip we will take a look at how to use the SWITCH operator to move data in and out of partitions.
Solution
In a previous tip, Handling Large Tables with Data Partitioning we looked at how to setup data partitioning in SQL Server 2005, but we did not discuss how to move data in and out of existing partitions. In this tip we will look at a few examples of how to use the SWITCH operator to manipulate data within your partitions.
To begin with let's setup a simple example. The first set of code creates a partition function, partition scheme and then applies the partition scheme to the new table "partTable".
-- create partition function |
Now that this is setup we can run the following command to get a look at how our partition has been setup.
SELECT * |

Now that we have our partitioned table setup, let's insert a few sample rows of data and then select the data to show what is in the table.
-- insert some sample data |
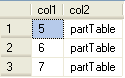
Switch Data In
The first process we will do is to switch data into a partitioned table from another table. Do to this we created a new table called "newPartTable" which has the same schema as our partitioned table, but we also need to create a CHECK constraint on "col1" to match how this data will be loaded into our partition. The data that will be loaded into this table will eventually be going into partition 4 of our partitioned table. So because of this we make sure that our CHECK constraint matches how the partition function was setup. In addition we need to specify that this value can not be NULL. This is all specified in this line below:
col1 INT CHECK (col1 > 30 AND col1 <= 40 AND col1 IS NOT NULL
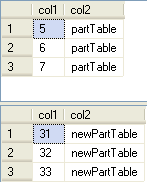
After the table has been created we are inserting some sample records and then just selecting back what was inserted.
-- switch in |
Here we can see we now have data in both partTable and newPartTable.
The next set of commands actually does the switch. We are using the ALTER TABLE command to say take the data in newPartTable and move this data to partition 4 in partTable. The reason we are specifying partition 4 is because of the values we inserted into col1 and these need to match the partition function that was setup in the first setup of this process. After the switch is made we select the data to see that everything has moved from newPartTable to partTable. In addition, although the data has moved the newPartTable still exists. This table did not get absorbed in the process, just the data was moved.
-- make the switch |
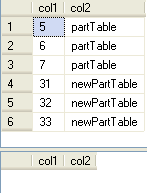
Switching Data Out
On the reverse of the above, there may be the need to move data out of your partitioned table into another table in your database. Let's take a look at how to do this. First we create a new table called "nonPartTable" with the same schema as above. Notice that the columns only have the basis information we do not need to create a CHECK constraint for this process.
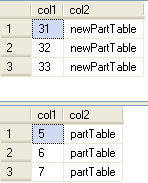
Once the table is created we again use the ALTER TABLE statement to switch the data in partition 1 from "partTable" to the new table "nonPartTable". Data in partition 1 will be any records that have a "col1" value less than 10.
After the move we are selecting the data.
-- switch out |
As you can see we now have data in partTable and data in nonPartTable.
I hope this gives you an idea of how helpful data partitioning can be to move sets of data and maintain large datasets. Although this is very simple on the outside there are several things that need to be thought about before implementing a data partitioning scheme.
Next Steps
- If you have not already explored using Data Partitioning take the time to see if this new feature is something that could be helpful in your environment.
- Keep in mind that Data Partitioning only exists in the Enterprise and Developer editions of SQL Server 2005






About the author
 Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.
Greg Robidoux is the President and founder of Edgewood Solutions, a technology services company delivering services and solutions for Microsoft SQL Server. He is also one of the co-founders of MSSQLTips.com. Greg has been working with SQL Server since 1999, has authored numerous database-related articles, and delivered several presentations related to SQL Server. Before SQL Server, he worked on many data platforms such as DB2, Oracle, Sybase, and Informix.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
