Problem
Partitioning was introduced with SQL 2005 Enterprise Edition, is a godsend for working with very large tables. It provides the means to effectively manage and scale your data at a time when tables are growing exponentially, but maintenance windows are either shrinking or non-existent as with many 24/7 online environments. In this tip I will cover some data partitioning myths and truths you should know about.
Solution
Having worked with large partitioned databases for a few years, I’d like to share some of my lessons learned. Its important to understand what partitioning is and also what it is not.
SQL Server Table and Index Partitioning
Table and index partitioning was an Enterprise only feature in SQL Server 2005 and remained so until SQL Server 2016 prior to SP1. The headaches, maintenance outages, weekend work et al associated with maintaining Very Large Databases can often be eliminated or minimized with a well thought out partitioning scheme.
Note: All the Enterprise features are also in Developer edition, so installing Developer edition on your workstation is a good way to test and play with Enterprise features. Often features that are Enterprise now could be in Standard down the road so you need to keep up to speed as a SQL Server professional.
You can’t restore a database with partitioning to an instance where partitioning is not supported. Important to bear this in mind. Any partition functions and schemes would need to be removed prior to backing up the database and restoring it to an edition that supports partitioning.
Processed 208 pages for database 'myDB', file 'myDB' on file 1. Processed 4 pages for database 'myDB', file 'myDB_log' on file 1. Msg 3167, Level 16, State 1, Line 1 RESTORE could not start database 'myDB'. Msg 3013, Level 16, State 1, Line 1 RESTORE DATABASE is terminating abnormally. Msg 905, Level 21, State 1, Line 1 Database 'myDB' cannot be started in this edition of SQL Server because it contains a partition function 'myRangePF1'. Only Enterprise edition of SQL Server supports partitioning.
Partitioned Views offer similar properties to partitioned tables, but do not require the partitioning feature in SQL Server. Partitioned views was a surprisingly effective but complicated way of ‘partitioning’ data in SQL 2000 and still works just as well in SQL 2005 and later.
Myth 1: Partitioning is a “Scale-Out” solution
Partitions cannot span servers or instances. Partitions have to be in the same instance and in the same database. Partitioning therefore is a scale-up solution. A scale-out solution for SQL Server can be implemented through distributed partitioned views hosted on Federated Database Servers. This is an advanced solution that I have yet to encounter in my career (I would like to hear from anyone who has actually implemented this in a production environment).
Myth 2: Partitions must be created on different filegroups
The partition scheme definition defines on which filegroup a partition resides. It’s a common misconception that you have to spread your partitions out among multiple filegroups. Most code examples seem to use multiple filegroups and I think this is where this myth stems from. The only reason, in my opinion, that you would want multiple filegroups is if those filegroups reside on physically separate drives and you were doing this to improve your I/O for large range queries. I have not seen any performance benefit to having multiple filegroups located on the same drive.
Only split your partitions among multiple filegroups if you have a compelling reason to do so. That reason should be increased performance or manageability.
Myth 3: To partition a non-partitioned table you will need to drop and recreate it
Not true. You can partition an existing table by creating a clustered index (or rebuilding an existing clustered index) on your new Partition Scheme. This will effectively partition your data as the leaf level of a clustered index is essentially the data. The example below creates a partitioned clustered index on a partition scheme PScheme_Day.
CREATE CLUSTERED INDEX idx ON tblPartitioned(SQLCreated) WITH DROP_EXISTING ON PScheme_Day(SQLCreated)
Myth 4: Partitioning an existing table is a strictly offline operation
It’s true that rebuilding or creating a clustered index is indeed an offline operation. Your table will not be available for querying during this operation. However, partitioning is an Enterprise feature, so we have the online index rebuild feature available to use. The ONLINE = ON option allows us to still query the table while under the covers the partitioning operation is going on. SQL Server does this by using an internal snapshot of the data. Obviously, there is a performance hit and I don’t recommend you do this during a busy time but if you have a requirement for 24×7 availability then this is a possible solution.
CREATE CLUSTERED INDEX idx ON tblPartitioned(SQLCreated) WITH (DROP_EXISTING = ON, ONLINE = ON) ON PScheme_Day(SQLCreated)
Myth 5: SWITCH’ing partitions OUT or IN in only a few seconds
You’ll often read that that the reason partitioning operations like SWITCH IN and SWITCH OUT are so fast and efficient is that they are “metadata” only operations meaning that there is no actual data movement but only the pointers or internal references to the data get changed.
SWITCH’ing partitions OUT or IN is a truly “meta data” operation in that although the partitioned data has magically moved from the partitioned table to the SWITCH table or vice versa there hasn’t actually been any movement of data on the disk or inside the data file. However, in my experience, I have found that with highly transactional partitioned tables the SWITCH operation can get blocked or cause blocking itself. This is due to the ALTER TABLE…SWITCH operation requiring a schema modify lock on both the source and target tables.
To get around this potential blocking issue I always set a timeout before any switch operation so that if the ALTER TABLE…SWITCH does start to cause blocking it will only be for as long as the timeout. I will then re-issue the ALTER TABLE…SWITCH statement repeatedly with the timeout until the operation goes through successfully. In this way the partition maintenance task will not interfere with the OLTP function of the database:
In the example below I set a 30 second timeout for the SWITCH to complete. If it timeouts I will repeat until it completes successfully.
SET LOCK_TIMEOUT 30000 ALTER TABLE myPartionedTable SWITCH PARTITION 2 TO SwitchTable
Msg 1222, Sev 16, State 56, Line 1 : Lock request time out period exceeded
Myth 6: Altering a partition function is a metadata only operation
In practice you may find out that a MERGE or SPLIT operation may take much longer than the few seconds expected. Altering a partition function is an offline operation and can also result in movement of data on disk and so become extremely resource intensive.
As long as the 2 partitions you are MERGEing together are empty then there will be no data movement and it will be a metadata only operation. If you have a sliding window and you are MERGEing the oldest 2 partitions together then a rule to follow is to always make sure both partitions are empty (SWITCHed OUT) before you MERGE.
To avoid or minimize data movement when SPLITing a partition function always ensure that you know beforehand how many rows are in the underlying partition that is being SPLIT and how many rows would fall on each side of the new boundary. Armed with this information you should be able to determine beforehand the amount of data movement to expect depending on whether you have defined your partition function using RANGE RIGHT or LEFT.
Be aware that more than one table or index can reside on the same partition scheme or use the same partition function. When you run ALTER PARTITION FUNCTION it will affect all of these tables and indexes in a single transaction.
Myth 7: Partitioned tables improve query performance
If your query is written in such a way that it can read only the partitions it needs the data from then you will get partition elimination and therefore an equivalent performance improvement. If your query does not join or filter on the partition key then there will be no improvement in performance over an unpartitioned table i.e. no partition elimination. In fact, a query that hits a partitioned table has the potential to be even slower than an unpartitioned table even if both tables have the same index defined. This is due to the fact that each partition in a partitioned table is actually its own b-tree which means that a partitioned index seek will need to do one seek per partition as opposed to one seek per table for an unpartitioned index seek.
Both tables below have a nonclustered index defined on the commodity column. The index on table tblPartitioned has been created on the partition scheme to align it with the clustered index but as we can see from the below this causes each partition to be scanned because the partition key is actually on a different column.
select count(*) from tblPartitioned where commodity = 'BOFRB' select count(*) from tblUnPartitioned where commodity = 'BOFRB'
----------- 371 Table 'tblPartitioned'. Scan count 54, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. ----------- 371 Table 'tblUnPartitioned'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
The graphical query plan clearly shows the difference in cost between the two queries. The top partitioned table query

If we also filter on the partition key column we get the desired performance improvement over the equivalent query on the unpartitioned table. If you are partitioning tables in an existing database then its a good idea to test all your queries for performance. Don’t assume that once the data is partitioned that your queries will improve. Queries may need to be updated to include the new partition key in the where clause or join to take advantage of the performance benefits of partitioning.
Myth 8: Partitioned tables ease maintenance of VLDBs and Very Large Tables
Partitioning can be effectively used to break up a very large table into multiple partitions based on a column or partitioning key. However, there can be significant management overhead in maintaining partitioned tables. The features of partitioned tables that give you the ease of management can also conspire against you to make your maintenance a nightmare!
Thinking of each partition as its own table will help you understand how best to approach your maintenance. Index rebuilds can be quicker because you can rebuild just those partitions that you identify as being fragmented. Conversely, full partitioned Index rebuilds will take longer as each partition is its own b-tree.
Note that old style DBCC SHOWCONTIG command does not work for partitioned indexes. You need to familiarize yourself with the more powerful DMV sys.dm_db_index_physical_stats. This DMV returns fragmentation information at a partition level and provides you the necessary information to make a decision on which partitions require rebuilding or reorganizing.
-- to return fragmentation information on partitioned indexes SELECT object_name(a.object_id) AS object_name, a.index_id, b.name, b.type_desc, a.partition_number, a.avg_fragmentation_in_percent FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL , NULL, 'LIMITED') a JOIN sys.indexes b on a.object_id = b.object_id and a.index_id = b.index_id order by object_name(a.object_id), a.index_id, b.name, b.type_desc, a.partition_number
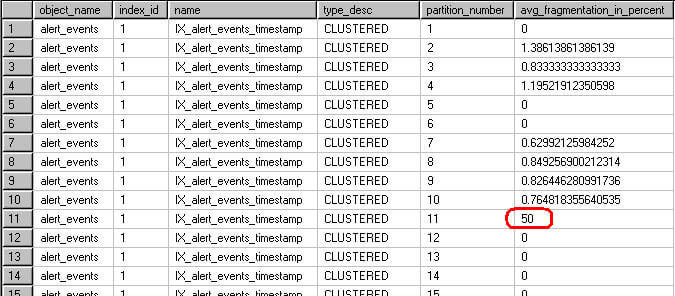
Once fragmentation has been identified we can rebuild the index statement for just that single partition:
--Rebuild only partition 11. ALTER INDEX IX_alert_events_timestamp ON dbo.alert_events REBUILD Partition = 11; GO
If you’re partitioning your data on a date field and you have a sliding window and you are only ever adding data to the right most partitions then you can save unnecessary overhead by not checking for fragmentation of older partitions where you already know they are not fragmented. sys.dm_db_index_physical_stats DMV allows you to specify a partition number. This greatly improves IO over full index scans and has the potential to shorten maintenance job durations.
Conclusion
Well designed database partitioning gives the DBA the opportunity to effectively work with massive amounts of data while at the same time providing the same level of performance as a small database. Having a sound partition management and maintenance plan will free up valuable DBA time to concentrate on more challenging problems and opportunities.
Next Steps
- I encourage you to read the chapters in Books On Line on Partitioning
- This tip from Atif provides good information on partitioning
- Handling Large SQL Server Tables with Data Partitioning
- Refer to these other tips about partitioning

Versatile SQL SERVER DBA with over 10 years’ experience managing critical production systems in large distributed enterprise environments. Specialise in SQL Server database administration and configuration on a large scale and the design of robust strategies for the maintenance and management of Very Large Databases primarily within the financial services industry. Have undertaken DBA work in 4 continents in the Banking, Gaming and Insurance sectors as well as 3 years with NYSE in London where I was the Lead SQL Server DBA for NYSE LIFFE™, the global derivatives business of the NYSE Euronext group. Currently living in Shanghai where I was recently asked by Microsoft to assist with the transition of an eCommerce operations team from US to China.

I believe this statement is incorrect:
You can’t restore a database with partitioning to an instance where partitioning is not supported. Important to bear this in mind. Any partition functions and schemes would need to be removed prior to backing up the database and restoring it to an edition that supports partitioning.
I believe the last sentence should end with “… an edition that does not support partitioning.”