Problem
As SQL Server DBAs or developers, we periodically are tasked with purging data from a very large table. However, typical data delete methods can cause issues with large transaction logs and contention especially when purging a production system. My recent challenge was to purge a log table that had over 650 million records and retain only the latest 1 million rows.
Solution
My goal is to build a strategic technique to purge a very large table, retaining only a fraction of the data. On a typical SQL Server, 1 million records is not a massive amount and with my recent production challenge it was only 1/650 of the current table size. To do a fast data purge we will utilize a little used feature in SQL Server, Partition Switching. Every table in SQL Server has at least 1 partition. In SQL Server you can quickly move an entire table from one table to another using the Alter Table Switch command. This leaves the original table fully intact, but empty. Then we can move the small sub set of data from the new table back to the original. I chose to use Partition Switch vs. renaming the table because I believe it is a less intrusive method, in which the object and index definitions do not get altered or destroyed during the operation. It is hard to know on many database systems the effects on an application of renaming objects or the effects of system cache.
Note: it is best to do this during off peak hours! According to Microsoft "Executing a SWITCH prevents new transaction from starting and might significantly affect the workload throughput and temporarily delay access to the underlying table."
Note: In this scenario the source table is not referenced by any foreign keys. If other tables reference the source table in a foreign key you will have a multi-table scenario which will have to be handled as to not break referential integrity. This article is meant for a simple scenario such as large log tables without foreign key constraints.
SQL Server Fast Delete from Large Table Demo
In this demo we will create a starting table and populate it with sample data. Then create an identical ‘switch’ table including indexes. Next, we will move the records to the new table using ALTER TABLE SWITCH command. Show that the record move (very quickly) and the original table is empty. After that we will move a small set of data back to the original table. Last drop the un-needed switch table.
Review the requirement and restrictions for SWITCH at Microsoft: https://docs.microsoft.com/en-us/sql/t-sql/statements/alter-table-transact-sql?view=sql-server-2017
Step 1: Create a Test Table
For this step we will create a test table: dbo.Test1.
CREATE TABLE [dbo].[Test1] (
Col1_id INT IDENTITY(1,1),
Col2_D DATETIME DEFAULT GETDATE(),
Col3_C NCHAR(20) DEFAULT 'My test desc!',
Col4_T NVARCHAR(MAX) DEFAULT REPLICATE('0123456789', 100)
);
GO
Step 2: Load Test Data
For this limited example we will only load 5000 rows and create 2 indexes. This also works for tables with millions of records.
--2. Load Test Data
SET NOCOUNT ON;
INSERT [dbo].[Test1] (Col2_D, Col3_C, Col4_T)
VALUES (DEFAULT, 'My test desc!', DEFAULT);
GO 5000
--Check it.
SELECT top 10 * FROM [dbo].[Test1];
SELECT COUNT(*) As 'Test1' FROM [dbo].[Test1];
GO
--Create Indexes
CREATE CLUSTERED INDEX [ClusteredIndex_Test1_Col2_D] ON [dbo].[Test1]
([Col2_D] ASC)
GO
CREATE UNIQUE NONCLUSTERED INDEX [NonClusteredIndex_Test1_Col1_ID] ON [dbo].[Test1]
([Col1_id] ASC)
GO
The image below shows example results and 5000 rows loaded.

Step 3: Create a Duplicate Table
Create a duplicate with new names for the table and indexes. You might script the original table from SSMS and do a find and replace on the table names. Be sure to script all table attributes and indexes. You do not need to include Foreign Keys in the switch table!
--3. Now let's duplicate the original schema and change the table and index names
CREATE TABLE [dbo].[Test1_SWITCH] (
Col1_ID INT IDENTITY(1,1),
Col2_D DATETIME DEFAULT GETDATE(),
Col3_C NCHAR(20) DEFAULT 'My test desc!',
Col4_T NVARCHAR(MAX) DEFAULT REPLICATE('0123456789', 201)
);
CREATE CLUSTERED INDEX [ClusteredIndex_Test1_SWITCH_Col2_D] ON [dbo].[Test1_SWITCH]
([Col2_D] ASC)
GO
CREATE UNIQUE NONCLUSTERED INDEX [NonClusteredIndex_Test1_SWITCH_Col1_ID] ON [dbo].[Test1_SWITCH]
([Col1_id] ASC)
GO
--Check it
SELECT COUNT(*) AS 'Test1' FROM [dbo].[Test1];
SELECT COUNT(*) AS 'Test1_SWITCH' FROM [dbo].[Test1_SWITCH];
The image below shows 5000 rows in the original table and 0 rows in the new table.
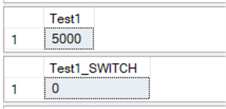
Step 4: The SWITCH!
Run the Alter Table SWITCH command and check the counts.
--4. Switch the data to a new table
ALTER TABLE [dbo].[Test1] SWITCH to [dbo].[Test1_SWITCH];
SELECT COUNT(*) AS 'Test1' FROM [dbo].[Test1];
SELECT COUNT(*) AS 'Test1_SWITCH' FROM [dbo].[Test1_SWITCH];
Voilà! The records quickly moved to the new table and the original table is now empty!
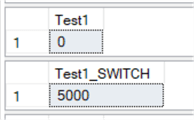
Step 5: Move Back!
Now we can move the small set of records back to the original table. In this case I have a table column that has an auto incrementing field, so we must use IDENTITY_INSERT to keep these values. This may not be the same in your real-world scenario.
--5. Now we can load the small subset of data back to the table.
SET NOCOUNT ON;
SET IDENTITY_INSERT [dbo].[Test1] ON;
INSERT dbo.Test1 (Col1_ID, Col2_D, Col3_C, Col4_T)
SELECT Col1_ID, Col2_D, Col3_C, Col4_T FROM [dbo].[Test1_SWITCH] WHERE Col1_ID <= 1000;
SET IDENTITY_INSERT [dbo].[Test1] OFF;
SELECT COUNT(*) AS 'Test1' FROM [dbo].[Test1];
SELECT COUNT(*) AS 'Test1_SWITCH' FROM [dbo].[Test1_SWITCH];
The results show 1000 rows back in the original table.
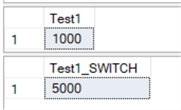
Step 6: Eliminate the Original Data!
Let drop the switch table that is no longer needed. Note the DROP writes a lot less to the transaction log versus DELETEs when done in mass amounts!
--6. Finally drop the newly created switch table.
DROP TABLE [dbo].[Test1_SWITCH];
Last: Clean Up the Demo
For this demo we are done with the original table, so go ahead and delete it.
--X. Clean Up the Demo
DROP TABLE [dbo].[Test1]
Wrap up of how to delete millions of records in SQL Server
This concludes this demo. Obviously, your production situation with be significantly greater than this 5000-row demo. If you find yourself in a situation where you need to purge a very large table, consider this technique to optimize the run time and minimize transaction log growth. Remember to target off peak hours to avoid contention. Also, be sure to test in a lab prior to running in production. Most important, be sure you have a recoverable backup before running any data purges in production!
Additional Thoughts
- You could use this technique to implement Sliding Partitions which would enable you to drop a partition rather than doing deletes going forward. (https://www.mssqltips.com/sqlservertip/5296/implementation-of-sliding-window-partitioning-in-sql-server-to-purge-data)
- You can also use this technique in conjunction with changes to the cluster key or introducing a cluster index if the table is a heap.
Next Steps
- This works for both the Standard Edition and Enterprise editions of SQL Server starting with SQL Server 2005.
- You may also want to rebuild your indexes on the table after you load the data back into the table.
- Read

Jim Evans is an IT professional who has worked with SQL Server since 1995. He has a passion for SQL Servers and working with the people who utilize it. As a C++ programmer early in his career he was mentored to learn T-SQL with optimizing for performance always a goal. He has supported many corporate business units and application, taken part in designing many databases, managed DBAs, BI Developer and Data Management teams. He is always up for a challenge, embraces new features and functionalities as they are rolled out and enjoys sharing his knowledge. When not working on SQL Server he has spends time coaching youth sports, coaching in a disability softball league and volunteering with Black Dagger Military Hunt Club providing outdoor activities for veterans.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2022 | Author Contender – 2021 | Rookie Contender – 2019



This only works if you don’t have foreign keys to other tables….