Problem
Some companies are reluctant to move to Microsoft Azure SQL Database since it is thought that code might need to be rewritten because not all database engine features are supported. For instance, a company with many SQL Server Agent Jobs may not want to rewrite those jobs as PowerShell Runbooks using Azure Automation. Azure SQL database is attractive since the service does all the database management. However, not all versions support the full functionality of the database engine. Is it possible to get the best of both worlds?
Solution
Microsoft announced the general availability of Azure SQL Database, Managed Instance edition, on 1 October 2018. This cloud version of the database engine is the most compatible with the on-premises SQL Server database version. That said, it allows companies to migrate workloads to the cloud with fewer coding changes. Today, we will discuss deploying the service via the Azure Portal. One service feature is that it is disconnected from the public internet by default and has its own virtual network (v-net). Therefore, we must deploy a virtual machine and peer it to the existing network to access the database engine from SQL Server Management Studio (SSMS). We will focus on the General-Purpose edition of the service and how to configure the database for performance.
Business Problem
Our manager has asked us to learn how to deploy, configure and test the managed instance version of Azure SQL Database using the General-Purpose edition. I will not go over the details of calculating the prime numbers from 1 to 5 million using 20 different batch command shells running T-SQL in parallel. Please see my previous article, Going Serverless with Azure SQL Database, that has the details for that task. This test (stored procedure) is a computationally-heavy operation. We want to create a database schema and execute the tests for different database file configurations.
Service Deployment
The image below shows the deployment of an Azure SQL Managed Instance named svr4asqlmi to the resource group called rg4asqlmi. The general-purpose server currently has eight virtual cores, 256 GB of storage, geo-redundant backups, and mixed security authentication. Click the “Configure Managed Instance” hyperlink to make changes to the hardware configuration.

The Compute + Storage configuration panel in the Azure Portal allows the designer to customize the service. First, we can select the service tier: general-purpose or business-critical. Second, we can select the hardware generation of the service. Finally, we can choose the starting number of virtual cores and disk space. Choosing newer hardware generation, a larger number of cores, or larger storage space all result in higher monthly charges for the service. The image below shows the configuration changed to 4 cores using generation 5 hardware and 128 GB of storage.

Like all deployments, Microsoft asks you to confirm your settings before deploying the service. Since the service deployment might take up to six hours, it is important to ensure the configuration is correct. The image below shows the settings we chose using the last panels.
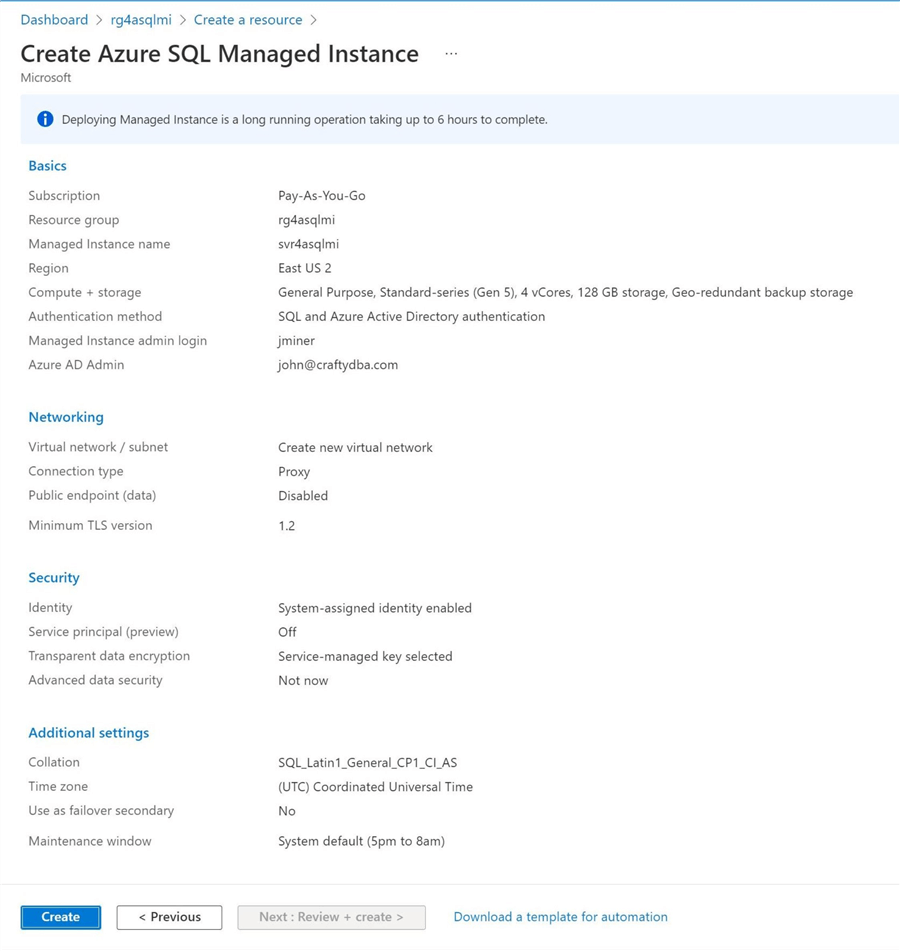
The deployment overview panel in the Azure Portal allows you to monitor the progress of the deployment.
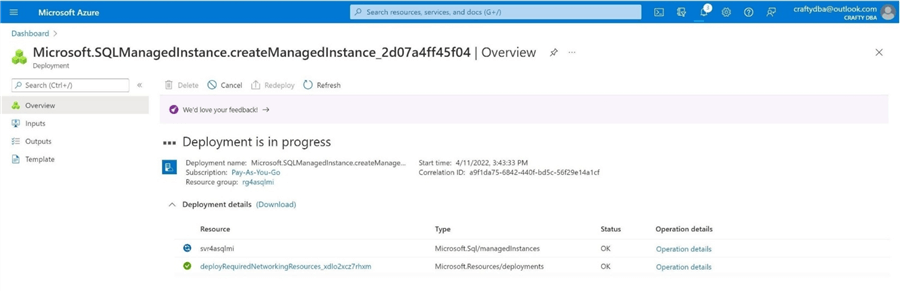
Eventually, the deployment will complete. The image below shows the successful deployment of the service.

The overview panel shows that the service is online, but databases still need to be created. The most important information on this web page is the fully qualified hostname. We need this URL when connecting to the logical server using SQL Server Management Studio.

To summarize, the deployment of Azure SQL Managed Instance is relatively easy from the Azure Portal. Remember: It might take several hours to deploy the service.
Azure Virtual Machine
To gain access to the newly created Azure SQL Managed Instance, we need to have a jump server (box). The image below shows a remote desktop connection to the virtual machine named vm4tips2022q1 using a local administrator account named jminer.
After making a successful terminal connection to the virtual machine, the SSMS software was downloaded and installed. The screenshot below shows a connection to the Azure SQL Managed Instance using the standard security account I created during the deployment.

The connection to the server was unsuccessful. Currently, there is no network pathway between the jump server and the managed instance.
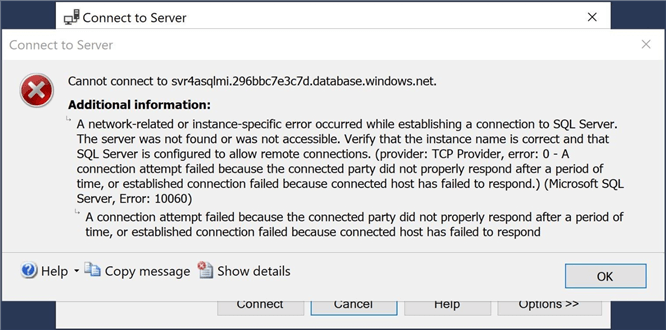
By default, Azure SQL Managed Instance is secure with no public internet connection and a locked-down virtual network. We need to peer the virtual network of the managed instance with the virtual network of the jump server.
Peering Virtual Networks
I usually start my investigation by looking at the configurations of both virtual networks. The screenshot below shows that the v-net for the managed instance has the public endpoint disabled. You can always enable this endpoint for a test if you are in a pinch. However, it is best practice to keep this feature disabled.
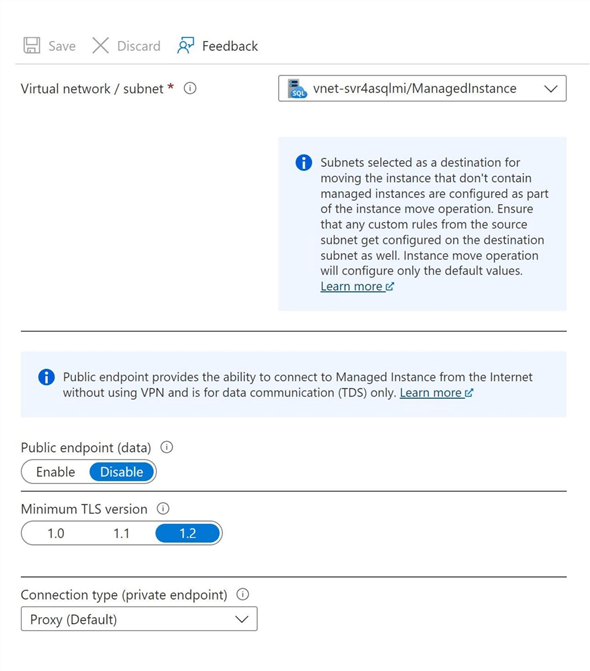
The image below shows the name of the network and subnet for the managed instance.
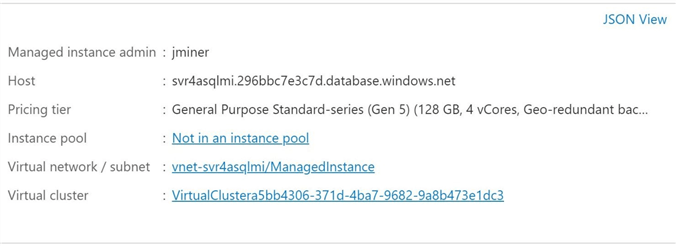
The image below shows the name of the network and subnet for the jump server running Windows Server 2019 Datacenter.
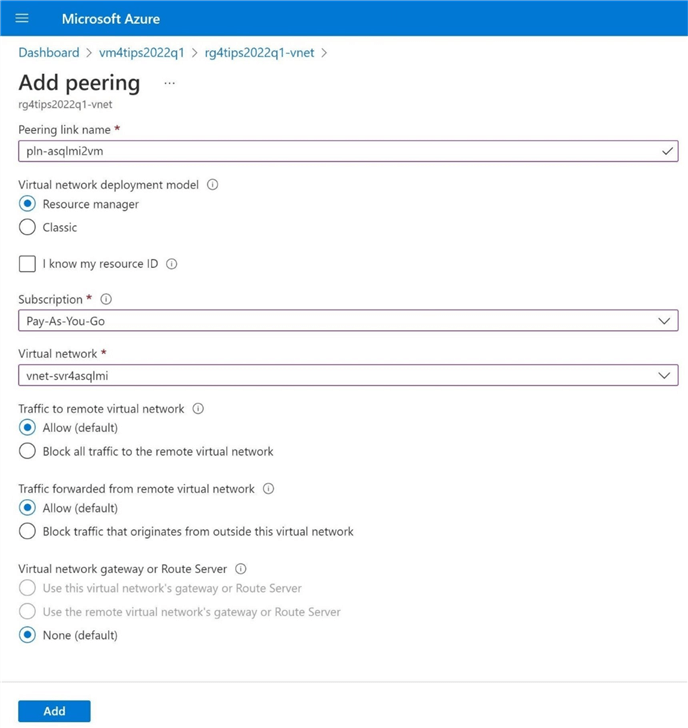
Because we do not have access to change the network settings for managed instances, we need to add peering from the jump server virtual network. The image below shows a peering link between the two networks. Please allow all traffic to flow to and from the remote network.
Lastly, verify that the peering status turns to connected on the new link.

In a nutshell, when deploying from the Azure Portal without a prebuilt virtual network design in place, we will end up with several virtual networks. One can peer these networks together so traffic can flow from one Azure service to another. A better way to deploy objects is to use ARM templates that reference a prebuilt virtual network with defined subnets.
Math Database
The purpose of this database is to calculate all prime numbers between 1 and 5 million. Please see my previous tip, Going Serverless with Azure SQL Database, that has the details of the database. The image below shows the successful deployment of the database.

If we look at the file configuration of the database, we can see very small file sizes for both the data and log files. Note: A filestream file has been deployed even though we used a simple CREATE DATABASE statement.
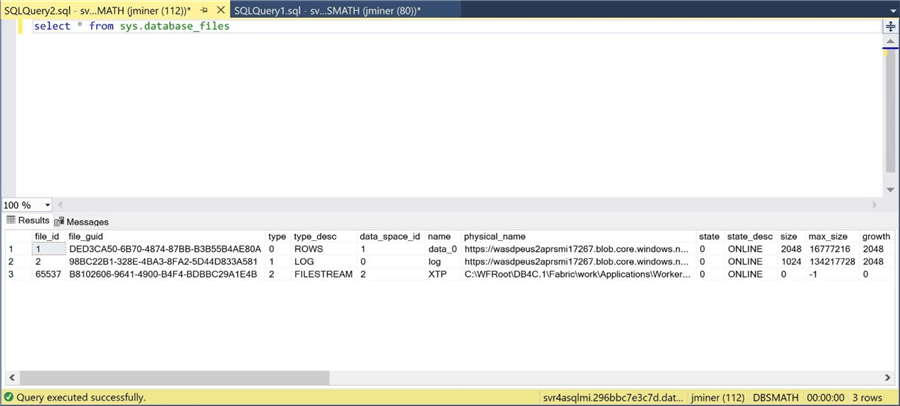
To refresh the memory, a batch file called the stored procedure to calculate prime numbers 20 times with different start and end parameters. The sp_who2 command shows 10 sessions running in parallel.
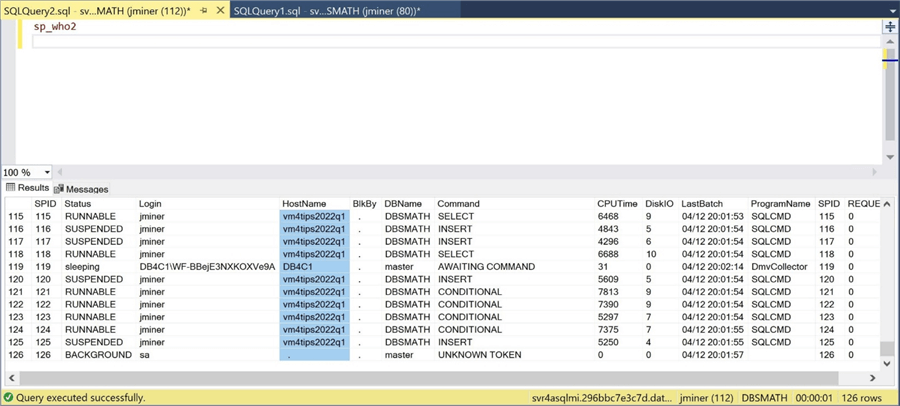
We can look at the performance monitor on the jump box while the batch files execute. The database server (managed instance) does all the computational and insertion work, while the jump server uses a very low resource level.
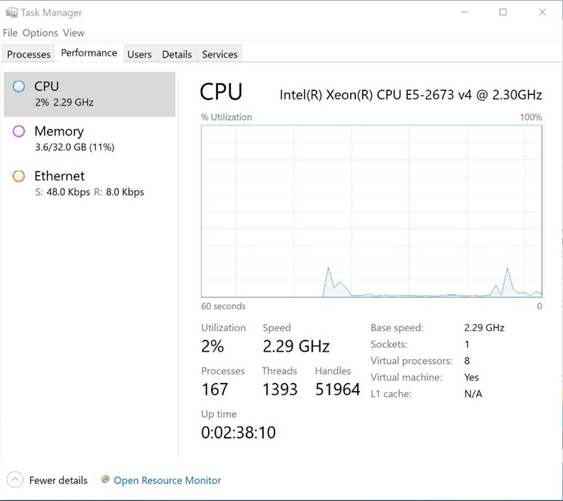
We can use the time stamp on the prime number records to calculate the start time, end time, elapsed time, and total records found. It took 585 seconds to find all the prime numbers.
There are always ways to change the configuration of the server or database to increase performance. Azure SQL Managed Instance is no different. In the next section, we will talk about how to make our database go faster.
File Size Matters
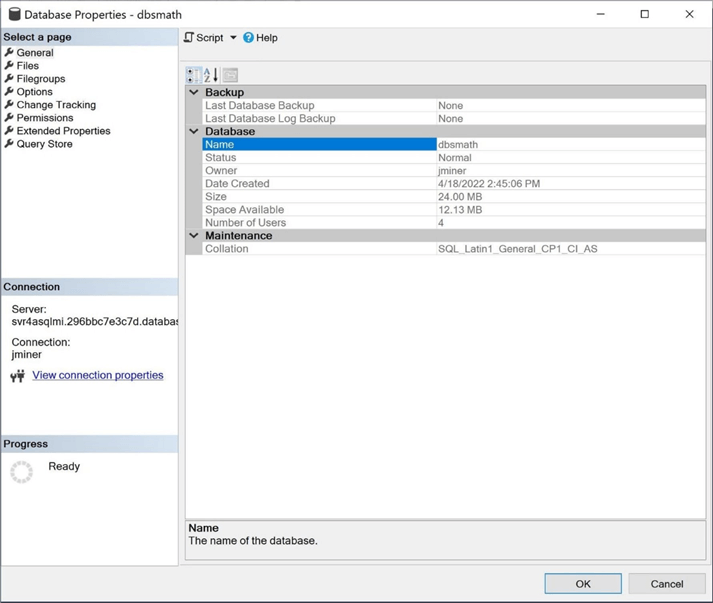
The image below shows that the final size of the database after execution of the batch file is 24 MB.
Many of the services in Azure cloud are throttled by design. Since Azure SQL Database and all its variations are dependent upon remote disk, we can look at the IOPS given the size of the disk or file. Any file less than 64 GB will only have 120 IOPS. To make our database go faster, we need to increase data and log file sizes. Unlike Azure SQL database, Azure SQL Managed Instance allows us to change the size of the database files.
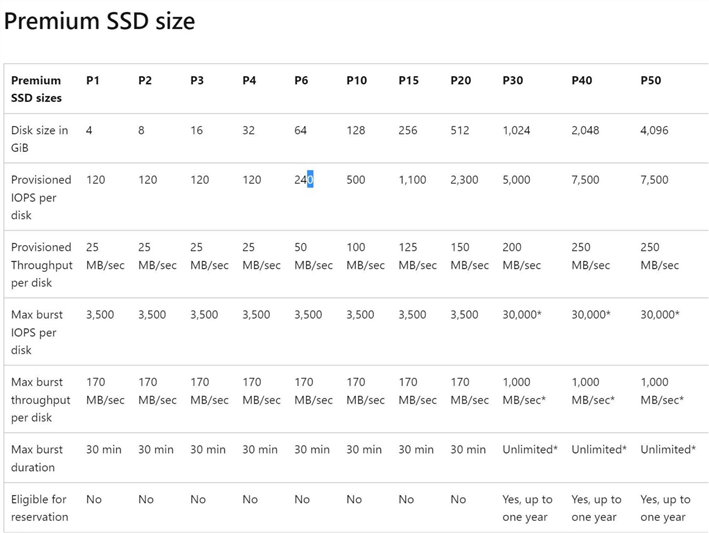
The image below shows data file and log file have been increased to 64 GB. In short, we are doubling the IOPS for both the data and log files.

Looking at the general page for the database named dbsmath, we can see 128 GB allocated for the database. However, we are using only a fraction of that space.
The control card table keeps track of the starting value of each call to the stored procedure. During each stored procedure call, only 250000 numbers are searched for prime numbers.

Did doubling the IOPS of the database files reduce the execution time by 50%? No, it did not. However, there was a 42.58% decrease in time spent doing the same processing. There is some overhead not being accounted for in the processing.

It is very important to plan out data and log file sizes ahead of time for the General-Purpose service tier of Azure SQL Managed Instance. The larger the file, the higher the IOPS value. As for the Business-Critical tier, it uses high-speed disks local to the compute that are not restricted by file size but restricted by core count. Please see my previous tip, Business Critical Tier of Azure SQL Services, on the Business-Critical tier of Azure SQL Services.
Summary
If your company has been procrastinating on moving SQL Server workloads to Azure because manpower hours will be needed for coding changes, I recommend checking out the Managed Instance version of Azure SQL database. This version is the most backward compatible with on-premises deployments.
The manual deployment of Azure SQL Managed Instance is relatively easy from the Azure Portal. However, you will need at least one jump box peered to the database network. A better design is to plan and deploy the network and sub-nets ahead of time. This will eliminate network peering.
In other versions of the service, there is no control over the size of the files. However, that has changed with Azure SQL Managed Instance. It is really important with the General-Purpose service tier—the larger the database files, the faster the IOPS.
I hope you liked this article. Next time, I will talk about two ways to audit your managed instance.
Next Steps
- Check out these other Azure articles.

John Miner is a Senior Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
He has over thirty years of data processing experience, and his architecture expertise encompasses all phases of the software project life cycle, including design, development, implementation, and maintenance of systems.
His credentials include undergraduate and graduate degrees in Computer Science from the University of Rhode Island. Also, he has earned certificates from Microsoft for Database Administration (MCDBA), System Administration (MCSA), Data Management & Analytics (MCSE), Data Science (MPP), Databricks Certified, and Fabric Certified.
John has been recognized with the Microsoft MVP award nine times for his outstanding contributions to the Data Platform community.
When he is not busy talking to local user groups or writing blog entries on new technology, he spends time with his wife and daughter enjoying outdoor activities. Some of John’s hobbies include wood working projects, crafting a good beer and playing a game of chess.
- MSSQLTips Awards: Author of the Year – 2019, 2022, 2023 | Champion (100+tips) – 2023